Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
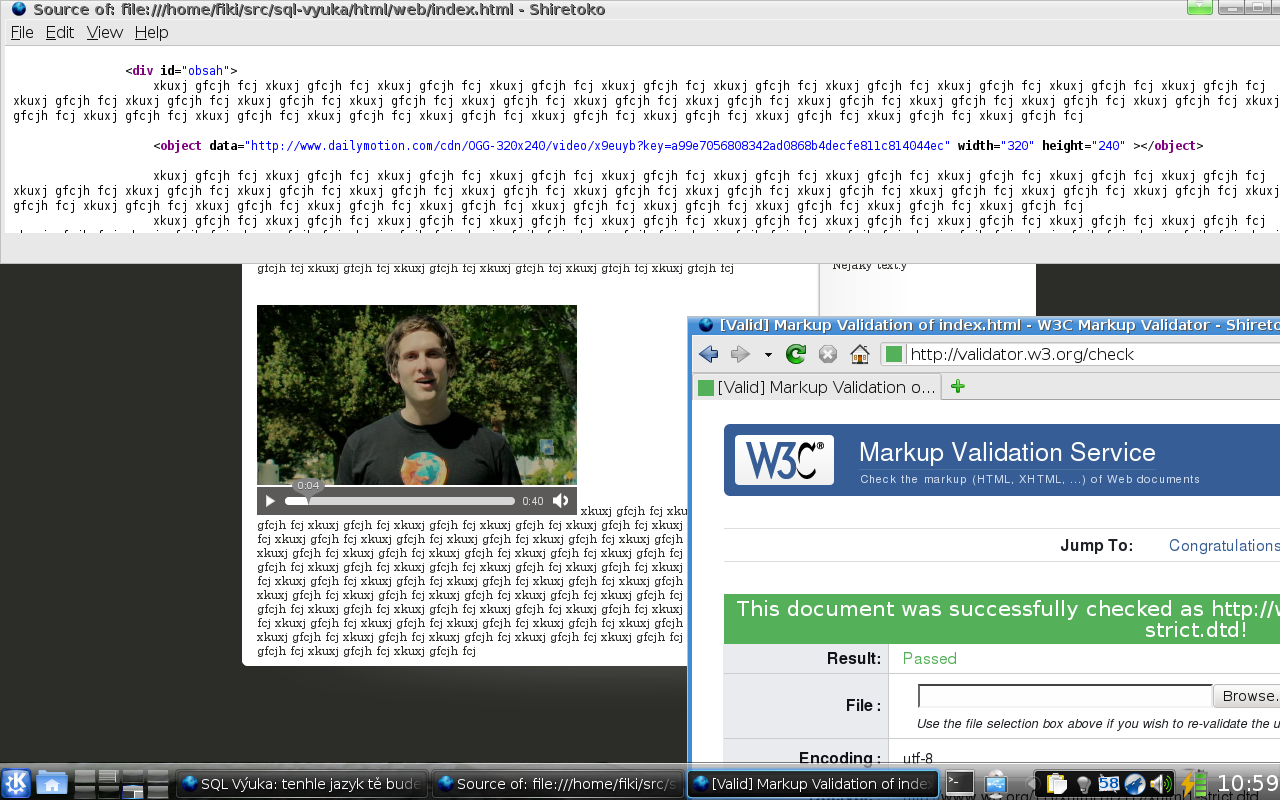
Nový Firefox 3.5 přináší podporu přehrávání videa. V souvislosti s tím se většinou mluví o HTML5 značce <video>.
Pokud ale nechcete rezignovat na validitu svých pracně odladěných XHTML stránek, můžete klidně místo zápisu:
<video src="http://www.dailymotion.com/cdn/OGG-320x240/video/x9euyb?key=a99e7056808342ad0868b4decfe811c814044ec"
width="320"
height="240">
</video>
použít zápis pomocí validní značky:
<object data="http://www.dailymotion.com/cdn/OGG-320x240/video/x9euyb?key=a99e7056808342ad0868b4decfe811c814044ec"
width="320"
height="240" >
</object>
Nový Firefox takové video v pohodě přehraje a uživatel má k dispozici ovládací panel stejně jako při nevalidním zápise. Viz přiložený obrázek.
