O víkendu 11. a 12. května lze navštívit Maker Faire Prague, festival plný workshopů, interaktivních činností a především nadšených a zvídavých lidí.
Byl vydán Fedora Asahi Remix 40, tj. linuxová distribuce pro Apple Silicon vycházející z Fedora Linuxu 40.
Představena byla služba Raspberry Pi Connect usnadňující vzdálený grafický přístup k vašim Raspberry Pi z webového prohlížeče. Odkudkoli. Zdarma. Zatím v beta verzi. Detaily v dokumentaci.
Byla vydána verze R14.1.2 desktopového prostředí Trinity Desktop Environment (TDE, fork KDE 3.5). Přehled novinek v poznámkách k vydání, podrobnosti v seznamu změn.
Dnešním dnem lze již také v Česku nakupovat na Google Store (telefony a sluchátka Google Pixel).
Apple představil (keynote) iPad Pro s čipem Apple M4, předělaný iPad Air ve dvou velikostech a nový Apple Pencil Pro.
Richard Biener oznámil vydání verze 14.1 (14.1.0) kolekce kompilátorů pro různé programovací jazyky GCC (GNU Compiler Collection). Jedná se o první stabilní verzi řady 14. Přehled změn, nových vlastností a oprav a aktualizovaná dokumentace na stránkách projektu. Některé zdrojové kódy, které bylo možné přeložit s předchozími verzemi GCC, bude nutné upravit.
Free Software Foundation zveřejnila ocenění Free Software Awards za rok 2023. Vybráni byli Bruno Haible za dlouhodobé příspěvky a správu knihovny Gnulib, nováček Nick Logozzo za front-end Parabolic pro yt-dlp a tým Mission logiciels libres francouzského státu za nasazování svobodného softwaru do praxe.
Před 10 lety Microsoft dokončil akvizici divize mobilních telefonů společnosti Nokia a pod značkou Microsoft Mobile ji zanedlouho pohřbil.
Fedora 40 release party v Praze proběhne v pátek 17. května od 18:30 v prostorách společnosti Etnetera Core na adrese Jankovcova 1037/49, Praha 7. Součástí bude program kratších přednášek o novinkách ve Fedoře.
Pokud jste pouze překladatel, není nutné znát všechny metody úpravy zdrojového kódu. Spíše musíte znát několik nástrojů pro práci s překlady a jak to celé funguje. Překladatelská část bude počítat se standardní složkou po.
Jedna z možností, které u překladu programu mohou nastat, je, že do vašeho jazyka ještě program nebyl přeložen. V tomto případě je nutné vygenerovat šablonu pro překlad a tu pak přeložit. Vlezte si proto v terminálu do složky po (nachází se ve složce se zdrojovým kódem programu a soubory jako Makefile.am a configure.ac).
cd po
A vygenerujeme si novou šablonu (.pot soubor) – k tomu slouží program intltool-update:
intltool-update -p
Parametr -p řekne programu, aby vygeneroval pouze .pot šablonu. Měl by se tam vytvořit soubor nazevprogramu.pot. Ten si otevřete v textovém editoru a upravte podle části „Testujeme“ ve vývojářské části.
Po úpravách jej přejmenujte na cs.po (pokud překládáte do češtiny). Teď je soubor připraven k překladu. Pro další překlad budete potřebovat nějaký překladatelský nástroj. Jak už bylo zmíněno ve vývojářské části, dva nejlepší jsou POEdit a KBabel (jeden je pro Gtk+, druhý pro Qt/KDE). Já doporučuji nainstalovat POedit. Po instalaci si jej spusťte. Zeptá se vás na určité údaje, vyplňte je, budou se zaznamenávat do překladu. Potom si ním už můžete otevřít váš cs.po. Rozhraní je velice jednoduché a nemyslím, že by s ním měl mít někdo problémy. Další věci už popíše následující obrázek:
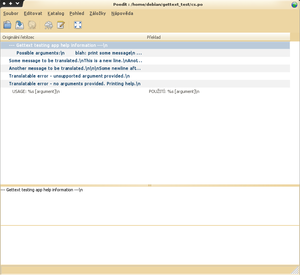
Lišta menu nahoře:
Dále můžete vidět toolbar (nástrojovou lištu) a pod ním seznam přeložených/nepřeložených/starých řetězců. Ty se barevně odlišují:
Pod seznamem jsou dvě pole. To horní je původní řetězec. Překlad tedy probíhá tak, že pomocí Alt+C zkopírujete horní do spodního a spodní přeložíte. Až bude vše přeloženo, uložte soubor. Pokud budete chtít svůj překlad později aktualizovat, vygenerujte si nový .pot pomocí intltool-update a z menu Katalog vyberte Aktualizovat z POT souboru.
Nyní, když máte přeloženo, zbývá upravit soubor LINGUAS ve složce po – vypadá nějak takhle:
fr it km pl
Prostě kódy zemí oddělené mezerami. Kódy MUSÍ být seřazeny podle abecedy. Upravte si soubor, aby vypadal takto:
cs fr it km pl
Jeho obsah závisí na počtu překladů. Pokud program ještě nebyl překládán, je prázdný. Tím by byla práce hotova.
