Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
26.6.2007 20:38
| Přečteno: 1859×
| Programování
|  | poslední úprava: 27.6.2007 12:25
| poslední úprava: 27.6.2007 12:25
pred casem tu probehl tradicni flame na tom jaka licence je nejlepsi... je mi to uprime jedno... ale spis jsem si rikal, ze uz jsem dlouho nic "rozumneho" "nevyprodukoval".
nicmene, jelikoz uz pres rok programuju jako diplomku implicitne paralelni implementaci schemu (viz zatim nedokonceny serial) a vzhledem k tomu, ze obhajoba se blizi milovymi kroky... tak uz to zacina byt i pouzitelne. pokud mate tedy zajem -- studujte, kompilujte, uzivejte -- schemik-0.5.0.tar.bz2 (pro ty co by zajimala licence... spravna odpoved zni: "MIT")
update - pro upresneni: implicitne paralelni interpretr se chova jako kazdy jiny interpretr s tim rozdilem, ze dokaze beh kodu rozdelit do vice samostanych vlaken a vratit stejny vysledek (jako normalni interpretr), bez toho aniz by bylo nutne nejak menit kod, resit vlakna, synchronizaci, atp. samozrejme, aby to bylo uzitecne je potreba mit viceprocesorovy pocitac.
jedine co potrebujete je nejaky hezky SMP stroj, unixovy os s GNU nastroji a trocha znalosti schemu. a hlavne napsat make
pouzivani je proste jak bulharska stripterka:
spusti repl s danym poctem vlaken:./schemik -t <pocet-vlaken>provede prikaz s danym poctem vlaken:
./schemik -t <pocet-vlaken> -c "(display (+ 1 1))"provede progvram s danym poctem vlaken:
./schemik -t <pocet-vlaken> -s scm/quicksort.scm
time ./schemik -t 0 -q -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m2.782s user 0m2.772s sys 0m0.012s30. fibbonacciho cislo s peti vlakny
time ./schemik -t 4 -q -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m1.410s user 0m4.596s sys 0m0.160ssetrideni 100000 pseudonahodnych cisel quicksortem a jednim vlaknem
time ./schemik -t 0 -s scm/quicksort.scm real 0m26.475s user 0m26.418s sys 0m0.056ssetrideni 100000 pseudonahodnych cisel quicksortem a sesti vlakny
time ./schemik -t 5 -s scm/quicksort.scm real 0m15.592s user 0m27.774s sys 0m2.152s
zatim skoro zadna, ale pracuje je se na ni! vzhledem k memu sveraznemu lingvistickemu citeni bude az po korekturach. ;-]
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 26.6.2007 21:16
freshmouse | skóre: 42
| blog: Bruno Banány
26.6.2007 21:16
freshmouse | skóre: 42
| blog: Bruno Banány
 26.6.2007 21:52
David Watzke | skóre: 74
| blog: Blog...
| Praha
26.6.2007 21:52
David Watzke | skóre: 74
| blog: Blog...
| Praha

$ time ./schemik -t 0 -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m3.435s user 0m3.191s sys 0m0.047s $ time ./schemik -t 1 -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m3.464s user 0m3.150s sys 0m0.056s $ time ./schemik -t 5 -c "(define (fib x) (if (< x 3) 1 (+ (fib (- x 1)) (fib (- x 2))))) (display (fib 30))" 832040 real 0m3.589s user 0m3.242s sys 0m0.082sA to se vyplatí
Každopádně seš těžkej šéf, obdivuju tě.
(lambda (n) (+ (fib (- n 1)) (fib (- n 2))) to rozlozi na operace +, (fib (- n 1)) a (fib (- n 2))... aby mohl provest soucet zjisti, ze je potreba pocitat (fib (- n 1)) tak jej zacne pocitat... kdyz planovac zjisti, ze se to pocita nejak dlouho podiva se, jestli by neslo neco vypocitat v novem vlakne... a zjisti ze by mezi tim mohl spocitat (fib (- n 2))... tak to spocita...
cele je to reseno pomoci upraveneho zasobnikoveho modelu od doc. vychodila, palacky university ;-], kterym trapil prvaky. (slibil jsem, ze budu uvadet kredity a odkazy na "nase pracoviste" ;-])
...cast jednovlaknoveho vyhodnocovani je popsana tady, popr. v originalni slidech ...krome toho, ze tento model je strasne jednoduchy a pomaly, jde v nem prave velice snadno delit vypocet do vlaken a ovladat jeho prubeh v case... vcetne krasnych veci jake je call/cc
Although the order of evaluation is otherwise unspecified, the effect of any concurrent evaluation of the operator and operand expressions is constrained to be consistent with some sequential order of evaluation. The order of evaluation may be chosen differently for each procedure call.moje implementace vyhodnocuje vsechny vyrazy z leva doprava, jako rada "prumyslovych" interpretru a prekladacu a snazi se vracet stejne vysledky. ale zastavim se nachvilku u tech side-effectu, protoze s nima je to slozitejsi. jednou z vlastnosti je, ze funkci se side effectem muze provadet hlavni vlakno vypoctu, pokud se objevi nejaky side-effect v pomocnem vlakne je zastaveno (a rozpocitany stav si v budoucnu prebere hlavni vlakno). napr.
(let ((foo (lambda () (display "aaa")))) (foo) (display "bbb") #f)pokud by napriklad pomocne vlakno chtelo vyhodnotit
(display "bbb") ma smulu, protoze nejdriv musi byt vyhodnoceny vsechny vyrazy pred nim.... co kdyby (foo) obsahovalo nejaky dalsi side-effect.
se set! je to jeste slozitejsi.... krome toho, ze ma side-effect, tak nepekne ovlivnuje beh aplikace.
(define global 1) (let () (foo) (set! global 2) (+ global (bar)))pokud by
(foo) a (bar) byly pomale funkce mohl by nastat stav, ze by se treba vyhodnotil vyraz (+ global (bar)) driv nez by se provedlo vyhodnoceni (set! global 2) a diky tomu by se vratil chybny vysledek. tento problem resim tak, ze pokud za operaci typu set! jsou nejaka pomocna vlakna s rozpocitanymi vysledky, tak jsou nemilosrdne zahozena a musi pocitat od znovu -- ano je to plýtvani, ale da se tomu vcelku uspesne branit v planovaci, ktery nepovoli spustit paralelni vypocet za operaci set!
jenom jeste doplnim dva bonbonky, ktere me docela prakvapily -- vstupni funkce napr. (readline) a escape funkce z call/cc maji stejne chovani jako funkce se site-effectem... kdo by to cekal? ;-]
(labels ((a 'a) (b 'b))
(foo
(lambda (print "a: ") (print a))
(lambda (print "b: ") (print b))))
by asi nemělo vypsat a: b b: a.
Což mi přijde při takovéhle implementaci jako problém, protože pokud přidání ladicích výstupů způsobí změnu dělení na streamy, tak si moc nepoladím...
(define (fib-iter a b n)
(if (= n 0) a
(fib-iter b (+ a b) (- n 1))))
(define (fib n)
(fib-iter 0 1 n))
ale tam by se ztratila ta pointa... urcite to potrebuje vetsi intelektualni zatez pro programtora ;-]
 26.6.2007 22:16
andree | skóre: 39
| blog: andreeeeelog
26.6.2007 22:16
andree | skóre: 39
| blog: andreeeeelog

$ time ./schemik -t 0 -s scm/quicksort.scm ./schemik -t 0 -s scm/quicksort.scm 18.74s user 0.04s system 99% cpu 18.948 total $ time ./schemik -t 1 -s scm/quicksort.scm ./schemik -t 1 -s scm/quicksort.scm 17.85s user 0.12s system 144% cpu 12.471 total
$ time ./schemik -t 5 -s scm/quicksort.scm ./schemik -t 5 -s scm/quicksort.scm 19.59s user 0.12s system 136% cpu 14.475 total $ time ./schemik -t 1 -s scm/quicksort.scm ./schemik -t 1 -s scm/quicksort.scm 17.82s user 0.13s system 134% cpu 13.393 total
./schemik -t 5 -s scm/quicksort.scm 19.83s user 0.16s system 138% cpu 14.417 total ./schemik -t 1 -s scm/quicksort.scm 18.06s user 0.12s system 136% cpu 13.313 total ./schemik -t 1 -s scm/quicksort.scm 17.88s user 0.14s system 135% cpu 13.305 total ./schemik -t 5 -s scm/quicksort.scm 19.21s user 0.16s system 142% cpu 13.552 total
(+ (fib (- n 1) (fib (- n 2)) kazde cislo si muze pocitat samostatne vlakno aniz by se nejak ovlivnovali....
tento zpusob vypoctu je fakt hloupy a jde bez problemu prepsat do koncovych volani, kde se budou predavat jiz spocitana cisla.... algoritmus to bude pak velice efektivni... ale neparalelizovatelny....
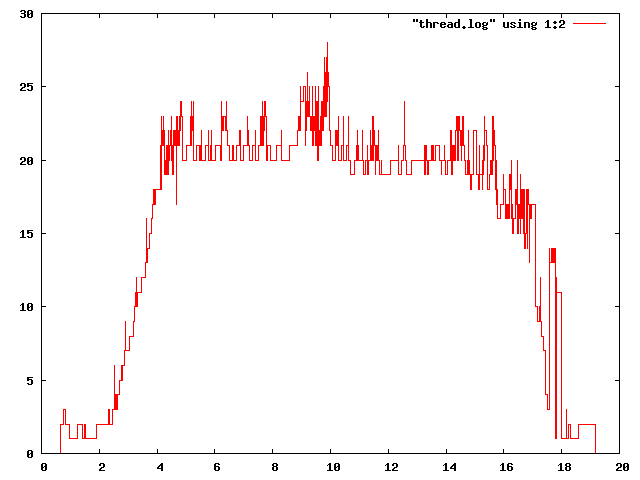
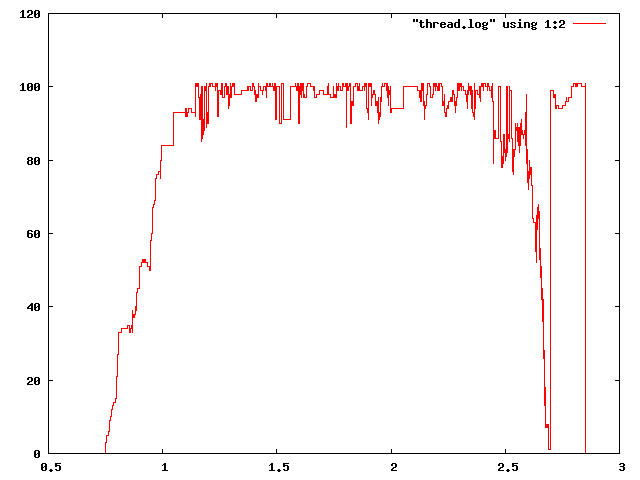
jenom pro zajimavost -- kdyz dam "planovaci" volnou ruku a povolim mu 100 vlaken, aby ukazal jak moc jde uloha paralelizovat, tak u fibonaciho cisla vyuzije skoro vsechny, kdezto u quicksortu ma problemy. (btw paralelizovatelnost ulohy je dana nejen typem algoritmu, ale i vstupnimi hodnotami)
 27.6.2007 12:48
nooneanymore | skóre: 14
| blog: Smazano
27.6.2007 12:48
nooneanymore | skóre: 14
| blog: Smazano
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}
{kind=link}