Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
Nedávno jsem po dlouhém hledání konečně nalezl funkční program pro uspořádání knih a cédéček - Bookcase. Různých pokusů se po Síti povaluje mnoho, ale pouze tento disponuje určitými mechanismy, na které jsem kladl důraz, i když ani tato aplikace nesplňuje můj ideál na 100 %. Jediným vážným konkurentem, který jsem nalezl, je Alexandria; ten mě ale screenshoty nepřesvědčil. Sám autor ještě odkazuje na své (komerční) vzory; zkoušel jsem Readerware, ale vůbec se mi nelíbil.
Jaké požadavky tedy na takový software mám? Vše vychází z čistě 'domácího' účelu, takže:
Jak se čtenář dovtípil, Bookcase u mě prozatím vede a já se pokusím nastínit jeho možnosti tak, abych to zvládl v jednom článku.
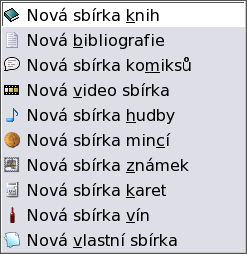
Pojmem 'sbírka' rozumíme souhrn jednotlivin, které lze na základě
společných znaků klasifikovat, řadit, ukládat (třeba do regálu). V současné
verzi lze v programu spravovat devět resp. deset typů sbírek. Každá sbírka
je uložena v jednom souboru a může mít teoreticky neomezený počet položek.
Každá položka může mít *neomezený* počet polí. Zde se omezím na několik
nejpraktičtějších typů sbírek a ukážeme si jak vytvořit vlastní typ.
Všechny stávající sbírky tedy jsou: knih, bibliografie (možnost exportu do
souboru .bib pro BibTeX), komiksů, videa, hudby, mincí,
známek, karet a vín.
Sbírka je uložena v souboru .bc, což je ZIP archiv
obsahující XML soubor a patřičně přejmenované obrázky. Obrázky nejsou nijak
upravovány či redukovány, takže se nedoporučuje zbytečně plýtvat místem.
Sbírce knih říkejme knihovna, ostatně podle tohoto zaměření získal program své jméno. Pro přidání záznamu slouží dialogové okno, které pochopitelně mění strukturu v závislosti na typu sbírky.
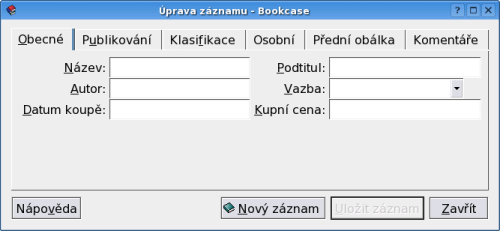
V případě knihy je možné (ale ne nezbytně nutné) vyplnit všechny myslitelné 'parametry', které může kniha mít. Volitelně můžeme přidat i obrázek obálky, které lze najít v nějakém e-shopu. Po kliknutí na 'Uložit záznam' se záznam uloží do databáze a políčka se vyprázdní; pokud chceme celý záznam zrušit, klikneme na 'Nový záznam'.
Popisem jednotlivých polí se zde nebudu zabývat, ale věřte, je jich tolik, že jsem měl problém celou kartu vůbec vyplnit (více předchozí odkaz). Lze také připojit osobní komentář, třeba stručný obsah. Z výše uvedeného vyplývá, že pole lze přidat, či ubrat, měnit jejich typ apod.