P.S. je mi jasné, že se to tu zase zvrhne ve flamewar, ale přesto doufám, že alespoň pro někoho bude tato informace užitečná 
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
je mi jasné, že se to tu zase zvrhne ve flamewarXHTML is dead, long live HTML 5! :-P
Stýská se ti po hláškách „Optimalizováno pro prohlížeč XYZ“ že jo? 
Což o to, užitečné to je. Ale jen jako historická momentka. HTML5 v podstatě konzervuje stávající chlív. (Dobrá, pár elementů přidává, ale jinak je to pořád stejná břečka.)
), postupný vývoj je jediná možnost.
Popírat dané? Nebrat na vědomí? XHTML 2?
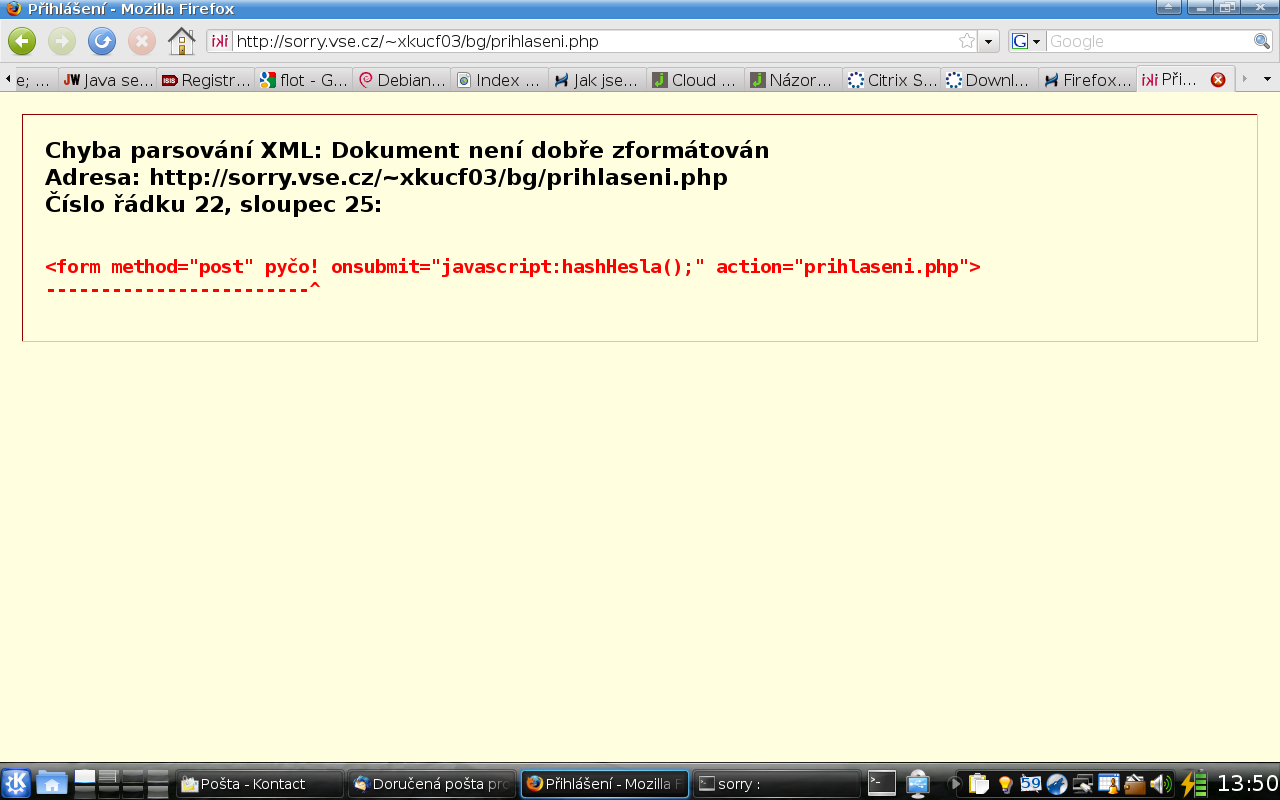
Chlív a „katedrála“ mohou existovat klidně vedle sebe – ostatně tak tomu už teď je: prohlížeče pracují v různých režimech. Když pošleš Firefoxu stránku jako application/xhtml+xml, klade na ni mnohem větší nároky (musí být validní, jinak to dopadne jako na přiloženém obrázku – tzn. nezobrazí se vůbec). Zatímco chlív text/html se prohlížeč vždycky snaží uživateli nějak zobrazit.
Není tedy potřeba strašit s nějakým velkým třeskem nebo náhlou změnou – prostě tu bude starý web a vedle toho nový web – uživatel to na první pohled ani nepozná, jen prohlížeč bude pracovat v různých režimech. A nové úžasné funkce se budou přidávat do toho nového webu – takže až budeš psát nové stránky, dáš si pozor na to, aby byly validní. Ale v žádném případě to neznamená, že by se lidem najednou špatně zobrazovaly ty staré stránky, které někdo sprasil před deseti lety a dodnes visí na Síti.
prostě tu bude starý web a vedle toho nový webNemyslím, že zrovna tohle opravdu chceme… HTML 5 není tagsoup. Můžete to brát tak, že HTML 5 je ten váš nový web + pořádná specifikace, jak se chovat k tomu starému (i to je potřeba). Jo vám vadí, že to není XML…
 7.7.2009 15:00
xkucf03 | skóre: 50
| blog: xkucf03
7.7.2009 15:00
xkucf03 | skóre: 50
| blog: xkucf03
Můžete to brát tak, že HTML 5 je ten váš nový web
Bohužel je to krok zpátky.
pořádná specifikace, jak se chovat k tomu starému (i to je potřeba)
Budiž (většina problémů byla během těch let vychytána a ohackována, ale může být)
Nespojoval bych ale dohromady:
To nemůže dopadnout dobře. Měli bychom se připravit na to, že třeba za deset let z prohlížečů vykucháme podporu těch starých stránek z 90. let a budou zobrazovat jen ten nový web. Gopher si dneska asi taky nikdo neprohlíží (i když teď jsem koukal, že FF ten protokol pořád ještě umí). Takové odlehčení prohlížečům jedině prospěje.
Jo vám vadí, že to není XML
Ano, vadí. Zrovna před pár minutami jsem objevil chybu na své stránce tak, že mi ji Firefox odmítl zobrazit – bylo to velice primitivní, místo otevírací značky tbody jsem napsal uzavírací.* Chybu jsem tedy opravil hned a vyhnul nevyzpytatelnému chování ve všemožných prohlížečích. V tomto případě se jednalo obyčejný překlep (přebytečné lomítko), ale nevalidní XHTML člověka často upozorní na mnohem závažnější chyby (ve větvení, v datech, v logice programu).
Na textové specifikace každý dlabe, ale pokud stránky půjdou validovat automatizovaně a hromadně, což umožňuje XML, je to už o něčem jiném. Zastánci HTML 5 se ohánejí pragmatismem a realismem – ale já právě realisticky předpokládám, že můžeme být rádi, pokud si autor stránky ohlídá validní XML (což jde automaticky a bezbolestně), než že by si na dobrou noc četl specifikace HTML 5.
*) bohužel je to takový bastl v PHPčku. Kdybych ten web psal v JSPX (tzn. XML), k chybě by vůbec nedošlo – odhalil bych ji už při psaní stránky.
HTML do verze 4 je SGML. Žádný webový prohlížeč ale SGML neumí. XHTML je XML, jeho podpora je uspokojivá. HTML 5 není ani SGML, ani XML. Ze syntaktického hlediska se jedná o nový jazyk (třebaže se velmi podobá parserům současných HTML prohlížečů).
Jenže (X)HTML není jen značkovací jazyk. Patří k tomu DOM nebo (javascriptové) API.
Takže nyní k jednomu jazyku a ke chlívku přibyl druhý jazyk, který je složitý jako ten chlívek. Přesně to, co nechcete (dva světy). A přesně to, co nechtějí lidi, co mají psát producenty a konzumenty webového obsahu (složitost HTML).
Velká část webu jsou generované stránky. Velká část z nich je formální XML zaneřáděné reklamními skripty a hacky ze světa HTML. Kdyby se HTML uměle neomlazovalo, tak by postupem času bylo opuštěno. Jak se lidi naučili nepoužívat proprietárních rozšíření prohlížečů, tak by se časem naučili používat XHTML DOM.
Proto si myslím, že HTML 5 je krok špatným směrem.
Můžete to brát tak, že HTML 5 je ten váš nový webOvšem tahle část v HTML 5 jaksi chybí… Pokud tedy „novým webem“ nemyslíte tag
<video> a pár dalších nahodilostí přidaných způsobem jako když pejsek a kočička vařili dort.
pořádná specifikace, jak se chovat k tomu starému (i to je potřeba)A ta je prosím pěkně dobrá k čemu? Aby se podle ní přepsaly staré weby? Ale vždyť se prý dělá proto, že staré weby nikdo přepisovat nebude. Nebo aby se podle toho dal napsat nový prohlížeč, který staré weby zobrazí správně? To pak ale aby ta specifikace vypadala způsobem „na webu example.com je ve skriptu
extra.js na řádku 32 třeba vrátit User-Agent řetězec odpovídající MSIE 5.5, a dále zpracovávat skript jako MSIE 5.5 v quirks módu, nebo User-Agent řetězec odpovídající Firefoxu 2.0, a pak je nutné skript zpracovávat jako Firefox 2.0.0.3 – 2.0.0.7“. To bude docela makačka takhle zmapovat celý web…
Když pošleš Firefoxu stránku jako application/xhtml+xml, klade na ni mnohem větší nároky (musí být validní…
Validní být nemusí, co jsem si všiml, Firefox kontroluje jen jestli je well-formed ve smyslu XML. Ale aspoň něco.
Jistě že postupný vývoj. Ale vývoj dopředu. HTML5 nikam nepostupuje, jen přešlapuje na místě. HTML5 jen prodlužuje agónii HTML.
Například jazyky založené na XML se svojí modularitou nabízejí postupný přechod, dlouhodobě udržitelný vývoj, strojové zpracování, deklarativní přístup namísto imperativního.
nikdo o to nestojíTak tohle se mi povedlo, v zápalu editace jsem vyrobil nádherný dvojsmysl
Samozřejmě jsem neměl na mysli, že nikdo nestojí o kvalitní, široce přijímané standardy, ale o nový web založený na nových standardech, které by prý měly být kvalitní a když pámbů dá, i široce přijímané. No nic, asi už toho nechám.
