Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Samba, svobodná implementace síťového protokolu SMB/CIFS, byla vydána ve verzích 4.24.5, 4.23.10 a 4.22.11. Řešeno je 6 zranitelností.
Přední technologické společnosti (Adobe, Cadence, Capital One, Cisco, Cloudera, Cloudflare, Cognition, CrowdStrike, Databricks, Dell Technologies, DoorDash, Elastic, HPE, Hugging Face, IBM, LangChain, Linux Foundation, Microsoft, NAVER, NetApp, Nous Research, NVIDIA, OpenClaw, Palantir, Palo Alto Networks, Red Hat, Reflection AI, Salesforce, SAP, ServiceNow, Siemens, SK Telecom, Snowflake, SpacexAI, Synopsys, Thinking
… více »Krabix.cz je online 3D konfigurátor krabiček pro 3D tisk s exportem do STL. Běží přímo v prohlížeči. Nic se neposílá na server.
Nadace Open Home Foundation spustila veřejnou preview verzi komunitní databáze zařízení pro Home Assistant. Má fungovat jako „Wikipedie pro chytrá zařízení".
Na stránce nového panelu Firefoxu přibudou nové widgety. Například denně aktualizována interaktivní křížovka.
PGSimCity (GitHub) je webová 3D vizualizace vnitřního fungování databázového systému PostgreSQL v podobě města. Vytvořena pomocí umělé inteligence.
UBports, nadace a komunita kolem Ubuntu pro telefony a tablety Ubuntu Touch, vydala Ubuntu Touch 24.04-2.0 a 24.04-1.4. Nová verze 24.04-2.0 již počítá s výřezy pro fotoaparát (notch) a zaoblenými rohy displeje. Webový prohlížeče Morph přešel z Chromia 87 na Chromium 134. Do shellu Lomiri byl přidán editor snímků obrazovky.
Odkazy


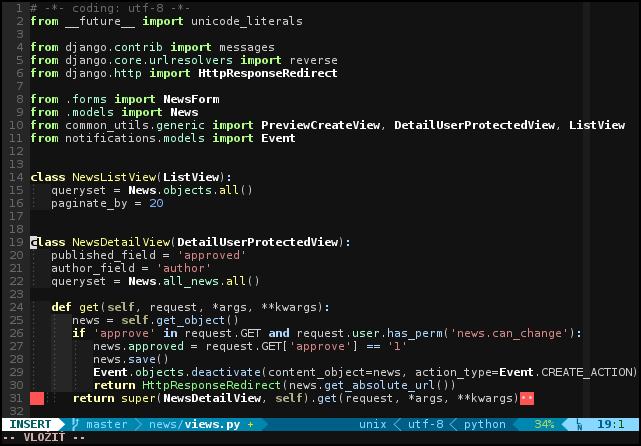
Konvencia PEP8 je medzi programátori notoricky známa. Omnoho menej je známy výrok samotného autora pythonu: I recommend always using tabs on Unix -- Guido.van.Rossum
V dobe keď vznikalo PEP8 mali niektoré editory skutočne problémy s tabulátormi. Celkom logicky sa v tej dobe zvolila konvencia, ktorá odporúčala používanie medzier.
Mnohí medzeristi (uznávam, to slovo som si vymyslel) argumentujú práve výrokom Guida z prezentácie Python Regrets o povolení oboch spôsobov odsadenia. Pravdu povediac nevidel som tú prezentáciu, neviem či sa týka možnosti odsadzovať tabulátorom, alebo ide len o zákaz miešania tabulátorov a medzier. Python 3 opravuje pár vecí z "Python Regrets", ale naďalej povoľuje tabulátory, takže predpokladám, že išlo len o miešanie (opravte ma ak sa mýlim).
Momentálne už nevidím problém s podporou editorov. Každý editor, s ktorým som sa stretol podporoval tabulátory korektne. Ak si pozriem hlasovanie na abclinuxu z roku 2005 a potom z 2012 vyzerá to, že počet používateľov tabulátora stúpa.
*Doplnené
Zaujímavá anketa k téme je napr. anketa o odsadzovaní neovimu.
Oficiálny priezkum na stackoverflow.
Sú jazyky, ktoré nedávajú na výber. Napríklad také Makefile, ktoré vyžaduje odsadenie tabulátorom. To dokážem pochopiť, do istej miery sa tým zjednoduší parser (nemusí sa rozpoznávať šírka odsadenia, alebo počítať znaky). Naopak také http://yaml.org/spec/current.html#id2519916 vyžaduje medzery, ale nevyžaduje striktný počet medzier a nevadí mu dokonca miešanie odsadenia 1 medzerou s odsadením 3 medzerami.
| Konvencia | Odsadenie |
|---|---|
| Google C++ Style Guide | 2 medzery |
| Webkit | 4 medzery |
| Mozilla | 2 medzery |
| Linux kernel | tabulátor |
| Python | 4 medzery |
| PHP | 4 medzery |
| Rust | 4 medzery |
| Ruby | 2 medzery |
| Javascript (NPM) | Tabs are better ... uses 2 spaces |
| Javascript (Google) | 2, 4 medzery, podľa počasia |
| Javascript Standard Style | 2 medzery |
| Java (oracle) | nešpecifikované |
Nevýhody tabulátorov sa v súčasnosti zredukovali na jednu drobnosť - zarovnanie. Taký rust napríklad zakazuje zarovnávanie, takže nebol by problém používať tabulátory.
Napriek stúpajúcej preferencii tabulátorov stále vznikajú editory, ktoré majú predvolené používanie medzier. Dokonca staré editory postupne vnucujú medzery namiesto tabulátorov. Novo vznikajúce konvencie tak isto preferujú medzery pred tabulátormi. Nie je čas na zmenu konvencií?
Ešte na koniec odbočím trochu od témy a skúsim tu zhrnúť pár rád pre používateľov tabov.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 21.11.2015 15:20
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
21.11.2015 15:20
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
 21.11.2015 15:21
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
21.11.2015 15:21
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Nič ak sú 3.
 21.11.2015 15:29
xkucf03 | skóre: 50
| blog: xkucf03
21.11.2015 15:32
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
21.11.2015 15:38
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
21.11.2015 15:29
xkucf03 | skóre: 50
| blog: xkucf03
21.11.2015 15:32
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
21.11.2015 15:38
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Taby odsadenie, medzery zarovnanie:
if (true) {
->fun(int a
->....int b)
}
Prevedené na medzery:
if (true) {
....fun(int a
........int b)
}
Prevedené na taby:
if (true) {
->fun(int a
-> ->int b)
}
Automatizovať sa dá len ak sa nepoužíva zarovnanie. Ja zarovnanie nemám rád hlavne kvôli bordelu vo VCS, takže na mojom kóde by to teoreticky šlo.
při editování v "cizím" editoru
Niekto sa rád hrabe v cudzom počítači, iný nie. Okrem toho nevidel som nikoho kto by mal nastavenú moju preferovanú šírku (3). Medzeristi proste väčšinou používajú 2 alebo 4 medzery, nevedia sa poriadne dohodnúť na šírke. S tabmi by žiaden problém nemali. Alebo poďme všetci používať 3 medzery, je to pekne v strede, dobre sa na to pozerá.
21.11.2015 15:42
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
21.11.2015 15:44
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Explicitne som to v blogu označil za zlé. Niektorí to robia a je to legitímny príklad v ktorom sa stratí sémantická hodnota pri konverzii.
co je proboha za problem preformatovani zautomatizovat?Jakože při otevření souboru mi to editor automaticky přeformátuje a při ukládání zase přeformátuje zpátky, aby to nedělalo bordel ve VCS? Tohle nějaký editor podporuje? S taby tohle vůbec není problém, ale tak proč dělat věci jednoduše, když to jde i mnohem složitěji, že

 23.11.2015 14:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.11.2015 14:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 23.11.2015 20:26
pavlix | skóre: 54
| blog: pavlix
24.11.2015 00:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.11.2015 17:38
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
21.11.2015 15:33
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
23.11.2015 20:26
pavlix | skóre: 54
| blog: pavlix
24.11.2015 00:48
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.11.2015 17:38
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
21.11.2015 15:33
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
Mezery nebo tabulátory, to není až tak podstatné. Podstatné je si nějaký styl zvolit a pak se ho důsledně držet. Dvěma věcem je třeba se ale zcela zásadně vyhnout: za prvé neuhlídání si nekonzistentního coding style; za druhé, když už se to stane, provádět samoúčelné tree-wide opravy formátování.
Ak si pozriem hlasovanie na abclinuxu z roku 2005 a potom z 2012 vyzerá to, že počet používateľov tabulátora stúpa.
Rok 2005 měl 365 dnů, rok 2012 už 366. Z toho je vidět, že délka roku průběžně roste.
Napríklad také Makefile, ktoré vyžaduje odsadenie tabulátorom. To dokážem pochopiť, do istej miery sa tým zjednoduší parser
I autor sám to později prohlásil za historický omyl - s nímž bohužel musíme dodnes žít. Jediné pozitivum je, že to zůstává jako odstrašující příklad pro další jazyky, že dávat whitespace syntaktický význam je zlo. Někteří se ale bohužel nepoučili.
Aby sa zabránilo prípadným problémom odporúčam mať zapnuté zobrazovanie bielych znakov a podľa možnosti aj zvýraznenie mixovania
Na to je triviální napsat si pre-commit hook, nevidím důvod, proč by s tím měl otravovat editor. Když píšu nebo prohlížím zdroják, zajímá mne zdroják, ne zvýraznění whitespace.
21.11.2015 15:43
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Na to je triviální napsat si pre-commit hook
Prečo každému vývojárovi do každého projektu pchať pre-commit hook keď si môže raz nastaviť editor a má to na všetky projekty?
Pokud by editor prováděl kontrolu jen např. při ukládání, šlo to vypnout a šlo by konfigurovat, jaké požadavky má kontrolovat, tak proč ne. Trvalé vykreslování značek je neskutečně otravné a rušivé. Zvýrazňování "špatných" míst je ještě horší.
Obávám se, že hlavní nedorozumění je, že vy se na to díváte z pozice člověka, který si píše svůj vlastní program od začátku do konce, takže je to on, kdo si definuje pravidla a je na něm, jestli a jak je dodržuje. Já se na to dívám z pozice člověka, který musí editovat zdrojáky z různých projektů, které mají různý coding style a mnohdy obsahují hodně míst, kde ten coding style z nějakého důvodu dodržen není, ale opravovat to by nadělalo víc škody než užitku. Když si takový zdroják otevřu v editoru nastaveném podle vašich představ, bude tam na mne každou chvíli někde svítit, co je špatně - a na to opravdu nejsem zvědavý, zvlášť pokud je mým úkolem ten cizí kód, který vidím poprvé, pochopit a najít v něm chybu.
21.11.2015 16:16
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ak prispievam do nejakého projektu používam štýl projektu. Ak si riešim projekt od začiatku riadim sa svojimi pravidlami.
Editor mi nehlási chyby ak je dodržané konzistentné odsadenie.
Editor mi nehlási chyby ak je dodržané konzistentné odsadenie.
Na tom obrázku máte zobrazené značky na všech řádcích. To je pro mne nepřijatelné. Předpokládám, že na řádcích, kde je odsazeno špatně, to bude něco výraznějšího, aby to na problém upzornilo. A teď si představte velký projekt, který existuje roky, přispívalo do něj mnoho různých lidí a během té doby se tu a tam objevila místa neodpovídající oficiálnímu stylu. Když je budete opravovat, budou vás ostatní vývojáři milovat, až jim každou chvíli "git blame" ukáže ty vaše úklidové commity. Když je tam necháte, bude vám váš úžasný editor neustále ukazovat "tady je něco špatně".
21.11.2015 16:37
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Zmiešané označenie je červeným.
21.11.2015 16:37
xkucf03 | skóre: 50
| blog: xkucf03
až jim každou chvíli "git blame" ukáže ty vaše úklidové commity
Souhlasím, že tohle je nepříjemné, ale beru to i jako nedostatek příkazu blame – stejný problém totiž nastane, když třeba někdo obalí blok kódu IFem nebo přidá odchytávání výjimky – kód je pořád stejný, ale Git jako jeho autora uvádí toho, kdo přidal if nebo try kolem.
Ideální verzovací systém (nebo samostatný „diff“ nástroj) by měl rozumět danému jazyku a měl by být schopný rozpoznat a hlásit změny typu: blok byl obalen IFem, metoda se přesunula z třídy A do třídy B nebo třeba proměnná se přejmenovala z x na y.
Iniciativě se meze nekladou. :-)
Jinak máte samozřejmě pravdu, ale je určitý rozdíl mezi tím, když se musím k původu daného kusu kódu prohrábávat skrz smysluplné commity (třeba to obalení podmínkou) a když je to přes dobře míněné, ale stejně otravné změny typu "v hlavičkových souborech nepoužívejte u funkcí extern" nebo "místo porovnání s NULL použijeme všude vykřičník" (a ne, nemyslím takhle :-) ). Commity pouze opravující formátování whitespace jsou ještě o stupeň dál.
21.11.2015 17:06
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
K tomu zobrazeniu značiek ... v ideálnom svete ich netreba. Lenže už som videl v zdrojákoch všeličo vrátane odsadenia 5. medzerami (dotyčný to kopíroval niekde z webového editoru, ktorý pri kopírovaní pridával jednu medzeru navyše). V takom prípade zobrazenie pomocných čiar (nemusia sa zobrazovať chyby, postačia pomocné čiary) zabráni zlému odsadeniu. Prirodzene v ideálnom svete by tam boli tabulátory a nikto by si nemusel robiť ťažkú hlavu s tým akú má šírku odsadenia iný programátor. Alebo všetci by mali odsadenie 3 medzery keď sa medzeristi nevedia dohodnúť či je správne číslo 2 alebo 4.
21.11.2015 17:28
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
V nových projektoch sú preferované skôr 2 medzery (rails, node, rôzne js blbosti ...)
Dĺžka riadkov bola kedysi relevantná, súčasné editory si poradia so soft wrap-om.
21.11.2015 17:40
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Všetci programátori majú rovnakú šírku monitora, rovnaký font, rovnako rozložené okná? Ak vadí pár znakov rozdiel v šírke tabulátora potom bude vadiť aj keď niekto bude mať väčší monitor, alebo nebodaj zmení font, alebo ešte horšie upgradne knižnicu, ktorá renderuje font a zrazu tam bude u každého znaku o 1 pixel viacej!
Ale vážne, píšem v pythone, mám vodiacu čiaru na 80 znakov, občas sa dostanem na 100 čo je smiešné číslo oproti tomu čo používajú ostatní. Ukážka typického kódu s dlhými riadkami:
class CommentedStatistics(Statistics):
def get_queryset(self):
return (apps.get_model('comments.Comment')
.objects
.filter(user=self.user, parent__isnull=False)
.values('content_type_id', 'object_id')
.annotate(max_pk=Max('pk'), date_field=Max('created')))
def get_graph_queryset(self):
return (apps.get_model('comments.Comment')
.objects
.filter(parent__isnull=False, user=self.user))
def get_list_queryset(self):
return (self.get_queryset()
.order_by('-max_pk')
.values('content_type_id', 'object_id', 'date_field'))
22.11.2015 21:18
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ukážka typického kódu s dlhými riadkami:Jako by ti něco bránilo si to rozdělit na víc výrazů. A vůbec, tohle dost smrdí javascriptem a těmi jeho nekonečnými vláčky volání metod.
22.11.2015 22:44
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Zvážili sme rôzne spôsoby zápisu zreťazených funkcií a tento najviac zodpovedal DRY a zároveň bol medzi vývojármi najobľúbenejší.
22.11.2015 23:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.11.2015 08:03
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
// swap a and b x = a a = b b = x
vs.
(a, b) = (b, a)
Používanie medzivýsledkov v miestach, kde to nespôsobí žiadnu pridanú hodnotu je v pythone bežne považované za antipattern. Takto by napríklad vyzeral môj kód s použitím medzivýsledkov:
class CommentedStatistics(Statistics):
def get_queryset(self):
commented = apps.get_model('comments.Comment').objects.all()
commented = commented.filter(user=self.user, parent__isnull=False)
commented = commented.values('content_type_id', 'object_id')
commented = commented.annotate(max_pk=Max('pk'), date_field=Max('created'))
return commented
def get_graph_queryset(self):
comments = apps.get_model('comments.Comment').objects.all()
comments = comments.filter(parent__isnull=False, user=self.user)
return comments
def get_list_queryset(self):
commented = self.get_queryset()
commented = commented.order_by('-max_pk')
commented = commented.values('content_type_id', 'object_id', 'date_field')
return commented
Tento spôsob si nielen vyžaduje viacej písania, ale ešte sa aj horšie sa číta. Asi 1/3 kódu je boilerplate (nenapadá ma teraz slovenský ekvivalent), ktorý nemá nič spoločné s funkčnosťou.
Spôsob, ktorý používam ja je medzi djangistami pomerne bežný. Nemyslím si, že by moc pripomínal javascript. Keď niekto používa jQuery (budiž, jeho problém) tak tam je zneužívanie zreťazených funkcií časté, ale že by to bola nejaká špecifická vec pre javascript si nemyslím.
Tento spôsob si nielen vyžaduje viacej písania, ale ešte sa aj horšie sa číta.
Názory jsou od toho, aby se různily.
23.11.2015 08:57
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
(a, b) = (b, a)vs.
a.swap(b)Co mi na tom vadí asi je, že přenášíš funkcionalitu jazyka do metod. Třeba ten filter.
23.11.2015 09:23
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Co mi na tom vadí asi je, že přenášíš funkcionalitu jazyka do metod. Třeba ten filter.
To mám akože písať dotazy ručne?
Tento malý súbor napríklad rieši kompletne generovanie štatistík a zoznamov príspevkov používateľov vrátane dát pre grafy tu s možnosťou stránkovania, filtrovania zoznamov podľa typu obsahu, filtrovanie podľa dátumu ...
Len pre zaujímavosť tu je pár SQL dotazov, ktoré to generuje:
SELECT
"article_article"."id",
"article_article"."created",
"article_article"."updated",
"article_article"."title",
"article_article"."slug",
"article_article"."pub_time",
"article_article"."published",
"article_article"."pub_time" AS "date_field"
FROM "article_article"
WHERE ("article_article"."published" = %s AND "article_article"."pub_time" <= %s AND "article_article"."author_id" = %s)
ORDER BY "date_field" DESC LIMIT 20;
... podobné pre fórum, blogy ...
pre grafy:
SELECT
django_datetime_trunc(\'month\', "article_article"."pub_time", %s) AS "time_value",
COUNT("article_article"."id") AS "aggregate"
FROM "article_article"
WHERE ("article_article"."published" = %s AND "article_article"."pub_time" <= %s AND "article_article"."author_id" = %s AND "article_article"."pub_time" >= %s AND "article_article"."pub_time" <= %s)
GROUP BY django_datetime_trunc(\'month\', "article_article"."pub_time", %s)
ORDER BY "time_value" ASC;
SELECT
django_datetime_trunc(\'day\', "article_article"."pub_time", %s) AS "time_value",
COUNT("article_article"."id") AS "aggregate"
FROM "article_article"
WHERE ("article_article"."published" = %s AND "article_article"."pub_time" <= %s AND "article_article"."author_id" = %s AND "article_article"."pub_time" >= %s AND "article_article"."pub_time" <= %s)
GROUP BY django_datetime_trunc(\'day\', "article_article"."pub_time", %s)
ORDER BY "time_value" ASC;
SELECT
django_datetime_trunc(\'month\', "blog_post"."pub_time", %s) AS "time_value",
COUNT("blog_post"."id") AS "aggregate"
FROM "blog_post" INNER JOIN "blog_blog" ON ( "blog_post"."blog_id" = "blog_blog"."id" ) WHERE ("blog_post"."pub_time" < %s AND "blog_blog"."author_id" = %s AND "blog_post"."pub_time" >= %s AND "blog_post"."pub_time" <= %s)
GROUP BY django_datetime_trunc(\'month\', "blog_post"."pub_time", %s)
ORDER BY "time_value" ASC;
...
Keby som to mal písať ručne tak sa 1. zbláznim a 2. zbláznim sa keď by som potreboval pridať nejakú podmienku (povedzme do blogov by som pridal is_draft a zrazu potrebujem do všetkých dotazov mimo adminu a zobrazenia vlastných blogov podmienku is_draft = false.
23.11.2015 10:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.11.2015 10:46
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ak existuje lepší postup rád si o ňom prečítam. Ja používam Django ORM a to má zreťazené volania funkcií. Ak si pozriem povedzme SQLAlchemy tak používa rovnaké zreťazenie (dokonca hneď keď otvorím dokumentáciu vidím zreťazenie bez medzivýsledkov). Väčšina ORM nie len pre python používa zreťazené funkcie.
Ak ide len o spôsob zápisu zreťazenia .. no vyskúšali sme ich viacero. Na tento som narazil na stack overflow a zatiaľ vyhovuje najviac (i keď podobnosť s tuple je zavádzajúca, ale spätné lomítka na konci tiež nevyzerali ktovie ako dobre).
23.11.2015 09:49
xkucf03 | skóre: 50
| blog: xkucf03
To (a, b) = (b, a) a a.swap(b) ale není ekvivalentní, ne?
Voláním metody na a nemůžu změnit, kam odkazuje proměnná a, ne? Můžu leda nastavit objektu a stejnou hodnotu (stejný vnitřní stav), jako má objekt pod proměnnou b. Kdežto ten kód se závorkami a rovnítkem prohodí to, kam proměnné a a b ukazují, ne?
23.11.2015 10:00
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
21.11.2015 17:30
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Len tak mimochodom dokonca google odporúča odsadzovať python dvoma medzerami.
 21.11.2015 19:26
Hans1024 | skóre: 5
| blog: hansovo
21.11.2015 19:26
Hans1024 | skóre: 5
| blog: hansovo
Myslis jako treba v Lispu?Ne, myslim proste fixni pocet sloupcu na uroven zanoreni. Pokud mam odsazeni 4 sloupce/uroven, a jsem na 5 urovni, tak mam celkove odsazeni 20 sloupcu, coz muze byt reprezentovano 2 taby a 4 mezery, 1 tab a 12 mezer ci rovnou 20 mezer (ci jine, jeste obskurnejsi varianty), to je vcelku jedno. Akorat je dobre mit kanonickou formu, aby reformatovani nevytvarelo sum. Lispova konvence (pokud tim myslime to same) mi take vadi, prijde mi, ze casto vede k zbytecne extremnimu odsazeni.
Na druhou stranu, jak rikas - podle me by mel byt tab s fixnim predpokladem 8 znakuSouhlasim. Resp presneji odsazeni na nejblizsi tabulacni pozici - nasobek 8.
osobne nastavuji vsechny editory na "tabs to spaces", tim se predejde nedorozumenim pri pouzivani tabulatoruOpravdu s taby nejake problemy jsou? Mozna u nejako siroce-multiplatformniho projektu. Ale pro bezne ucely je 8 znaku defacto standard a problemy s tim ma snad akorat jen ten, kdo si sam v editoru nastavil jinou hodnotu.
25.11.2015 20:13
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
25.11.2015 20:43
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
25.11.2015 23:15
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
25.11.2015 23:39
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
26.11.2015 00:00
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
26.11.2015 00:52
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
25.11.2015 20:49
xkucf03 | skóre: 50
| blog: xkucf03
8? Pro mne je standard 4. I když jsem dělal i na projektech, kde se odsazovalo na 2 nebo na těch 8. Ale vtip je právě v tom, že to nemusí být pevně dané a každý si to zobrazí, jak mu vyhovuje – tedy pokud se používají tabulátory. Jednoduše: 1 tabulátor = 1 úroveň odsazení.
Používat tabulátory a nutit lidi, aby si u nich nastavili nějakou fixní šířku mi přijde úplně zcestné – pak nemají moc výhod oproti mezerám (leda ty uspořené bajty zdrojáku).
Ale vtip je právě v tomOd navrharu ASCII to byl dobry vtip. Jeho pointu podtrhly textove editory, ktere se rozhodly nahrazovat taby mezerami, pokud mozno pokazde jinak. I kdyz asi na ten spolecny vtip Billa Gatese a Steva Jobse s CR/LF to nema..
Používat tabulátory a nutit lidi, aby si u nich nastavili nějakou fixní šířku mi přijde úplně zcestné – pak nemají moc výhod oproti mezerám (leda ty uspořené bajty zdrojáku).A ty mas na disku tak malo misto, ze potrebujes sporit u zdrojaku (i kdyz mozna jo, pokud pouzivas Javu.. :-P)? Tabulatory (jako znak) nemaji dnes zadne vyhody oproti mezeram - je to historicky artefakt, asi jako BEL nebo RS. Jinak editor si samozrejme muze (a taky to bezne delavaji) navazat na stisk tabulatoru (klavesy) jakoukoli akci.
I kdyz asi na ten spolecny vtip Billa Gatese a Steva Jobse s CR/LF to nema..
Ta idea oddělení carriage return a line feed coby dvou samostatných znaků je mnohem starší a ve své době dávala smysl. Windows ani nebyly první, kdo začal pro oddělení řádků v textových souborech používat kombinaci CRLF - koneckonců to předepisují třeba specifikace protokolů SMTP nebo HTTP. Kdybych měl Windows vytknout nějakou na hlavu postavenou volbu, které je (téměř) jedinečná, tak spíš UTF-16.
Ale lidstvo se nepoučilo, takže dneska zase máme BOM a editory, které ho cpou i do souborů kódovaných v UTF-8…
8? Pro mne je standard 4. I když jsem dělal i na projektech, kde se odsazovalo na 2 nebo na těch 8.Mluvim zde ciste o interpretaci znaku ASII 9, nikoliv o odsazeni pri programovani obecne. Ten je vicemene univerzalne pouzivan pro odsazeni na tabelacni pozice po 8 sloupcich. Zkus si textovy soubor s tabulatory vycatovat v terminalu nebo zobrazit treba ve webovem prohlizeci ci e-mailu. Nebo mas i terminal a webovy prohlizec prenastaven tak, aby tabulator (znak) odsazoval na 4 pozice? A neni nesmysl, aby textovy editor narozdil od zbytku systemu zobrazoval ten samy text jinak zformatovany? To je koneckoncu hlavni argument proti odsazovani pouze tabulatory - ty sve IDE muzes mit nastavene tak, aby chapalo znak tab ve zdrojovem kodu jako odsazeni po 4 sloupcich, ale zbytek sveta bude defaultne pouzivat 8, coz je pro ucely odsazovani ve zdrojovem kodu obvykle moc, takze nahodny clovek prohlizejici tvuj kod ho uvidi roztazeny a prekracujici delku radku.
A neni nesmysl, aby textovy editor narozdil od zbytku systemu zobrazoval ten samy text jinak zformatovany?Jak jinak zformátovaný? Změna délky tabu by neměl měnit formátování.
26.11.2015 00:08
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
8? Pro mne je standard 4.Přidávám se k těm, kdo používají 4 znaky. Samozřejmě, že terminál to zobrazí jinak, ale kdo čte zdrojáky v terminálu?
26.11.2015 10:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
26.11.2015 11:12
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Kernel používa tabulátor aj na zarovnávanie, bez nastavenia zobrazenia na 8 medzier je zdroják (presnejšie povedané zarovnané časti) rozhodený. Pri čítaní sa to tá prežiť, pri úprave nie.
26.11.2015 11:17
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
26.11.2015 11:38
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Majú presne definované ako má byť nastavený a pri správnom nastavení to nerobí problém ani keď niekto mixuje medzery a tabulátory. Nepáči sa mi to no je to jednoznačne definované a ja to rešpektujem. Lepšie než keď sa na začiatku vôbec nedohodne štýl a každý robí čo chce.
Přesně tak. I hloupý coding style je lepší než žádný coding style. Jsem v pokušení říct, že GNU styl (glibc) je výjimka, ale i to je pořád lepší, než když je každý kus zdrojáku formátovaný jinak podle toho, kdo ho psal a jak se zrovna vyspal.
Dodnes si nadávám, že když jsem se se rozhodl vzkřísit Twinkle, neprohnal jsem hned na začátku celý původní strom z posledního tarballu indentem nebo něčím podobným. Co se dá dělat, budiž mi to odstrašujícím příkladem pro případ, že se někdy dostanu do podobné situace znovu.
26.11.2015 11:58
kyknos | skóre: 18
| blog: Quid novi?
| Ranša Rosa
Ani na čtení to není nic moc, zvlášť u nějakých složitějších víceřádkových výrazů nebo podmínek.
Na druhou stranu, o delší než osmiznakové odsazování asi nestojí nikdo a limit 80 znaků na řádek se stále ve většině kódu dodržuje (kromě dlouhých stringových konstant), přestože vůči němu sílí odpor. Takže není moc důvod, proč by si člověk ty zdrojáky nemohl číst se správnou hodnotou odsazení.
Problém to je spíš tam, kde někdo kvůli přehlednosti preferuje větší odsazení než používá projekt a zdroják se s ním nevejde na terminál.
.
---" a začátkem vlastního patche) dostane do gitu, to není až tak překvapivé.
26.11.2015 10:14
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
26.11.2015 01:11
xkucf03 | skóre: 50
| blog: xkucf03
pokud si nastavis editor na tab = 4, tak si rozbijes formatovani u velkeho mnozstvi existujicich projektu
Za předpokladu, že ty tabulátory používají chybně. Kdyby se používal pro odsazení o jednu úroveň, zatímco pro zarování by se používaly mezery, tak by to fungovalo správně pro jakoukoli šířku tabulátoru.
Tabulátor jako „makro pro 8 mezer“ podle mého nemá smysl – to už je lepší tam naflákat přímo ty mezery.
zatímco pro zarování by se používaly mezeryI pro tabulky třeba s políčky o délce třeba 10+ znaků?
26.11.2015 06:30
pavlix | skóre: 54
| blog: pavlix
Za předpokladu, že ty tabulátory používají chybně.Jakýkoli jiný předpoklad je v kontextu linuxového vývoje chybný, Ondra už tu pár takových významných projektů jmenoval.
Tabulátor jako „makro pro 8 mezer“ podle mého nemá smysl – to už je lepší tam naflákat přímo ty mezery.O tom se tady snad nikdo nepře.
26.11.2015 10:16
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Tabulátor jako „makro pro 8 mezer“ podle mého nemá smysl – to už je lepší tam naflákat přímo ty mezery.On hlavně takhle nikdy nefungoval, protože se dynamicky dorovnává na zarovnání sloupce. Někdy tak má tři mezery a jindy osm.
Za předpokladu, že ty tabulátory používají chybně.Pokud si zadefinujeme 'chybne' jako 'jinak nez ty', tak ano. O zneuzivani tabu by se dalo mozna mluvit v pripade kombinovani tabu a mezer pro odsazeni (jak to defaultne dela napr. emacs), ale pouziti tabulatoru zaroven pro odsazovani a pro zarovnani je plne v souladu s tradicnim vyznamem, chovanim a uzitim tabulatoru. Ze to tobe nevyhovuje, je tvuj problem.
ale pouziti tabulatoru zaroven pro odsazovani a pro zarovnani je plne v souladu s tradicnim vyznamem, chovanim a uzitim tabulatoruTo imho není pravda. Používat pro zarovnání znak, který má z definice dynamickou šířku, prostě není dobrý nápad, pokud někdo chce, aby byl kód zarovnaný všude stejně. Ani v terminálu není ta šířka garantována, dá se dynamicky měnit, viz ESC H, CSI g et al.
21.11.2015 19:35
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Taby sa nemajú používať na zarovnanie.
Možnosť zarovnávať kód mi nechýba, kedysi som si myslel, že prispieva k čitateľnosti (sám som zarovnával a prestal som s tým).
Na zarovnávanie je pekná hračka - elastic tabstops. Len akosi to poriadne skoro nikto neimplementoval.
21.11.2015 20:15
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Elastic tabstops práve rieši diffy v prípade, že sa zmení dĺžka zarovnaných reťazcov. S medzerami sa musí meniť počet medzier na každom riadku. Elastic tabstops sú obyčajné taby (teda vždy 1 tab, o samotné zarovnanie do stĺpcov sa stará editor). Zobrazovanie v konzole / nástrojoch ako diff sa dá poriešiť, ale chýbajúcu podporu v IDE to nevyrieši.
Ano, taby se nemaji pouzivat na zarovnavani, ale to bud musite mit inteligentni editor, ktery zvoli spravne taby nebo mezery podle kontextu, nebo se stale hlidat (a sve kolegy) jak zarovnavate.Třeba v Qt Creatoru tohle afaik není problém... Vůbec mi to celkově nepřijde jako problém, zarovnává se typicky mnohem méně často než odsazuje.
21.11.2015 21:47
xkucf03 | skóre: 50
| blog: xkucf03
Nenařizuje. Spíš mi přijde, že převažují tabulátory. Na současném projektu máme dvě mezery, jinde to byly čtyři, nebo zase tabulátory. Když o tom rozhoduji já, tak tabulátory. Ve standardní knihovně to není jednotné, někde jsou tabulátory, někde čtyři mezery.
21.11.2015 22:08
pavlix | skóre: 54
| blog: pavlix
gboolean
nm_platform_link_get_driver_info (NMPlatform *self,
int ifindex,
char **out_driver_name,
char **out_driver_version,
char **out_fw_version)
{
Výše uvedený kousek je z NetworkManageru, který ve stylu následuje glib/gobject. V případě změny názvu funkce například na nm_platform_link_get_driver_details znamená změnu v následujících čtyřech řádcích, která (1) musí být provedena ručně nebo pomocí search&replace v bloku složeném z těch čtyř řádků a (2) projeví se v diffech a gitovské historii.
if (service && service[0])
{
char *c;
gaih_service.name = service;
gaih_service.num = strtoul (gaih_service.name, &c, 10);
if (*c != '\0')
»·······{
»······· if (hints->ai_flags & AI_NUMERICSERV)
»······· {
»······· __free_in6ai (in6ai);
»······· return EAI_NONAME;
»······· }
»······· gaih_service.num = -1;
»·······}
pservice = &gaih_service;
}
Tenhle kousek je naopak z glibc a představuje podle mě nejidiotštější možnou kombinaci použití tabulátorů a mezer. Formátování dává smysl pouze při pevně definované šířce tabulátorů a tudíž sdílí nevýhody obou přístupů. Nemluvě o tom, že tento styl disponuje dalšími debilitami jako je postupné dvojté odsazení kvůli jedné konstrukci (odsazená složená závorka pod ifem a následně odsazený i její obsah).
A abych se nedržel jenom céčka, pythonisti budou možná oponovat, že mají toto vyřešené, ale ani náhodou. Zatímco příkazy se v pythonu píšou většinou do řádků a odsazují podle příslušnosti k bloku, literály datových strukturu fungují stejně blbě jako v céčku.
def week_days():
return [
'Monday',
'Tuesday',
'Wednesday',
'Thursday',
'Friday']
Naštěstí lze poslední hranatou závorku odložit na další řádek a přidat nepovinnou čárku, čímž se seznam stane daleko lépe editovatelným (každý datový řádek je pak rovnocenný), ale i tak to má k dokonalosti ještě daleko.
A pak jsou tu takové klasiky jako céčkovský switch, který se sice používá na větvení na více větví kódu, ale ve skutečnosti neobsahuje bloky.
switch {
case 0:
do_something();
break;
default:
do_something_else();
}
A to nemluvím o různých XML, kde se whitespace považuje za strukturní nástroj i za data, ale tyto dvě věci nejsou udržovány v harmonii jako třeba u pythonu, takže jakákoli snaha napsat kód hezky prosakuje bohužel i do dat.
Mně z toho plyne jediná věc. Lidé prasí, protože prasit chtějí, protože je čistota struktury prostě nezajímá. Těch pár lidí se smyslem pro logickou strukturu a dokonalost to nezachrání a i ti se snaží vše přiohýbat svým zkušenostem a zvyklostem.
 21.11.2015 22:36
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
21.11.2015 22:36
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
nm_platform_link_get_driver_info (NMPlatform *self, int ifindex, char **out_driver_name, char **out_driver_ version, char **out_fw_version)
{
// code
}
nepokladám za pekné a aj pri svojom malom rozlíšení monitoru vidím celý riadok.
Občas používam aj takýto zápis ale to skôr v spojení s DB, tam býva aj veľký počet položiek:
nm_platform_link_get_driver_info (
NMPlatform *self,
int ifindex,
char **out_
driver_name,
char **out_driver_version,
char **out_fw_version
) {
// code
}
Pri takýchto zápisoch a použití tabulátorov nemám žiadny problém.
22.11.2015 08:45
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Používam prakticky rovnaký štýl. Ľudia majú často tendenciu zarovnávať to na otváraciu zátvorku, čo robí bordel vo VCS ak sa náhodou zmení názov funkcie (musí sa meniť celé zarovnanie), alebo nebodaj niekto refaktoruje kód automaticky a na x miestach sa mu rozbije zarovnanie. Podľa mňa je tento kód prakticky rovnako čitateľný ako kód zarovnaný nazátvorku. A ešte pozor problematické je len takéto zarovnávanie, ak niekto zarovnáva napríklad na znak = tak to nijako nepokazí odsadenie (to je len po prvý nebiely znak).
22.11.2015 09:35
pavlix | skóre: 54
| blog: pavlix
22.11.2015 09:42
pavlix | skóre: 54
| blog: pavlix
Ľudia majú často tendenciu zarovnávať to na otváraciu zátvorkuJak jsem psal, je to debilita, ale ve spoustě projektů se na tom trvá i pro nový kód.
A ešte pozor problematické je len takéto zarovnávanie, ak niekto zarovnáva napríklad na znak = tak to nijako nepokazí odsadenie (to je len po prvý nebiely znak).WTF?
22.11.2015 10:00
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Jak jsem psal, je to debilita, ale ve spoustě projektů se na tom trvá i pro nový kód.
Mnoho ľudí žije v minulosti. Práve preto sa v blogu zamýšľam, či nie je na čase trochu aktualizovať konvencie. Argumentovať dnes, že niekto povedal že x je lepšie než y je tak isto blbosť, hlavne ak niekto ťahá do siskusie Guida, ktorý má iný názor, ale podriadil sa väčšine.
| ->int a...... = 7; | ->int wtf.... = 6; | ->int odpoved = 42;
Odsadenie tabom mi neovplyvní zarovnanie na znak "=". Stačí dodržať jednoduché pravidlo: taby po prvý nebiely znak. Zvyšok môže byť zarovnaný, ale zarovnávať v takom prípade len medzerami (ale to je hádam samozrejmosť, predpokladám, že kto sa naučil programovať by sa mal naučiť ovládať aj editor).
22.11.2015 10:07
pavlix | skóre: 54
| blog: pavlix
--- a 2015-11-22 10:03:43.920460232 +0100 +++ b 2015-11-22 10:04:01.180460038 +0100 @@ -1,4 +1,5 @@ -alpha = 12 -beta = 78 -gamma = 25 -delta = 17 +alpha = 12 +beta = 78 +gamma = 25 +delta = 17 +epsilon = 1Triviální úprava vede zase na (1) rozbití diffů a (2) nutnost ruční editace, pokud člověk nemá nějaký specializovaný editor, který zrovna tohle umí. Přitom je to úplně zbytečné, člověk ty hodnoty bez problémů přečte i bez zarovnání.
--- a 2015-11-22 10:05:36.190458970 +0100 +++ b 2015-11-22 10:06:06.290458632 +0100 @@ -2,3 +2,4 @@ beta = 78 gamma = 25 delta = 17 +epsilon = 1Kvůli těmhle jalovým nápadů se pak člověk týdny hádá, jestli je jeho patch dostatečně minimální nebo měsíce čeká, než se někdo odhodlá reviewovat patch s padesáti změnami z nichž čtyři jsou funkční a čtyřicet šest je jen z důvodu debilního formátování.
22.11.2015 10:18
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Ja som to kedysi používal a potom som zistil čo za bordel mi to robí vo VCS. Zašiel som dokonca až do toho štádia keď do zoznamov, slovníkov ... dávam vždy (okrem javascriptu, niektoré browsery s tým majú problém) za posledný prvok oddeľovač aby sa pri pridaní položky nemenili 2 riadky.
Inak keď tak ľudia chcú zarovnávať nechápem prečo sa nerozšírilo napr. elastic tabstops. Implementačne je to jednoduché a rieši to krásne problém zo zarovnávaním bez toho aby to robilo problémy vo VCS.
22.11.2015 10:42
pavlix | skóre: 54
| blog: pavlix
Ja som to kedysi používal a potom som zistil čo za bordel mi to robí vo VCS. Zašiel som dokonca až do toho štádia keď do zoznamov, slovníkov ... dávam vždy (okrem javascriptu, niektoré browsery s tým majú problém) za posledný prvok oddeľovač aby sa pri pridaní položky nemenili 2 riadky.Tak. Celý princip oddělovače je u víceřádkových konstrukcí špatně. Viz třeba příkazy v Pascalu versus C.
function moje_funkce(a: integer; b: real)
begin
do_something;
do_something_else;
do_something_different
end
S oddělovači jsou při víceřádkovém zápisu pořád jenom nějaké problémy. Python naštěstí umožňuje nadbytečné čárky dle specifikace. Céčko myslím jen v konkrétních dialektech.
Ty elastic tab stops mi ale taky přijdou nedomyšlené. Na ty nejjednodušší účely to pomůže a bylo by fajn to vidět implementované, i když to nebude fungovat na to, jak se v současné době taby běžně používají. Problém ale vidím v tom, že se člověk bude muset zcela podřídit přesnému formátování a neprokládat související řádky ničím jiným, což u mezer nebo mixu nebyl problém.
I kdyby byly elastic tabs stoprocentním řešení, prosadit je by bylo na dlouhé lokte, ale vzhledem k tomu, že to tak není, to vidím dost bledě.
neprokládat související řádky ničím jiným, což u mezer nebo mixu nebyl problém.
jj, nefunguje to – v příloze je ukázka z jEditu.
Když je to proložené komentářem, tak to zarovnání stejně dost ztrácí smysl. Ale je fakt, že aspoň prázdné řádky by to tolerovat mohlo.
22.11.2015 12:31
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Elastické tabulátory nie sú strieorná guľka.
Ale je fakt, že aspoň prázdné řádky by to tolerovat mohlo.
To práve nesmie, neexistoval by spôsob ako rozdeliť skupiny, ktoré majú byť rovnako odsadené.
22.11.2015 10:34
xkucf03 | skóre: 50
| blog: xkucf03
Souhlasím, taky jsem proti zarovnávání123 – ovšem tím padá asi jediný argument pro použití mezer – pravidla jsou pak tak jednoduchá, že je dokáže dodržovat i polodementní opice (stačí si nastavit editor/IDE, aby klávesa TAB vkládala jeden tabulátor).
[1] když už potřebuji napsat každý parametr funkce nebo hodnotu v poli na jiný řádek, tak to odsadím o úroveň, nebudu to zarovnávat na nějaký znak nad tím
[2] zarovnávat na rovnítko sice může na první pohled vypadat dobře, ale kvůli verzovacím systémům je to zlo
[3] zajímavou alternativou jsou elastické tabulátory
22.11.2015 10:48
pavlix | skóre: 54
| blog: pavlix
ovšem tím padá asi jediný argument pro použití mezerTo se ale bavíme čistě hypoteticky, že. Realita je taková, že pro použití mezer bude vždy a za všech okolností platit ten jeden velký a zásadní důvod, že tím nevzniká takový bordel jako při mixování tabů a mezer. A vzhledem k tomu, že používání tabů nutně v části případů vede na jejich mixování s mezerami, jsi opět v háji.
22.11.2015 11:22
xkucf03 | skóre: 50
| blog: xkucf03
Realita je taková, že pro použití mezer bude vždy a za všech okolností platit ten jeden velký a zásadní důvod, že tím nevzniká takový bordel jako při mixování tabů a mezer.
O jakém mixování mluvíš? V předchozím komentáři jsme se shodli na tom, že zarovnávat se nebude. Bude se tedy jen odsazovat. Pak můžou nastat následující situace:
Když lidé nedodržují pravidla, bude to špatně ať nastavíš konvence tak nebo tak. Aktuální příklad z praxe: používáme odsazení pomocí mezer (to se mi nelíbí, ale respektuji to) a někdo tam pošle tabulátory – ničeho si nevšimne, protože u něj to vypadá stejně – a máme ve zdrojácích bordel. Závěr: konvence odsazovat mezerami problém neodstranila.
A vzhledem k tomu, že používání tabů nutně v části případů vede na jejich mixování s mezerami, jsi opět v háji.
Nutné je to jen při zarovnávání – pak je potřeba mít dobré IDE/editor nebo si s tím dát ruční práci. Pokud nezarovnáváš, tak k žádnému mixování nedochází.
22.11.2015 11:36
pavlix | skóre: 54
| blog: pavlix
O jakém mixování mluvíš?O tom, které se objevuje v reálných projektech bez ohledu na to, na čem se my shodnem.
Když lidé nedodržují pravidla, bude to špatně ať nastavíš konvence tak nebo tak.Opět perfektní použití čisté logiky bez ohledu na realitu. V jednoduchosti je síla. Nepoužívání tabů lze lehce vysvětlit i kontrolovat.
22.11.2015 11:57
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Nepoužívání tabů lze lehce vysvětlit i kontrolovat.
Dobre, dohodneme sa na nepoužívaní tabu. Čo ďalej. Každý si bude odsadzovať 2 medzerami? 4 medzerami? 8 medzerami? Rozoznáte rozdiel medzi 8 a 7 medzerami ak niekto povedzme zle skopíruje riadok? Ja rozdiel medzi 1 a 2 úrovňami odadenia spoznám ľahko ale rozdiel o 1/8 úrovne odsadenia nespoznám.
22.11.2015 13:51
pavlix | skóre: 54
| blog: pavlix
Dobre, dohodneme sa na nepoužívaní tabu. Čo ďalej. Každý si bude odsadzovať 2 medzerami? 4 medzerami? 8 medzerami?Ale já rozumím výhodám odsazování jediným znakem, který se roztáhne na několik pozic, psal jsem to už v prvním příspěvku.
Rozoznáte rozdiel medzi 8 a 7 medzerami ak niekto povedzme zle skopíruje riadok?Ano, poznám. Ale ve zdrojácích třeba glibc je vidět, že ho zjevně nepoznají všichni.
22.11.2015 13:49
xkucf03 | skóre: 50
| blog: xkucf03
Jak jsem psal výše – na problémy narazíš i když máš jako konvenci mezery. Mezery tedy nic neřeší. Tu konvenci respektuji jen kvůli tomu, že je s mezerami napsaná hromada kódu, přepsat ho nejde a nutit lidi v jednom týmu se přepínat mezi mezerami a tabulátory je taky nesmysl.
V jednoduchosti je síla. Nepoužívání tabů lze lehce vysvětlit i kontrolovat.
Vysvětlit to jde úplně stejně. Nastavit v IDE/editoru taky. Vynutit nepoužívání mezer pro odsazení rovněž.
22.11.2015 13:52
pavlix | skóre: 54
| blog: pavlix
Vysvětlit to jde úplně stejně.A teď tu o karkulce.
22.11.2015 14:00
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Inak taká drobnosť ktorá sa hodí pri prepínaní medzi projektmi: editorconfig. Odporúčam to hodiť do existujúcich projektov, niektoré editory sa podľa toho riadia.
22.11.2015 14:10
pavlix | skóre: 54
| blog: pavlix
24.11.2015 11:39
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
 24.11.2015 12:25
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
24.11.2015 12:25
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Medzi doplnenými linkmi je celkom zaujímavá anketa na stackoverflow.
22.11.2015 09:33
pavlix | skóre: 54
| blog: pavlix
nepokladám za pekné a aj pri svojom malom rozlíšení monitoru vidím celý riadok.To byl jen příklad, spousta funckí má daleko delší seznam argumentů, zvlášť pokud se jedná o struktury s prefixovaným tagem. Ve skutečnosti se ti některé na řádek vejdou a jiné nikoliv. Co víc, ve skutečnosti se ti někdy vejdou a někdy ne ve stejném monitoru, já například dost často edituju dvojici souborů vedle sebe a tím máš prostor na zobrazení řádku z ničehonic poloviční. Já osobně používám většinou to co mi nabízí vim, tedy seznam argumentů tak, jak to máš ty, ale s dvojtým odsazením (tedy dvojnásobným počtem mezer, na příkladu glibc pochopíš, proč taby zásadně nepoužívám).
 21.11.2015 22:10
xsubway | skóre: 13
| blog: litera_scripta_manet
21.11.2015 22:11
pavlix | skóre: 54
| blog: pavlix
21.11.2015 22:44
xsubway | skóre: 13
| blog: litera_scripta_manet
22.11.2015 09:43
pavlix | skóre: 54
| blog: pavlix
21.11.2015 22:10
xsubway | skóre: 13
| blog: litera_scripta_manet
21.11.2015 22:11
pavlix | skóre: 54
| blog: pavlix
21.11.2015 22:44
xsubway | skóre: 13
| blog: litera_scripta_manet
22.11.2015 09:43
pavlix | skóre: 54
| blog: pavlix
Ano, ale jen pokud je ten modul skutečně nový.Pobavilo. Myslím, že ti unikla pointa příspěvku.
22.11.2015 08:40
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Nevýhody tabelátorů, které se nikdy nezredukují, jsou ty, že jsou bílým znakem – a tudíž je lidé nevidí a dělají v jejich použití chyby.
Nevýhody mezer, které se nikdy nezredukují, jsou ty, že jsou bílým znakem – a tudíž je lidé nevidí a dělají v jejich použití chyby.
v Unicode má te celou škálu znaků, které můžete používat, máte-li masochistické sklony. Například vaší pozornosti bych dal znaky s kódem U+00A0, U+2000-U+200B ...
22.11.2015 09:23
pavlix | skóre: 54
| blog: pavlix
Nevýhody mezer, které se nikdy nezredukují, jsou ty, že jsou bílým znakem – a tudíž je lidé nevidí a dělají v jejich použití chyby.Nesmysl. Mezery sice jsou bílé znaky, ale při absenci tabulátorů a při použití neproporcionálního písma jsou na první pohled vidět (pokud nejsou na konci řádku).
22.11.2015 09:33
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Nesmysl. Mezery sice jsou bílé znaky, ale při absenci tabulátorů a při použití neproporcionálního písma jsou na první pohled vidět (pokud nejsou na konci řádku).
Nesmysl. Tabulátory sice jsou bílé znaky, ale při absenci mezer a při použití libovolného písma jsou na první pohled vidět (pokud nejsou na konci řádku).
22.11.2015 10:21
xkucf03 | skóre: 50
| blog: xkucf03
Nesmysl. Tabulátory sice jsou bílé znaky, ale při absenci mezer a při použití neproporcionálního písma jsou na první pohled vidět (pokud nejsou na konci řádku).
.
Jinak v mejch zdrojácích odsazuju dvouznakovým tabem nebo naprosto chaoticky (například copypaste z MC vieweru nahradí všechno mezerama) + různé kopírování kusů kódu z různých lokací v různý čas.
P.S. Parser, co má v sobě pravidla pro formátování textu je to blobovatej :-P  .
22.11.2015 08:37
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
.
22.11.2015 08:37
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Renderovacia dĺžka je 8, nie 4.
a po úspěchu jsem si to zase nastavil na 4. Mea culpa.
22.11.2015 09:20
xsubway | skóre: 13
| blog: litera_scripta_manet
22.11.2015 09:36
pavlix | skóre: 54
| blog: pavlix
Je skvělé, když má projekt určený a (hlavně) dodržovaný coding style.Existuje nějaký takový open source projekt netriviálního rozsahu? Já narážím na to, že je coding style nedodržovaný, neúplný a nejednoznačný. :)
22.11.2015 11:22
xsubway | skóre: 13
| blog: litera_scripta_manet
... ale předpokládám, že Linux bude jeden z takových.
Mám zkušenost s closed source projekty (netriviálního rozsahu), kde je coding style sice určený, ale bohužel ne vždy dodržovaný  Open source používám na každém kroku, ale nevytvářím do něj žádné zdrojové kódy. Nicméně občas se do takového zdrojáku musím podívat .-)
22.11.2015 11:38
pavlix | skóre: 54
| blog: pavlix
Open source používám na každém kroku, ale nevytvářím do něj žádné zdrojové kódy. Nicméně občas se do takového zdrojáku musím podívat .-)
22.11.2015 11:38
pavlix | skóre: 54
| blog: pavlix
ale předpokládám, že Linux bude jeden z takových.Neptal jsem se na zbožná přání a předpoklady. :)
Mám zkušenost s closed source projekty (netriviálního rozsahu), kde je coding style sice určený, ale bohužel ne vždy dodržovanýMotivace pro nedodržování coding style je příliš veliká. :)
22.11.2015 21:33
pavlix | skóre: 54
| blog: pavlix
Pokud není motivace pro dodržování nějakého code style, je to obvykle proto, že code style je špatně zvoleno.Každý coding style, co jsem kdy viděl, měl nějakou zásadní vadu. Navíc jsem narazil na výrazný rozdíl na jednotlivé body mezi lidmi. Tudíž je prakticky každý coding style z pohledu prakticky každého vývojáře špatně zvolený a tudíž jenom jinými slovy říkáte to co já, tedy že (univerzálně) není motivace pro dodržování coding style.
net/, mi dost často ušetří práci (třeba proto, že se můžu spolehnout, že určité konstrukce budou zapsány určitým způsobem).
22.11.2015 22:08
pavlix | skóre: 54
| blog: pavlix
V té úvaze je chyba v předpokladu, že to, že se mi na coding style něco nelíbí, automaticky znamená, že nemám motivaci ho dodržovat.To už si ovšem vyřešte s mistrem Ponkrácem.
To bylo spíš takové zbožné přání
Stoprocentně samozřejmě ne, to by se u projektu takového rozsahu asi uhlídat nedalo, ale míra dodržování coding style je - aspoň u core částí - hodně nadstandardní. V nějakých driverech exotických zařízení, které si píše výrobce sám a nikdo jiný jim nerozumí, tam se občas najde ledacos podivného, a to nejen ohledně coding style.
st.c jsem měl neodbytný pocit, že nezanedbatelná část z něj je starší než Linux.
. Například aic7770.c: "$FreeBSD$".
total: 337 errors, 49 warnings, 4645 lines checked
Ale pro nepřijetí patche stačí někdy i jeden warning.
Ale checkpatch i když obsahuje mnoho testů, tak některé programovací věci nedává. Třeba ten floppy.c je plnej globálních proměnných (dneska se to dává někam do pdata). Makra jsou mixovaný s kódem (případ i toho st.c). Blokování částí zdrojáku ifdef makry. Podivné definice init a exit funkcí (které se dneska už ani nepoužívaj ). Globální ioctl zámek se řeší tak, že se zavolá funkce, ve které je wrapper s mutexy a ta pak volá původní kód . Ještě myslím, že když se během práce s disketou vytáhne disketa, tak se driver zasekne (naposled to dělalo win3.11 s modrou smrtí).
After millennia of heated debate, mercifully, at long last, we have an answer. Most developers prefer tabs to spaces. Upon closer examination of the data, a trend emerges: Developers increasingly prefer spaces as they gain experience. Stack Overflow reputation correlates with a preference for spaces, too: users who have 10,000 rep or more prefer spaces to tabs at a ratio of 3 to 1.
22.11.2015 19:46
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
22.11.2015 21:27
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
23.11.2015 15:02
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Si osamelý?
Nie dosť.
23.11.2015 15:05
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Teda no kašlať na to, aj tak za mnou práve letí návšteva takže sa mi neoplatí púšťať sa do ďalších vecí v projekte ktorý robím tak rozpíšem ...
Tento blog som mal rozpísaný od roku 2012 ale akurát tam niečo podobné napísal bedňa tak som to kompostoval.
Predchádzajúci blog ... no to bola kombinácia pár udalostí z predchádzajúcich dní a neustále štekajúceho susedovho psa.
4.12.2015 16:07
mirec | skóre: 32
| blog: mirecove_dristy
| Poprad
Čo som komu urobil? Dnes sa zase musím hrabať v zdrojáku kde autori nemali jasné, či používajú 2, 4 alebo 3 medzery tak je to všetko namixované.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 22.11.2015 16:06
22.11.2015 16:06
{kind=link}
{kind=link}