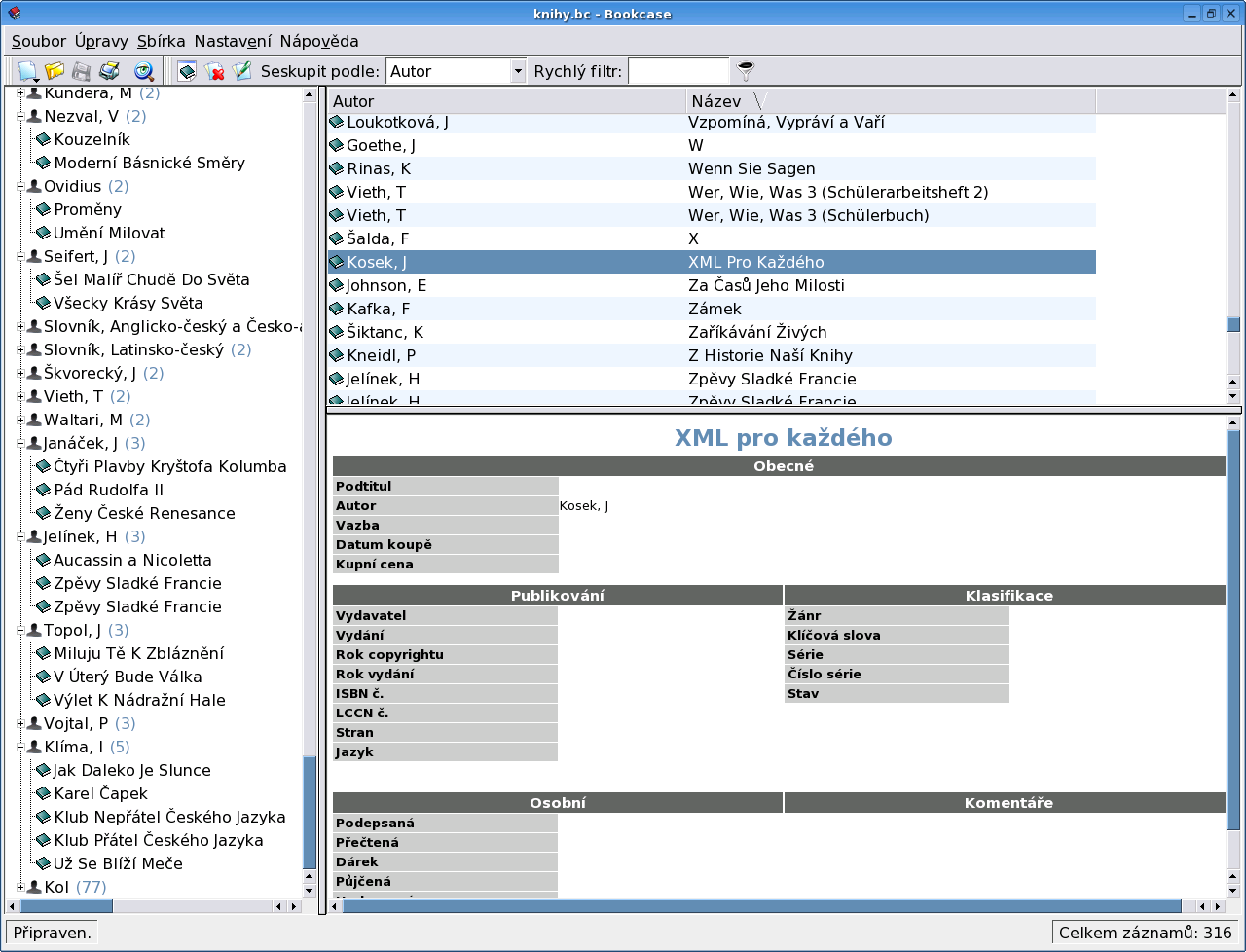
Tato sbírka slouží k organizaci zvukových nosičů, nenajdeme zde ale možnost pro MP3 či OGG soubory. Typy médií jsou pouze tři: CD, MC a vinyl. Opět lze vložit všechny možné typy údajů včetně bookletu, který lze stáhnout. Zde mě čekalo velké zklamání - program nepodporuje dotaz prostřednictvím CDDB, takže názvy stop musíte doplnit ručně (což se mi dělat nechce).
