Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »
Tento zápisek volně navazuje na víc jak dva roky starý (ten čas ale letí...) článek Škálování quadcore při kompilaci jádra. Nevím kdy přesně v jádře přibyla volba pro hotplugování procesorů, každopádně nyní tam je a to nám umožňuje snadno emulovat počítač s méně jádry a docílit tím přesnějšího srovnání. Z hlediska CPU se změnilo za ty dva roky poměrně málo- stále zde máme čtyřjádrové procesory, frekvence se nehla ani o píď a zlepšení v architektuře nejsou ani na straně intelu (Nahalem) ani AMD (novější Phenomy) ničím, kvůli čemu by musel člověk sbírat čelist z podlahy. Snad jen servery s 2x čtyřjádrovými procesory jsou nyní častějším jevem, na desktopu to je ale relativně vzácnost.
2x X5482 (3.2 GHz), tyto procesory jsou více známy pod názvem Core 2 Extreme QX9775, protože pod tímto značením se prodávaly v Intel SkullTrail sestavách, 16 GiB DDR2 800 MHz FB DIMM
Jádro 2.6.31.5, vanilkové. gcc 4.3.4
Metodika se od minula nijak nezměnila akorát jsem neměřil kompilaci jádra se všemi volbami, neboť časy byly příliš dlouhé a já potřeboval provést spoustu měření. Použil jsem tedy .config jádra, které běžně používám. Pro simulaci počítače s méně jádry jsem použil "hotplug"
echo 0 > /sys/devices/system/cpu/cpuN/online //místo N se dosadí číslo jádra
kernel z něho odmigruje všechny procesy, zamorduje příslušné kernel thready a snad i přepne do nějakého úsporného režimu. Pro systém dané jádro přestane existovat, není ani v /proc/cpuinfo. Starší metodou je předání jádru parametru maxcpus při bootu a ještě starší omezení počtu procesorů v .config. Ne-SMP jádra, tedy s efektivnějšími implementacemi některých zámků, se už dneska v žádné distribuci nevyskytují ale ta volba v konfiguraci jádra stále je. Záměrně jsem tedy vynechal měření "jednojádra".
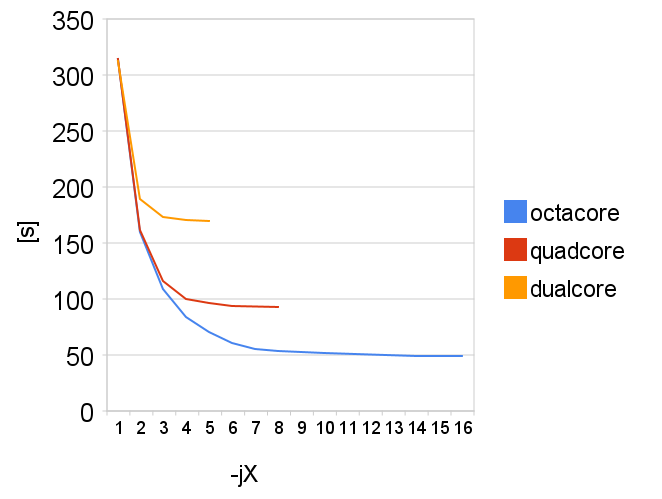
graf říká vše  Opticky se zdá, že osmijádro oproti čtyřjádru nedává výrazně lepší výsledky ale je to jen optický klam, osmijádo zvládne kompilaci 1.87x rychleji. Celkově vzato kompilace jádra škáluje velmi pěkně. Docela by mě zajímalo, jak by vypadala situace na i7 procesoru s aktivovaným hyperthreadingem.
Opticky se zdá, že osmijádro oproti čtyřjádru nedává výrazně lepší výsledky ale je to jen optický klam, osmijádo zvládne kompilaci 1.87x rychleji. Celkově vzato kompilace jádra škáluje velmi pěkně. Docela by mě zajímalo, jak by vypadala situace na i7 procesoru s aktivovaným hyperthreadingem.
Zajimavé poznatky přináší ješte hodnota user+sys, jinými sklovy kolik času procesory skutečně "odedřou". ta roste z 317 vteřin při -j1 lineárně k 350 při -j16. Jinými slovy o celých 33 vteřin práce procesoru příjdeme kvůli tomu, že se procesy točí ve spinlocku, počítají pomaleji kvuli tahanici o paměťovou sběrnici a L2 cache.
Pokud od rána do večera neděláte nic jiného, než že kompilujete jádo, tak běžte pro osmijádrový počítač. Pozor, tento test říká právě to a nic jiného. Vyvozování jakýchkoliv dalších závěrů jen na vlastní nebezpečí.

Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 28.10.2009 16:01
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
28.10.2009 16:01
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
 Ale pěkné, je vidět, že pres make se dají věci pěkně paralelizovat.
Ale pěkné, je vidět, že pres make se dají věci pěkně paralelizovat.