Pokud program využívá jiný systém, jako třeba vlastní Makefile, pak vám intltool-update nebude fungovat a pro vytvoření POT souboru budete muset použít xgettext:
xgettext --keyword=_ --keyword=N_ --keyword=D_ --keyword=DN_ *.c -o program.pot
Při překladu postupujte stejně, ale systém skladování po souborů a jejich instalace se může lišit, podle Makefile.
Pokud je program psán v jazyce Python, místo xgettext použijte pygettext:
pygettext --keyword=_ --keyword=N_ --keyword=D_ --keyword=DN_ *.py -o program.pot
Programy, které se chovají stejně jako volby v POEditu, ale jsou do příkazové řádky. Často mají parametr -D(--directory), který určuje složku, kde se má hledat vstupní soubor(y).
Použití:
msgfmt cs.po -o myapp.mo # vytvoří z cs.po myapp.mo
Použití:
msginit -i my.pot -o my.po # vytvoří z my.pot my.po
Použití:
msgmerge -U my.po my.pot # aktualizuje my.po z my.pot
Použití:
msgunfmt myapp.mo -o cs.po # udělá z myapp.mo soubor cs.po
Použití:
msgattrib --translated cs.po # vypíše přeložené řetězce
Použití:
msgcat one.po two.po -o three.po # sloučí one.po a two.po do souboru three.po
Použití:
msgcmp my.po program.pot # porovná my.po a program.pot
Použití:
msgcomm one.po two.po # porovná dva po soubory
Použití:
msgconf --to-code=utf-8 -o utf.po cp1250.po # převede cs1250.po do utf-8 kódování a výsledek zapíše do utf.po
Použití:
msgen my.pot -o en.po # vyplní pot šablonu
Použití:
msgexec -i my.po cat # vypíše přeložené řetězce + hlavičku .po souboru (řádky jako language-team atd.)
Použití:
msgfilter -i en.po sed -e 's/error/success/g' # nahradí v překladu všechna slova „error“ za „success“
Použití:
msggrep --msgstr -F -e "error" en.po # vypíše všechny přeložené řetězce, které obsahují slovo „error“; # pokud nahradíte --msgstr s --msgid, tak vypíše z předloh, # pokud nahradíte -F za -E, můžete zadat regulární výraz
Použití:
msguniq -o unified.po my.po # sloučí duplicitní řetězce v my.po a uloží jako unified.po
Návod se blíží ke konci.. pokud potřebujete další informace, zde je kompletní manuál k gettextu:
http:#www.gnu.org/software/gettext/manual/gettext.htmlV článku se bohužel nedalo popsat vše, ale alespoň určitý základ a nejdůležitější věci nutné pro správu překladů jsem popsal. Při psaní článku jsem čerpal z výše uvedeného odkazu a vlastních zkušeností (většinou pokus-omyl). Na další věci se také můžete ptát v diskusi. Kompletní projekt jak se standardním Makefile, tak s autotools je přiložen k článku.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 20.1.2010 07:08
Jan Drábek | skóre: 41
| blog: Tartar
| Brno
20.1.2010 07:08
Jan Drábek | skóre: 41
| blog: Tartar
| Brno

Soubor uložte jako gettexttest.po a nepokoušejte se jej překládat.Proc ne??? Ja to vzdycky otevren ve vimu a prekladal jsem. Co je na tom za problem?
Nejenom kódování, ale také jméno posledního překladatele, časovou značku poslední úpravy překladu.
Na druhou stranu musím říct, že já mám univerzální Makefile, který tohle (a spoustu jiných věcí jako odeslání překladu robotovi) za mě dělá a používám taky vim. Grafické nástroje mě neoslovili (asi protože mám zkušenost jen s příšerným linguistem).
pybabel extract -F babel.cfg -o app.pot app pybabel update -i app.pot -d . -D app -l sk
Gettext umí podle klíčových slov hlídat syntaxi mezi msgid a msgstr. Například printf(3) escapovací sekvence:
#: ../src/aosd/aosd_ui.c:242 #, c-format msgid "monitor %i" msgstr "monitoru %i"
Nevíte, jestli lze ve zdrojovém kódu vyznačit, že daný řetězec není formátovací printf řetězec?
V jednom programu je použito něco jako _("100% during") a xgettext takovému msgid přidává příznak c-format, což je samozřejmě špatně. Kontrolní mechanismy pak křičí, že v překladu nesedí formátovací sekvence kolem procentítka. A mně nebaví opakovaně odmazávat příznak c-format.
Čekal bych, že gettext něco takového bude umět, protože zrovna tak umí extrahovat kontextové komentáře zdrojového kódu ohledně překladu (často se používá na upozornění překladatelů programátorem, že určité slovo v hlášce je lexikál nebo vlastní jméno).
20.1.2010 19:39
Jan Drábek | skóre: 41
| blog: Tartar
| Brno
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 20.1.2010 17:14
20.1.2010 17:14
 20.1.2010 19:05
20.1.2010 19:05