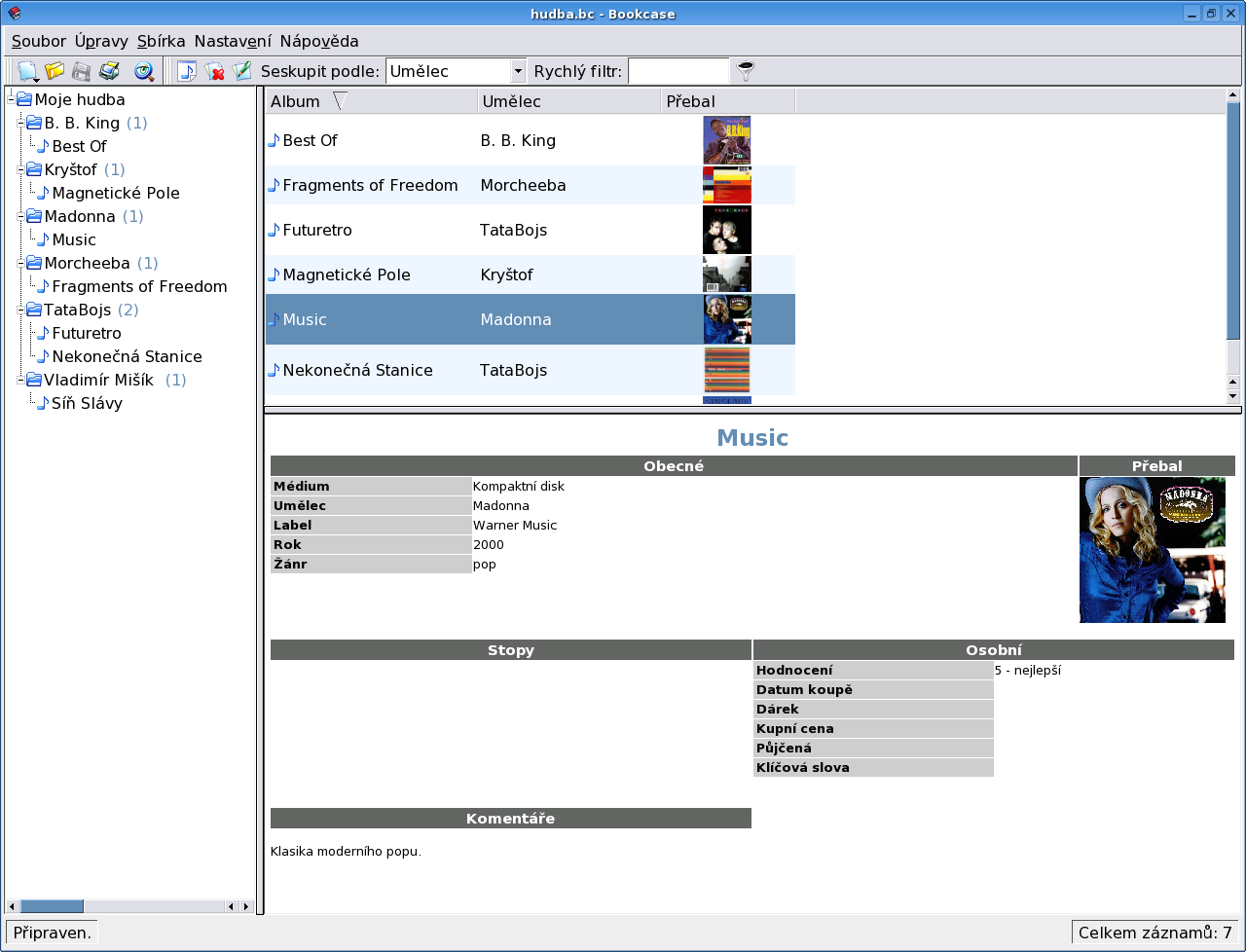
V levém sloupci se zobrazuje struktura databáze podle vybraného pole, to se vybírá na horní liště ('Seskupit podle'). Vedle této lišty je políčko pro filtr, kterým pro změnu ovlivníme výsledek v horní části okna. Tento princip samozřejmě funguje pro všechny typy sbírek, nejen pro hudbu. Ovládání je vůbec vyřešeno intuitivně a funguje dle očekávání.
Záznam pro video mě nejvíce 'dostal' - nechtělo se mi věřit, co všechno je o filmu možné vyplnit (osoby a obsazení, lidé kolem filmu, technické vlastnosti snímku apod.). Zde už je kromě DVD, VHS a VCD také DivX. Na webu Bookcase existují skripty, které tyto údaje načtou z webových encyklopedií. Já žádnou sbírku nemám, tak jsem to prakticky nezkoušel.
Pro demonstraci jsem si vymyslel jednoduchý seznam hardwaru, který asi nebude možné použít ve velké firmě, ale mohl by být funkční v domácnosti či menší firmě. Položka bude mít následující pole:
| Název pole | Obsah pole |
| Název | Katalogové označení výrobku - typ, model |
| Typ | Typ hardwaru, výběr z několika možnosti |
| Cena | Cena v korunách |
| Výrobce | Název výrobce |
| Web výrobce | Stránky výrobce, příp. stránka produktu |
| Identifikace | Identifikace výrobku, např. evidenční štítek |
| Nové | Bylo pořízeno jako nové? |
| Popis | Dodatečný popis |
Vytvoříme tedy novou sbírku příkazem 'Soubor/New/Nová vlastní sbírka'. Položka obsahuje pouze jedno obecné pole. Příkazem 'Sbírka/Pole sbírky' vyvoláme okno pro definici nových polí. Ponecháme stávající pole 'Název', pouze změníme jeho popis. Stiskem tlačítka 'New' vytvoříme další pole, tedy 'Typ'. V seznamu 'Druh' vybereme typ pole - 'Choice'. Do pole 'Povoleno' napíšeme typy hardwaru oddělené středníkem:
monitor; case; klávesnice; myš; tiskárna; skener; joystick
|
To jsou položky budoucího rolovacího seznamu, ze kterého se bude vybírat typ hardwaru. Další pole 'Cena' bude mít 'Druh' 'Číslo'. Takto tedy postupujeme při zakládání všech polí, každé z nich přidáme do seznamu stiskem tlačítka 'Použít'. Můžeme volit dodatečné parametry pole, jako je např. automatické doplňování apod. Nezapomínejme na 'Popis' - ten se uživateli zobrazí, klikne-li na otazníček na liště okna a následně na požadovaný prvek (ano, tzv. bublinková nápověda). Vynikajícím parametrem je 'Povolit seskupování'. Pokud jej totiž zaškrtnete, bude možné podle tohoto pole řadit seznam v levém sloupci hlavního okna.
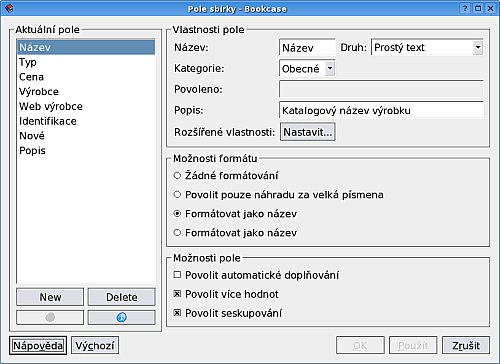
Tlačítky se šipkami v levé dolní části měníme pořadí polí ve výsledném okně. Po ukončení (můžeme se sem ale vždy vrátit) máme definovanou šablonu a můžeme přidat první položky. Klikutím na ikonu (nebo Ctrl+n) zobrazíme nově vytvořené okno. Jak vidíme, pole se 'sama' inteligentně rozložila do karet a zadávání je tedy přímočaré.
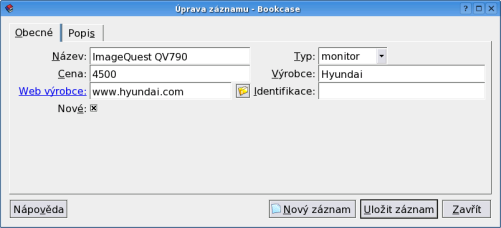
Máme tedy základní kostru. Zadáme cvičně několik záznamů a zjistíme, že nám chybí další pole: datum pořízení, počet kusů a obrázek. Nic se neděje, prostě stejným způsobem, jakým jsme pole vytvořili, přidáme další. Nemusíme se bát o již vyplněné údaje - nová pole budou ve starých záznamech prostě nevyplněná.
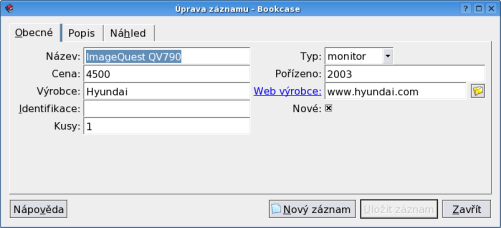
Tak jsme tedy získali snad již funkční rámec, teď jej stačí 'pouze' naplnit daty. Cvičně jsem to udělal a můžete se tedy podívat, jak naše dílo vypadá. Na horní liště máme v seznamu 'Seskupit podle' všechna pole, kterým jsme tuto možnost nastavili; podle toho se také mění levý seznam. Můžeme si tedy nechat vypsat všechny monitory, všechno podle data pořízení, výrobce apod. Samozřejmě se nejedná o nic převratného, nelze například měnit pod-řazení, to je vždy podle abecedy (vzestupně, nebo sestupně). Ale přesto je to velice přehledné.
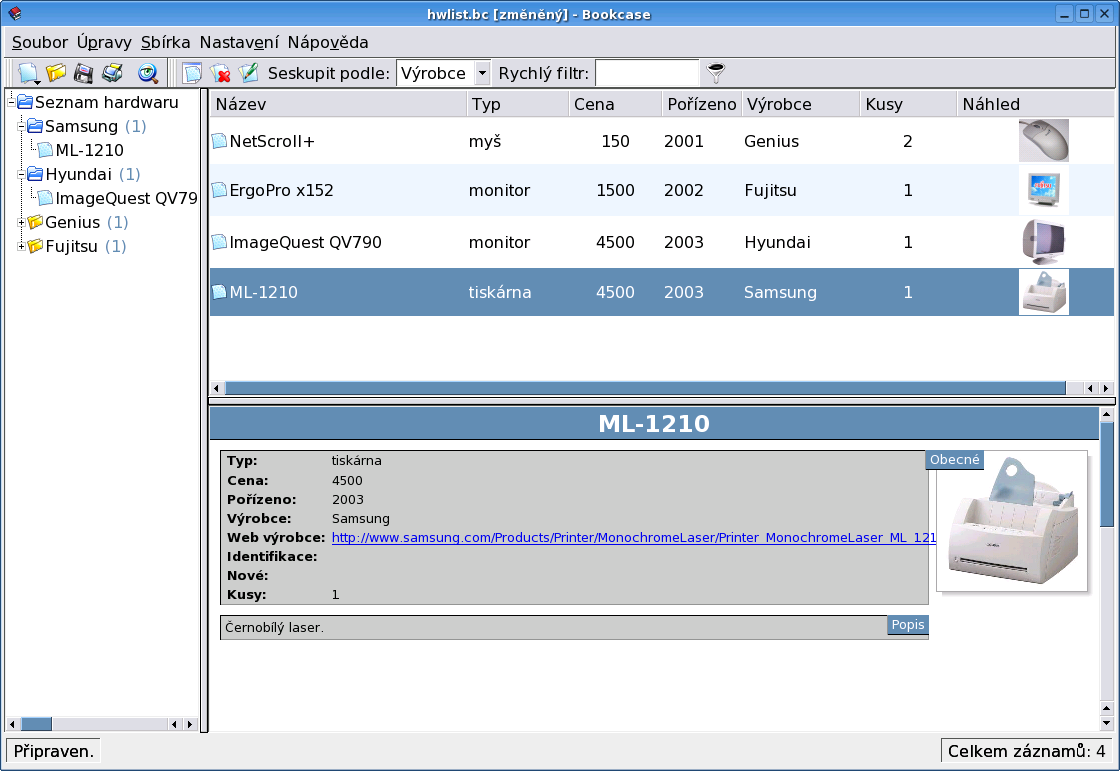
Kliknutím pravým tlačítkem myši na hranu horní části okna vybereme pole, která se mají zobrazit - zde máme Název, Typ, Cena, Pořízeno, Výrobce, Kusy, Náhled. Kliknutím na některé z nich jej zvolíme jako klíč řazení pro tuto část okna (levý sloupec zůstává). Kliknutím na některou položku zobrazíme její obsah v dolní části okna (zde tiskárna). Také zde lze použít filtr, a to dokonce vícepodmínkový či filtr na část výrazu. Pojďme k nastavení programu.
Na kartě 'Obecné' můžeme ovlivnit možnosti formátování, zejména výrazy označující členy (the, der), osobní přípony (ml., jr.) a části příjmení (von, van, de, van der, la apod.).
Karta 'Tisk' ovlivňuje výsledný vzhled karty - přítomnost hlaviček, velikost náhledů.
Další důvtipný zlepšovák. U každého typu sbírky lze zvolit šablonu (jedná se o XSL), podle které se zobrazuje obsah položky v dolní části okna. Existuje pět základních šablon, ne všechny lze použít pro každou sbírku (např. pro video je speciální). Pro náš seznam hardwaru můžeme použít Compact, Fancy, nebo Default.