 28.10.2009 16:28
Nicky726 | skóre: 56
| blog: Nicky726
28.10.2009 16:28
Nicky726 | skóre: 56
| blog: Nicky726
 28.10.2009 16:30
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
28.10.2009 17:09
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
28.10.2009 18:49
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
28.10.2009 16:30
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
28.10.2009 17:09
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
28.10.2009 18:49
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
S(N) = 1/((1 - P) + (P / N)), kde P je cast algoritmu, ktera musi bezet sekvencne a N je pocet procesoru.
problem je, ze P nemusi byt konstanta. hodnota P je dana vstupnimi daty. coz je vicemene intuitivni, ma cenu paralelizovat velke ukoly nez male. a taky a to je hlavni, jsou pripady kdy P je funkci N... coz meni vyzneni celeho ,,zakona'', i.e., jde dosahnout linearniho i super-linearniho zrychleni! to znamena, ze v nekterych pripadech jde treba na dvoujadrovem procesoru dosahnou 10x zrychleni.
na druhou stranu, v pripade parallelniho programovani je potreba prehodnotit cely pristup k navrhu algoritmu a programu... protoze zkusenosti ze sekvencnich algoritmu jsou v pripade parallelnich algoritmu vicemene k nicemu.
Ale tady asi ani to ne páč 10x zrychlení na dvoujádru to ned8 ani backpruning, to je něco naprosto z jine galaxie řekl bych
vysoké školství produkuje praxií nepolíbené teoretiky-idealisty:-]]
to je něco naprosto z jine galaxie řekl bychto je jasne... svuj notas jsem koupil od dvou ferengu pri ceste po gama-kvadrantu! puvodne jsem ho ani nechtel, ale nakonec jsem se nechal ukacat. :-]
Ale tady asi ani to ne páč 10x zrychlení na dvoujádru to ned8 ani backpruning,takze taky teoretik? v praxi lze dosahnout superlinearniho zrychleni i s ,,beznyma parallelnima'' programama. staci si uvedomit, ze realny program nepouziva jenom CPU... a nadesignovat pak experiment, kde vyjde desetinasobne zrychleni na dvoujadru je uz jenom otazka cviku a trochy praxe. ;-]
To není k smíchu s tím školstvím, já jsem také jeho produktem, vím o čem mluvím
Tak mi nějaký takový experiment vycházejiící z praxe na reálném hardware a ne z akademického myšlenkového pokusu ukaž. Už jsem viděl i pokus o naprosto vyumělkované vytvoření algoritmu, který sázel na to, že se jeho working set vejde do L2 procesorů při rozdělení na víc části ale jako celek ne. Teoreticky vysněný případ. V praxi byl zisk jen nějakých 60 % páč se nepočítalo s n-asociativitou cache v reálných procesorech takže docházelo k přecpání některých řádků a na tom to celé zvadlo.
To není k smíchu s tím školstvím, já jsem také jeho produktem, vím o čem mluvímja jsem se smal necemu uplne jinemu... :-]]
Tak mi nějaký takový experiment vycházejiící z praxe na reálném hardwarevezmi si nejaky program a do jeho vlaken si pridej parkrat volani sleep(). uvidis, jaky to bude mit vliv na skalovani. ted si vem ten program a misto volani sleep si tam domysli, cekani na diskove I/O, cekani na sit, atd. bohuzel, z jistych duvodu nemuzu byt konkretnejsi...
Tak tim jsi to zabil naprosto.to si jen myslis, nebo jsi to i zkousel? na I/O se musi cekat za vsech okolnosti v sekvencni i nesekvencni variante. jenomze v pripade nesekvencni varianty, zatimco jeden proces ceka na vyrizeni I/O, dalsi muze vyuzivat procesor. jeste bych mel dodat, ze aby to fungovalo (mimo amdahluv zakon) je potreba, aby pocet procesu byl vetsi nez procesoru.
Pořád to v tom nevidím.pointa je v tom, ze I/O se zacne chovat jako dalsi procesor. vezmi si jako trivialni pripad treba jednoprocesorovy stroj s dvema vlaknama, kdy se musi stridave cist a zpracovavat data... zatimco jedno vlakno cte data (nepotrebuje procesor), druhe pracuje... takze uloha skaluje i kdyz by vlastne nemela.
Což takhle ukázka, do kostry pthreads aplikace napasovat nejskou simulaci výpočtu a IO a počítadlo iterací... půl hodinky. Nebo alespoň odkaz na něco, co takhle krásně škáluje.zkus si to naprogramovat sam, hint jsem dal vys. ja uz jsem touto diskuzi zabil vic casu nez je zdravo. a taky diskuzi o tom, ze ten a ten priklad neni optimalni nebo ze neodpovida realite jsem si uzil uz vic nez dost.
 28.10.2009 19:26
default | skóre: 22
| Madrid
28.10.2009 16:33
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
28.10.2009 19:26
default | skóre: 22
| Madrid
28.10.2009 16:33
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
 29.10.2009 01:17
vlk | skóre: 23
| blog: u_vlka
29.10.2009 01:17
vlk | skóre: 23
| blog: u_vlka
pdflush), mohou běžet na volných procesorech, takže nejen že neubírají procesorový část uživateslkým procesům, ale ješte se ušetří režie přepínání úloh na procesoru (uložení a načtení všech registrů, prohozeni TSS+LDT a pod.).
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz