pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Denise Dumas poodhalila plán vývoje Red Hat Enterprise Linuxu. V rozhovoru pro TechTarget uvedla například, že v připravovaném Red Hat Enterprise Linuxu 7 bude výchozím grafickým uživatelským rozhraním GNOME Classic Mode a výchozím souborovým systémem pro boot, root a uživatelská data bude XFS. Plán vývoje a připravované novinky byly prezentovány také na konferenci Red Hat Summit 2013. Přednášky jsou k dispozici například na YouTube (Red Hat Enterprise Linux Roadmap: 1. část a 2. část).
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
GNOME Classic Mode? To jsou mi novinky. 
Ale jo, třeba už nás ti nahoře i vyslyšeli v tom, že by se Gnome 3 asi špatně prodával do míst, kde je teď Gnome 2.
 14.6.2013 16:34
pavlix | skóre: 54
| blog: pavlix
14.6.2013 16:34
pavlix | skóre: 54
| blog: pavlix
Denise Dumas říká, že to musí být opravdu těžké pro lidi od GNOME, kteří milují moderní rozhraní.Denise je v tomto ohledu velmi tolerantní a milá. Nicméně nikdo nechce od Gnomáků, aby přestali pracovat na svém moderním rozhraní, jen zde zřejmě Red Hat prosazuje své korporátní zájmy, když tlačí své vlastní placené vývojáře do údržby classic mode.
16.6.2013 14:43
pavlix | skóre: 54
| blog: pavlix
 17.6.2013 10:56
Tomáš Bžatek | skóre: 29
| Brno
17.6.2013 10:56
Tomáš Bžatek | skóre: 29
| Brno
Dalsi haters diskuze. Vetsina tech core Gnomaku pracuje v RH temer od zacatku projektu.
17.6.2013 11:59
pavlix | skóre: 54
| blog: pavlix
 14.6.2013 16:49
Sešívaný | skóre: 23
| Brno
14.6.2013 16:49
Sešívaný | skóre: 23
| Brno
RHEL 5, 6 i 7hej, 3 a 4 ještě nejsou mrtvé!

 15.6.2013 17:22
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
17.6.2013 10:58
Tomáš Bžatek | skóre: 29
| Brno
15.6.2013 17:22
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
17.6.2013 10:58
Tomáš Bžatek | skóre: 29
| Brno
btrfs jsem zrovna v sobotu vykopal pryc. Tak pomaly FS jsem dlouho nevidel (na 3.9.5 kernelu).
Ta pomalost by sa snad este nejak dala prezit, pri najmensom je tam aspon nadej, ze sa to zlepsi. Osobne mi pride horsie, ze si implementuje vsetko sam (lvm, raid a pod.) -- novy zdroj bugov. Tiez moc nechapem ako je mozne, ze mu nieco take prechadza. Obvzlast, ked si spomeniem ako na to bolo nadavane v pripade reiser 4, ktory tak riesil len komprimaciu a kompresiu (tam to paradoxne bolo podla mna omnoho viac pochopitelne, kedze na to vo VFS nebola podpora).
PS: Ak ma niekto lepsie informacie a v btrfs sa to vsetko riesi skutocne cez VFS, tak sa rad necham poucit, ale pride mi to nepravdepodobne s prihliadnutim na to, ze maju vlastnu implementaciu lvm aj raid (vyvoj btrfs sledujem len velmi okrajovo).
15.6.2013 17:21
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
a ma vyrazne vyssiu rychlost zapisu a citania nez ostatne FS.Nejaka cisla by byla? Zrovna o tomhle jako duvodu bych pochyboval, stejne jako nasazeni "poslednej dobe prepisaneho" file systemu.
15.6.2013 19:34
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Metadata-heavy workloads can end up changing the same directory block many times in a short period; each of those changes generates a record that must be written to the journal. That is the source of the huge journal traffic. The solution to the problem is simple in concept: delay the journal updates and combine changes to the same block into a single entry.
The actual delayed logging technique was mostly stolen from the ext3 filesystem. Since that algorithm is known to work, a lot less time was required to prove that it would work well for XFS as well. Along with its performance benefits, this change resulted in a net reduction in code.
One thing that was not required was any sort of on-disk format change - though that may be in the works in the future for other reasons.
Delayed logging is the big change, but far from the only one. The log space reservation fast path is a very hot path in XFS; it is now lockless, though the slow path still requires a global lock at this point. The asynchronous metadata writeback code was creating badly scattered I/O, reducing performance considerably. Now metadata writeback is delayed and sorted prior to writing out.
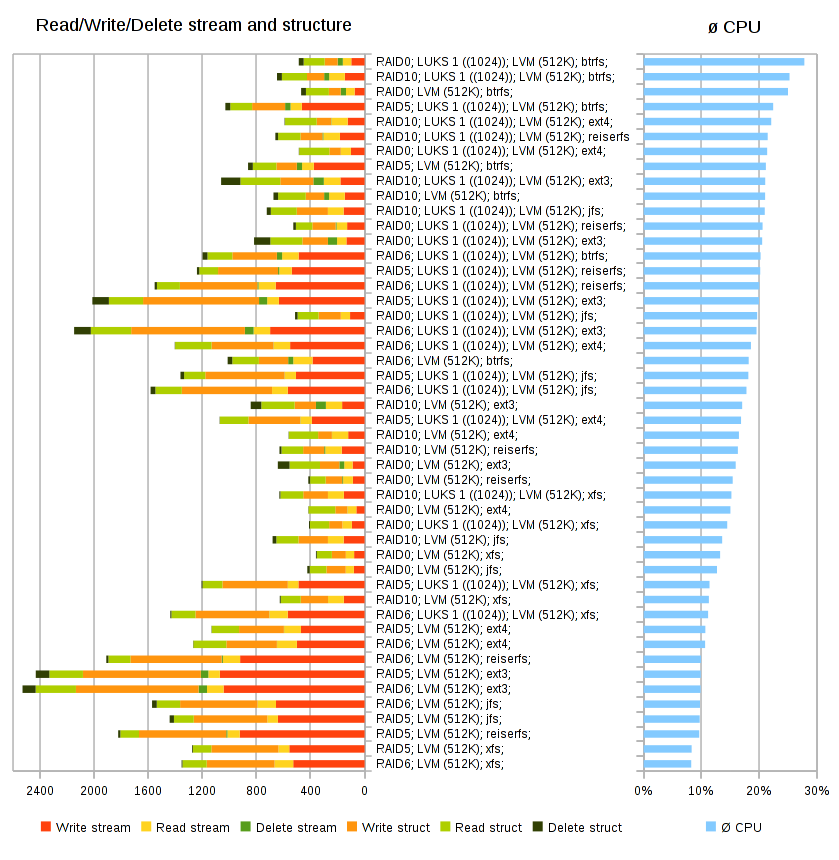
So how does XFS scale now? For one or two threads, XFS is still slightly slower than ext4, but it scales linearly up to eight threads, while ext4 gets worse, and btrfs gets a lot worse.
But the big challenge for the future is in the area of reliability; that may require some significant changes in the XFS filesystem.
Ext4, instead, suffers from architectural scalability issues. According to Dave's results, it is not the fastest filesystem anymore. There are few plans for reliability improvements, and its on-disk format is showing its age. Ext4 will struggle to support the storage demands of the near future.
Ext4, Dave said, is suffering from architectural deficiencies - using bitmaps for space tracking, in particular - that are typical of an 80's era filesystem.Posledni bod mohu potvrdit. Bitmapy setri pamet, ale z hlediska performance a soubezneho pristupu je nocni mura.
 “.
15.6.2013 19:34
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
17.6.2013 12:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
“.
15.6.2013 19:34
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
17.6.2013 12:20
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
rpm -q --changelog kernel naznačuje, že ...
17.6.2013 20:14
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Asi najdolezitejsia vec z hladiska vykonu (delayed logging) tam je od RHEL 6.2.
17.6.2013 20:17
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Myslim, ze takmer vsetky patche z 3.2 tam uz budu + celkom podstatna cast z 3.4 (a pokial ide o opravy chyb/vylepsenia vykonu nevyzadujuce vyraznejsie backporty, tak aj zmeny z novsich jadier). Detailnejsie by na to vedel odpovedat Dave Chinner, ktory stoji za asi vsetkymi vacsimi zmenami v xfs v rhel6
btw: Pre zaujemcov o detaily ohladom xfs (ohladom jeho vyvoja, pripadne pokial s nim mate nejaky problem, ktory chcete aj riesit) odporucam xfs mailing list.
17.6.2013 20:19
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
XFS v zásadě obsadil čelo, nicméně rozdíly jsou velmi malé a dost záleží na čem „leží“.Ony ty malé rozdíly při opravdu velmi velkém nasazení zase tak malé nejsou
.
A k prohlášení bych přidal: „XFS je dlouhodobě odzkoušený, nenáročný(, nerezervující si prostor) a »jednoduchý« FS - tudíž: »super volba«Na to jednoduchý není afaik dost uvozovek.
Nicméně je až s podivem, že i přes tu irixovou emulační vrstvu to běhá tak dobře.
17.6.2013 12:19
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
IBM ma JFS2.
V Linuxu je JFS2, stejnějako v AIX. To, že se JFS2 poprvé objevil v OS/2 Warp Server, je jen shoda okolností. Původní JFS1 AFAIK de facto na ničem jiném než na AIX fungovat ani nemohl.
17.6.2013 12:15
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
, v každém případě problém s ním nikdy nebyl. Ale ten noťas byl výkonostní křáp, proto jsem tak šachoval a na normální stroje dávam vždy osvědčený ext4.
...a nehrozí u něj ten problém, jako u XFS, kde když je rozepsaný soubor a vypne se počítač, tak se přepíše nulama.
Velmi zjednodusene a zle interpretovane. Nedostatocne podmienky.
Co sa v skutocnosti (zjednodusene) deje: Z dovodu poziadaviek na rozumny vykon fs sa data nezapisuju okamzite pri ich vytvoreni (nie, okamzity zapis skutocne nik nechce pre kazde IO; ak to aplikacia potrebuje, tak je tu fsync a fdatasync), ale az ked je to pre fs vhodne (aby sa nezapisovali zbytocne data o velkosti mensej ako je velkost bloku a pod. dovody). Dalej sa data hlaviciek suborov (nazov, lokacia, velkost a pod.) nezapisuju zaroven so skutocnymi datami suboru (dovodom je opat vykon). Vysledkom je existencia prazdnych suborov (hlavicka bola zapisana, data suboru nie). Nieco podobne sa deje vo vsetkych file systemoch, akurat ext3 pouziva hack, ktory vyvolava flush kazdych 5 sekund a ext3 spolu s ext4 hadzu podobne null subory do lost+found, takze ich nie je vidno a uzivatel si tak casto ani nevsimne, ze o nejake data prisiel (co je uprimne snad este horsie).
Boli, samozrejme, v danej oblasti aj bugy (a je mozne, ze este stale su), ale v poslednej dobe sa tomu vyvojari celkom dost venovali a celkom vela chyb bolo opravenych.
Dalsim dovodom podobneho spravania je hlupy hw (nie nutne vadny, skutocne hlupy). Velka vacsina diskov a raid poli ma vlastnu cache. Problem je, ze niektore disky hlasia data ako zapisane v momente, ked sa data dostanu do cache. Dalej niektore z tych diskov nemaju zalozne napajanie a teda v momente, ked vypadne prud su data, ktore boli v cache, stratene. S tymto sa nedokaze uz vysporiadat uplne ziadny fs (pozadovat, aby fs pracoval s tym, ze mu disk klame je absurdne).
17.6.2013 20:23
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
ext3 spolu s ext4 hadzu podobne null subory do lost+found, takze ich nie je vidno a uzivatel si tak casto ani nevsimne, ze o nejake data prisiel (co je uprimne snad este horsie).To tedy je ...
17.6.2013 20:31
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Nejaka poznamka je k tomu asi zde .... ?...a nehrozí u něj ten problém, jako u XFS, kde když je rozepsaný soubor a vypne se počítač, tak se přepíše nulama.Velmi zjednodusene a zle interpretovane.
Dalej niektore z tych diskov nemaju zalozne napajanieTohle v době superkondenzátorů a drahých disků fakt nechápu.
Ani ja moc, ale zevraj to robia aj niektore drahsie diskove polia (alternativne moze dany zalozny zdroj prist casom o svoju kapacitu...). Zmysel by to davalo jedine ak sa tam apriori predpoklada UPS a potom dany zalozny zdroj energie len zbytocne navysuje cenu, akokolvek nejde o nejak vyraznu polozku.
18.6.2013 12:33
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
To by ale museli být „speciální“ zdroje asi označené třeba „servevrové bez grafiky ma 250W“.U PC by to v praxi znamenalo mit dualni zdroj, v podstate integrovanou malou UPS; troufam si trvdit, ze v pro vetsinu lidi by bylo reseni standardni PSU + UPS lepsi a levnejsi cesta.
U PC by to v praxi znamenalo mit dualni zdroj, v podstate integrovanou malou UPS; troufam si trvdit, ze v pro vetsinu lidi by bylo reseni standardni PSU + UPS lepsi a levnejsi cesta.Jak moc velký problém by bylo mít baterii superkondenzátorů na stejnosměrné části zdroje? Přijde mi, že velmi krátké výpadky napětí (probliknutí světel, restart tiskáren, ...) zdroje zvládají pokrýt už roky, tak by snad nemusel být probém to o pár sekud protáhnout.
18.6.2013 18:25
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
o pár sekud protáhnout.Par sekund muze byt docela dost energie. Kondenzatory s velkou kapacitou a malym svodem [a treba i velkym Q-faktorem] nejsou levna zalezitost, i kdyz by to slo.
sync) neuvěřitelně dlouho (podle toho, co ukazovalo /proc/meminfo, to vycházelo na něco jako 3 MB/s). Výsledkem bylo, že např. po vypnutí virtuálu pod VMware Workstation následovala minutová prodleva, během které byl systém víceméně nepoužitelný. Do ReiserFS se mi moc nechtělo, ext3 se na velké filesystémy a soubory moc nehodí a ext4 tehdy ještě nebyl (nebo jen experimentální), tak jsem zkusil JFS a protože jsem s ním žádné vážnější problémy nezaznamenal, používám ho pro větší filesystémy dodnes.
17.6.2013 20:28
little.owl | skóre: 22
| blog: Messy_Nest
| Brighton/Praha
Jak tak vzpomínám, tak mi JFS přišel v nějaké běžné situaci pomalý
Občas mi přišlo, že trvá nezvykle dlouho smazání rozsáhlé adresářové struktury (zrojáky jádra, Firefoxu apod.). Ale ne vždy a všude.
14.6.2013 23:44
pavlix | skóre: 54
| blog: pavlix
 15.6.2013 12:10
xxxs | skóre: 25
| blog: vetvicky
15.6.2013 12:10
xxxs | skóre: 25
| blog: vetvicky
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz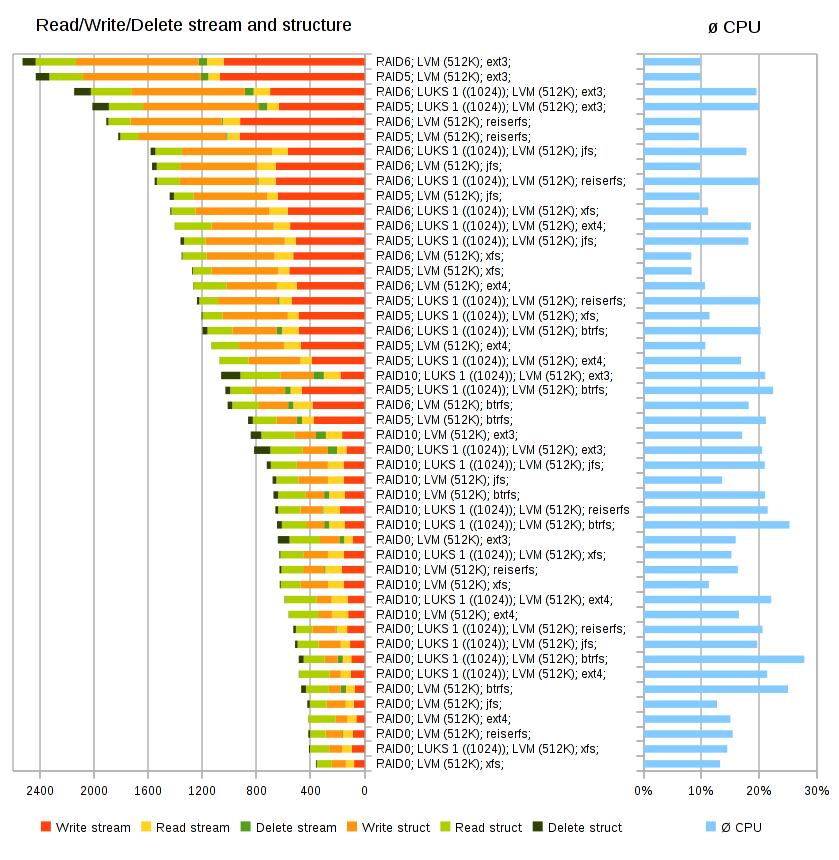{kind=link}
{kind=link}