Pokud se dávno ví, jak to dělat správně, proč se to tak nedělá?Protože by proto bylo nutné naprogramovat nové jádro prohlížeče, a když by byl ten standard jednou vytvořen, nebyl by problém pro nikoho takové jádro napsat. Takže výrobci současných prohlížečů do ničeho takového nepůjdou, byli by sami proti sobě – oni jsou dobří v tom, že dokážou věštit z toho guláše tagů, co je dnes na webu, a nemají zájem přicházet s něčím, čím by ulehčili život především potenciální konkurenci. Další možností z komerčního sektoru jsou firmy, které buď vlastní prohlížeč nemají, nebo si mohou dovolit vyvíjet paralelně starý prohlížeč a mezi tím pracovat na nové technologii. Ty ale samozřejmě nemají zájem onu novou technologii vybudovat jako srozumitelný otevřený standard, ale naopak si ji chtějí udržet ve své moci – takže tu máme Flash, SilverLight atd. Pak už zbývá jen W3C, jenže tam se zalekli právě autorů prohlížečů a nechali se přemluvit k tomu, že rozvoj je špatně a je nutné zakonzervovat současný stav navěky.
Kde je ta parta akademiků odtržených od reality se svým slavným XHTML 2, které už bylo definitivně pohřbeno (a nikdy nemohlo dopadnout jinak, protože zignorovalo byť jenom zpětnou kompatibilitu)?A k čemu je dneska jakýkoli standard, který bude udržovat zpětnou kompatibilitu? Vždyť s HTML si dnes stejně už každý dělá co chce, akorát místo dřívější nadvlády Netscapu, pozdější MSIE a ještě pozdějšího přísahání na MSIE nebo na Firefox se dnes dělají weby pro MSIE, Gecko, WebKit a Operu. Žádné standardy, ale ladí se pro několik konkrétních prohlížečů. Takže co jiného by dnes měl udělat nový standard, než že přetrhne zpětnou kompatibilitu s tímhle gulášem, a zavede něco nového? Zvlášť když je jasné, že takováhle změna stejně jednou musí přijít, protože HTML v současné podobě se nemůže dál rozvíjet a jde jenom o to, jak dlouho bude umírat.
 7.7.2009 13:41
Jendа | skóre: 78
| blog: Jenda
| JO70FB
7.7.2009 14:28
xkucf03 | skóre: 50
| blog: xkucf03
7.7.2009 13:41
Jendа | skóre: 78
| blog: Jenda
| JO70FB
7.7.2009 14:28
xkucf03 | skóre: 50
| blog: xkucf03
Tak mu poraď tohle: detekce mime typu. Prohlížeč dostane to, co umí (Firefox a Opera tedy XHTML, Konqueror s webkitem taky XHTML…).
Je to sice psané v PHP, ale totéž se dá udělat v libovolném jazyce (případně na úrovni webového serveru).
Co posílat jako výchozí (když prohlížeč neřekne, co podporuje), ať si každý rozmyslí sám. Ale pořád je lepší mít správné XHTML stránky a jen posílat špatný MIME typ některým prohlížečům – změnit totiž v budoucnu MIME typ znamená změnit jeden řádek kódu, zatímco přepisovat všechny stránky je nesrovnatelně víc práce.
<!DOCTYPE html>
7.7.2009 18:52
xkucf03 | skóre: 50
| blog: xkucf03
Což je ale chyba těch uživatelů a chyba těch reklamních a statistických skriptů
Vstup od uživatele by se měl validovat (jako třeba tady na Ábíčku), takže ani jakkoli divoké použití WYSIWYGu by nemělo ohrozit validitu stránky.
7.7.2009 15:36
Jendа | skóre: 78
| blog: Jenda
| JO70FB
A nějak mě pořád nikdo nepřesvědčil, že je XHTML tak kchůl, abych na něj přešel.Jeden příklad máte v blogu. Prohlížeče postupně implementují tag video, který je ale v HTML 4 nevalidní. Takže buď si budou všichni zvykat, že některé chyby validátoru je potřeba ignorovat, nebo validátor vezme tag
<video> na milost a bude validovat podle toho, co si jeho programátor vycucal z prstu (možná to je HTML 4 + tag <video>, a možná taky něco jiného). Kdyby se už běžně používalo XHTML, jenom se vymyslí nový jmenný prostor třeba pro multimediální obsah, do toho jmenného prostoru se přidá tag <video> a třeba rozšířený tag <image>, tag <audio> a třeba nějaký vylepšený <object>, a je hotovo. Všechno by bylo správně podle standardů, a to hned. Místo současného guláše, kdy se prohlížeče vlastně neřídí žádnými standardy, by to byl docela výrazný krok vpřed.
Kromě toho, že když má aplikace vyrobí v HTML nějaký nesmysl (stane se... třeba (de)generátor tabulky zapomene uzavřít tr...), tak to prohlížeče vždycky nějak zobrazí, kdežto u XHTML se uživatel dočká něčeho jako ukazuje Franta.To ale není vlastnost HTML nebo XHTML, ale pouze implementace v tom kterém prohlížeči. Naprogramovat se to dá klidně přesně opačně, nebo tak, že se to bude chovat stejně pro HTML i XHTML.
Kromě toho, že když má aplikace vyrobí v HTML nějaký nesmysl (stane se... třeba (de)generátor tabulky zapomene uzavřít tr...), tak to prohlížeče vždycky nějak zobrazí, kdežto u XHTML se uživatel dočká něčeho jako ukazuje Franta.
To je ale ve skutečnosti výhoda XHTML. Protože takhle hned při prvním vyzkoušení uvidíte, že je něco špatně, a opravíte to. V případě HTML to prohlížeče nějak zobrazí a vy nemáte nejmenší kontrolu nad tím, jak to který zobrazí. Jak by se vám líbil překladač céčka, který by na syntaktické chyby nereagoval chybou, ale tím, že by si zkusil nějak domyslet, co jste tím asi tak mohl myslet? Mně ani trochu…
abych na něj přešel.
Přešel odkud?
BTW: XHTML je dneska standardem při běžné komerční tvorbě webů – kdysi byla validita kódu jakousi přidanou hodnotou, konkurenční výhodou… dneska je to naprostá nezbytnost, aby si u tebe vůbec web někdo nechal dělat a aby ses za svoje dílo nemusel stydět. (a to je dobře, díky bohu za to).
(de)generátor tabulky zapomene uzavřít tr
Jak zapomene? Generátor je nějaký program a ten má dělat to, co po něm chci. Pokud neuzavírá správně značky, nebo neescapuje vstup tak, jak má, je v něm chyba a tu je potřeba opravit – ne se tvářit, jako že chyba neexistuje a nechat její řešení na prohlížeči (ať si chybný vstup vyloží podle svého).
kdežto u XHTML se uživatel dočká něčeho jako ukazuje Franta.
To záleží na HTTP hlavičkách (MIME typu) a na prohlížeči. Můžeš tam samozřejmě posílat typ text/html a pak k tomu nedojde a stránka se normálně zobrazí (…ale to není zrovna optimální). Nezobrazení stránky v prohlížeči je ale potřeba brát jen jako vedlejší efekt – primární problém je někde jinde – máme chybu v programu, neošetřujeme správně vstupy atd. To se dá řešit kvalitními vývojáři, testováním před nasazením nebo on-line kontrolou validity na serveru při provozu či pravidelnou validací našeho webu nějakým pavoukem, který bude procházet stránky a hledat na nich chyby.
A viz můj předchozí komentář – nevalidní stránka nemusí být jen důsledkem triviálního překlepu, ale může poukazovat na vážnější chybu.
7.7.2009 17:10
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Přešel odkud?Z HTML 4.01?
dneska je to naprostá nezbytnost, aby si u tebe vůbec web někdo nechal dělat a aby ses za svoje dílo nemusel stydětAle všechny mnou vyrobené stránky jsou validní. (podle HTML 4.01 Trans.) A testuji je několika vykreslovacími jádry.
Pokud neuzavírá správně značky, nebo neescapuje vstup tak, jak má, je v něm chyba a tu je potřeba opravitAno, když je v něm chyba, je třeba ji opravit. Ale někdy se ta chyba projevuje jen při určité shodě okolností a tak ji při testování aplikace prostě neodhalím. Pak mě na tu chybu musí upozornit uživatel. A je IMHO lepší, když mi uživatel napíše, že když udělá to, to, to a to, tak mu kus tabulky (například) ujede někam mimo (a aplikace je pořád celkem použitelná), než když mu při pokusu o vstup na tu stránku prohlížeč vyblije červené Parse error.
To záleží na HTTP hlavičkách (MIME typu) a na prohlížeči. Můžeš tam samozřejmě posílat typ text/html a pak k tomu nedojde a stránka se normálně zobrazí (…ale to není zrovna optimální).Ne, opravdu nechci posílat XML jako
text/html.
To se dá řešit kvalitními vývojářiSnažím se být kvalitní jak to nejvíc jde
testováním před nasazenímTo nikdy nemůže odhalit úplně vše.
pravidelnou validací našeho webu nějakým pavoukem, který bude procházet stránky a hledat na nich chybyKdyž to by musel pavouk umět dělat spoustu různých interaktivních věcí.
A viz můj předchozí komentář – nevalidní stránka nemusí být jen důsledkem triviálního překlepu, ale může poukazovat na vážnější chybu.A viz výše, IMHO je lepší, když se o překlepu nebo vážnější chybě dozvím tak, že mi někdo ukáže, jak dospět k rozhozené stránce, než jak dospět k Parse error.
A testuji je několika vykreslovacími jádry.Jinými slovy nepíšete podle nějakého standardu, ale podle toho, co zrovna umí čtyři nejpoužívanější vykreslovací jádra. Což jenom podporuje moje tvrzení, že by bylo dobré začít pro web používat nějaký standard (který by ovšem nejprve musel vzniknout).
7.7.2009 17:25
Jendа | skóre: 78
| blog: Jenda
| JO70FB
(No, u toho testu kompatibility si nejsem jistý, jestli v HTML 5 něco takového je )
Jinak tahle argumentace není férová. Při multiplatformním vývoji si taky otestujete, jak vám to šlape na různých platformách, i když píšete podle "standardu" (Qt, Java, whatever). Žádný standard (ani ISO HTML) nezaručí a nemůže zaručit, že se všechno bude ve všech prohlížečích chovat stejně, už kvůli implementačním chybám, kterým se nevyhnete a které žádný test kompatibility nemůže stoprocentně podchytit (příklad z jiného světa: OpenJDK sice projde JCK, ale zaslechl jsem o pár problémech).
Myslíte třeba něco, co detailně popíše, jak se stránka zpracovává, jaký je její objektový model, jak s ním lze manipulovat, jak se chovat v případě chyb, poskytne detailní test kompatibility a tak?Úplně by stačil postup parsování a převod na DOM a ošetření chyb (nejlépe takové, že se chyba oznámí uživateli – a případně že se zobrazí ta část stránky, která byla zpracována před tím, než prohlížeč narazil na chybu). A pak v dalším modulu specifikace významu elementů a způsobu jejich zobrazení.
Jinak tahle argumentace není férová. Při multiplatformním vývoji si taky otestujete, jak vám to šlape na různých platformách, i když píšete podle "standardu" (Qt, Java, whatever).Ano, jenže to otestujete, jak to funguje na různých platformách, a případně se kód (nejlépe pomocí podmíněného překladu) pro příslušné platformy upraví. Jenže na webu psát podle standardu ani pořádně nejde, protože jenom ve standardu je několik věcí, které prohlížeč může ale nemusí implementovat, které ale ovlivní to, jakým způsobem prohlížeč dokument parsuje (prohlížeči s podporou zkráceného zápisu tagů a bez této podpory vyleze ze stejného HTML úplně jiný DOM). I když tohle vynechám, pořád zůstanou problémy s tím, že současný „standard“ je na mnoha místech nejasný, prohlížeče spoustu věcí implementují po svém, spoustu dalších věcí přidávají – a místo toho, aby se to nějak třídilo a uspořádávalo, neustále se to jenom nabaluje a nabaluje na ten současný zmatek. Když se najde chyba v překladači C, dá se do kódu
#ifdef ve kterém se chyba obejde. Když se najde chyba v prohlížeči, implementují ostatní prohlížeče tutéž chybu trochu jinak také a původní prohlížeč ji implementuje ještě jinak v příští verzi s novým vykreslovacím módem. K čemu je to dobré?
 8.7.2009 13:32
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
8.7.2009 13:32
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
BTW: XHTML je dneska standardem při běžné komerční tvorbě webů – kdysi byla validita kódu jakousi přidanou hodnotou, konkurenční výhodou… dneska je to naprostá nezbytnost, aby si u tebe vůbec web někdo nechal dělat a aby ses za svoje dílo nemusel stydět. (a to je dobře, díky bohu za to).Z toho uz jsem vyrostl. Pisu weby tak, aby jejich kod byl well-formed XML a pokud nepotrebuju pouzivat vlastni namespaces, tak i validni XHTML 1.1. Kdyz ale chci z nejakeho duvodu pouzivat vlastni namespaces (napr. u slozitejsich RIAs je to v kombinaci s JS skvele reseni), s klidem validator ignoruju, protoze to, ze XHTML stranku rozsirenou o vlastni namespaces povazuje za nevalidni, povazuju za hodne spatny vtip.
prefix:atribut jako název atributu; jak je to u elementů jsem nikdy nezkoušel). A že podpora jmenných prostorů je jen dobrá vůle prohlížečů, protože v HTML nic takového není. Jinak to co popisujete je přesně ten směr, kterým se podle mne měl vývoj HTML ubírat. Místo toho se bohužel dělá standard z toho, jak HTML renderuje MSIE 5.5 nebo která že to verze.  8.7.2009 17:55
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
8.7.2009 17:55
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
Pak taky jistě víte, že MSIE se k jmenným prostorům chová jinak než ostatní prohlížeče (resp. jmenné prostory ignoruje a chápe celý blok prefix:atribut jako název atributu; jak je to u elementů jsem nikdy nezkoušel)Vim, ale jQuery to hezky zapouzdruje, takze
$("selektor").attr("prefix:jmeno"); funguje vsude. Prace s elementy v jinych NS v JavaScriptu je bohuzel pri potrebe pokryt vsechny prohlizece hodne oskliva Nicmene tvurci nekterych JS frameworku to evidentne zvladli dobre, protoze nektere pouzivaji elementy bezne. Nastesti si ale temer vzdy vystacim s atributy. Skoda je, ze IE neumi pomoci CSS skryt namespacovane elementy.
7.7.2009 15:12
Daniel Kvasnička ml. | skóre: 52
| blog: The Joys and Sorrows of Being an IT Freak
| Ostrava
Podle čeho se to ale bude validovat? (DTD to podle nich být nemůže).
+ viz http://www.root.cz/zpravicky/xhtml-2-pravdepodobne-miri-k-ledu-prioritou-je-html-5/302452/
 7.7.2009 16:55
thingie | skóre: 8
7.7.2009 17:12
thingie | skóre: 8
7.7.2009 16:55
thingie | skóre: 8
7.7.2009 17:12
thingie | skóre: 8
html, hlavička v head a tělo v body, zato si pamatuje, které tagy jsou volitelné a které povinné a jaká jsou pravidla pro doplňování chybějících tagů.
7.7.2009 17:28
thingie | skóre: 8
7.7.2009 17:36
thingie | skóre: 8
A kvůli takovým, s prominutím, pitomostem je potřeba přijímat nový světový standard? Vždyť na to přece stačí stará vykreslovací jádra prohlížečů.
 8.7.2009 15:47
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
8.7.2009 15:47
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz


{kind=link}