Několik málo voleb pro BibTeX, program, kterým lze zpracovávat bibliografické citace (a následně je integrovat do dokumentu LaTeXu).
Export funguje do XML, HTML, CSV (údaje oddělené zvoleným oddělovačem, např. středníkem), PilotDB a souboru BibTeXu. Také existuje velice flexibilní možnost exportovat data přes vlastní XSL šablonu, což je teprve to nejlepší.
HTML export lze ovládat několika parametry, při použití všech voleb se vytvoří základní stránka, z níž vedou odkazy na záznamy jednotlivých zařízení. K dokonalosti ale chybí navigace. Ukázka (.tar.bz2).
Importovat lze soubor Bookcase, pokud má stejnou strukturu, jinak řečeno, používá-li stejné DTD. Dále CSV, což je praktické, máme-li seznam knih např. ve formátu
autor; název knihy
|
Oddělovač lze samozřejmě zvolit. Struktura souboru musí podle mé dosavadní zkušenosti přesně souhlasit se strukturou naší sbírky.
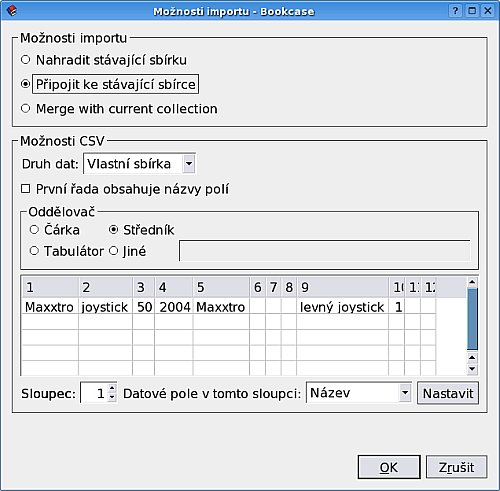
Každému Sloupci je nutné přiřadit Datové pole - postupným klikáním na oba prvky. Pole jsou samozřejmě ta, která jsme definovali ve své sbírce. Stejně jako exportovat lze také importovat BibTeXové soubory a soubory prostřednictvím XSL šablony.
Aplikace na mě působí (snad oprávněně) opravdu dobrým dojmem - využívá
XML a spřízněné technologie, kde to jen jde. Autor dokonce (což mě opravdu
překvapuje) počítá s tím, že si uživatelé budou připodobňovat XSL šablony
pro různé výstupy. Lze tedy upravit stávající šablony pro své účely.
Základní se nacházejí v adresáři $KDEHOME/share/apps/bookcase,
šablony pro definici vzhledu spodní části okna (detaily vybrané položky)
jsou v podřízeném adresáři entry-templates. Tam tedy najdeme
šablony, o kterých jsem mluvil v sekci Nastavení/Šablony. Kdo rozumí, poradí
si. Součástí šablon jsou CSS sekvence, ty lze tedy - asi jako nejjednodušší
věc - změnit.
Mezi šablonami se nalézá i šablona pro tisk výstupů. Standardní vzhled není nijak uchvacující, proto je na místě jej trochu upravit. To už se ale pohybujeme na jiném poli, takže se úpravě XSLT nebudeme podrobně věnovat.
Program mě potěšil - je dobře navržený, schopný, rozšiřitelný, praktický, intuitivní. Má sice nějaké nedodělky, ale to se jistě změní. Myslím si, že jej lze bez problému používat pro uspořádání domácích sbírek všeho druhu. Ačkoliv se Rober Krátký snažil, lokalizace není kompletní, což působí rušivě. Našel jsem ale další praktický program, kterému svěřím svá poctivě a dlouho vkládaná data.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Diskuse byla administrátory uzamčena
 Dulezita jsou totiz ta data, nikoliv program.
Dulezita jsou totiz ta data, nikoliv program.
 A možnost přímočarého generování výstupů přes XSL je k nezaplacení.
Zajímavější mi ale stejně přijde Open Media Lending Database - (SQL, PHP -> Web), mít něco doma jen tak na desktopu nic moc...
A možnost přímočarého generování výstupů přes XSL je k nezaplacení.
Zajímavější mi ale stejně přijde Open Media Lending Database - (SQL, PHP -> Web), mít něco doma jen tak na desktopu nic moc...
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz