Na čem aktuálně pracují vývojáři GNOME a KDE Plasma? Pravidelný přehled novinek v Týden v GNOME a Týden v KDE Plasma.
Před 25 lety zaplavil celý svět virus ILOVEYOU. Virus se šířil e-mailem, jenž nesl přílohu s názvem I Love You. Příjemci, zvědavému, kdo se do něj zamiloval, pak program spuštěný otevřením přílohy načetl z adresáře e-mailové adresy a na ně pak „milostný vzkaz“ poslal dál. Škody vznikaly jak zahlcením e-mailových serverů, tak i druhou činností viru, kterou bylo přemazání souborů uložených v napadeném počítači.
Byla vydána nová major verze 5.0.0 svobodného multiplatformního nástroje BleachBit (GitHub, Wikipedie) určeného především k efektivnímu čištění disku od nepotřebných souborů.
Na čem pracují vývojáři webového prohlížeče Ladybird (GitHub)? Byl publikován přehled vývoje za duben (YouTube).
Provozovatel čínské sociální sítě TikTok dostal v Evropské unii pokutu 530 milionů eur (13,2 miliardy Kč) za nedostatky při ochraně osobních údajů. Ve svém oznámení to dnes uvedla irská Komise pro ochranu údajů (DPC), která jedná jménem EU. Zároveň TikToku nařídila, že pokud správu dat neuvede do šesti měsíců do souladu s požadavky, musí přestat posílat data o unijních uživatelích do Číny. TikTok uvedl, že se proti rozhodnutí odvolá.
Společnost JetBrains uvolnila Mellum, tj. svůj velký jazykový model (LLM) pro vývojáře, jako open source. Mellum podporuje programovací jazyky Java, Kotlin, Python, Go, PHP, C, C++, C#, JavaScript, TypeScript, CSS, HTML, Rust a Ruby.
Vývojáři Kali Linuxu upozorňují na nový klíč pro podepisování balíčků. K původnímu klíči ztratili přístup.
V březnu loňského roku přestal být Redis svobodný. Společnost Redis Labs jej přelicencovala z licence BSD na nesvobodné licence Redis Source Available License (RSALv2) a Server Side Public License (SSPLv1). Hned o pár dní později vznikly svobodné forky Redisu s názvy Valkey a Redict. Dnes bylo oznámeno, že Redis je opět svobodný. S nejnovější verzí 8 je k dispozici také pod licencí AGPLv3.
Oficiální ceny Raspberry Pi Compute Modulů 4 klesly o 5 dolarů (4 GB varianty), respektive o 10 dolarů (8 GB varianty).
Byla vydána beta verze openSUSE Leap 16. Ve výchozím nastavení s novým instalátorem Agama.
Aktuální předverze je i nadále 2.6.24-rc2. Od vydání -rc si už do hlavního git repozitáře našlo cestu docela dost patchů; jde především o opravy, ale probíhá i práce na podpoře CIFS ACL a odstraňování několika zastaralých dokumentů. -rc3 by měla vyjít velmi brzy.
Aktuální verze -mm stromu je 2.6.24-rc2-mm1 - první -mm od 2.6.23-mm1, která vyšla 11. října. Mezi nedávné změny patří aktualizace mapovače zařízení, velká aktualizace stromu ovladačů (kvůli které přestalo dost věcí fungovat), hodně aktualizací IDE, podpora dvousměrového SCSI, velká sada oprav SLUBu a další patche z oblasti správy paměti ["mammary manglement"], podpora kvalifikací na 64 bitech, několik vylepšení ext4 a začlenění vývojového stromu PCI hotplug.
V rámci oznámení 2.6.24-rc2-mm1 Andrew Morton zmínil, že někteří lidé chtějí ještě aktuálnější jádro, než může nabídnout -mm, a proto vytvořil -mm of the minute tree, který je aktualizován několikrát denně. Pokusím se dávat pozor na to, aby ty patche šly aplikovat, ale na beton nebude možné je všechny zkompilovat a spustit. Strom bude exportován jako série patchů, takže abyste z toho dostali něco, co by bylo možné kompilovat, budete potřebovat Quilt. Dobře se bavte.
Jsem přesvědčen, že bychom měli o hodně kvalitnější jádro, kdyby existoval jeden centrální mailing list místo těch elitářských a rozdrobených konferencí. Každé téma by bylo globálně na očích a bylo by velmi snadné zainteresovat i další lidi z jiných subsystémů.
-- Ingo Molnár
Pokud to není nahlášeno na linux-scsi, je dost velká pravděpodobnost, že si takové zprávy o chybě nevšimneme. Skutečnost, že si někteří lidé všimnou bugů hlášených v LKML, a přepošlou je do linux-scsi, je šťastná shoda náhod, na kterou by se nemělo spoléhat.
LKML je asi 10 - 207× frekventovanější než linux-scsi, ale je tam mnohem větší poměr odpadu k tématu. Když máme specializovaný mailing list, který sledují všichni experti, tak to v důsledku zvyšuje naši schopnost opravovat chyby.
Diskuze o kvalitě jádra nejsou v linux-kernel žádnou novinkou. Je to téma, které se objevuje pravidelně, a to více než u jiných projektů svobodného softwaru. Velikost jádra, rychlost změn kódu a velká různorodost prostředí, kde je jádro nasazováno, jsou všechno faktory, které vedou k unikátním problémům; připočtěte skutečnost, že chyby v jádře mohou vést ke katastrofickým selháním, a máte materiál pro nekonečnou debatu.
Zatím poslední kolo začalo, když Natalie Protasevich, vývojářka ze společnosti Google, která pomáhá Andrew Mortonovi sledovat bugy, poslala seznam několika desítek otevřených chyb, jež by si zasloužily další pozornost. Andrew odpověděl, jak se na dění kolem těchto hlášených chyb dívá on; ve většině případů to bylo "žádná odezva vývojářů":
Napočítal jsem asi sedm hlášení, kterými se někdo zabývá. Dvacetsedm je zatím ignorováno.
Několik vývojářů reagovalo v tom smyslu, že je Andrew příliš přísný a ne vždy má v těchto věcech pravdu. Ať už má, nebo nemá pravdu, Andrewa tato diskuze zjevně vyprovokovala.
Své tvrzení obhajoval tím, že vytáhl na světlo často opakovanou obavu o horšící se kvalitě jádra. To je podle něj záležitost, která si zaslouží okamžitou pozornost:
Pokud se jádro _opravdu_ zhoršuje, pak to nebude jen tak jasné, dokud to nebude trvat několik let. A pak by už bylo práce tolik, že návrat na přijatelnou úroveň by znamenal opravdu velké úsilí. A jádru by pak také velmi dlouho trvalo, než by si napravilo pověst.
Ale zhoršuje se opravdu kvalita jádra? Na to se odpovídá velmi těžko. Neexistuje žádný objektivní standard, podle kterého by šlo jádro posuzovat. Některé druhy problémů lze odhalit automatickým testováním, ale v jaderném prostoru se mnohé bugy projeví až při nasazení s určitými zátěžemi na konkrétní hardwarové kombinaci. Stoupající počet hlášení o chybách ještě nemusí znamenat horší kvalitu, když se zvyšuje počet uživatelů i velikost kódu.
Podobnou argumentaci použil Ingo Molnár, který poukázal na to, že méně hlášení o chybách nemusí značit zlepšování kvality. Místo toho by to mohlo znamenat, že testeři začínají být otrávení a vývojového procesu už se neúčastní - zhoršující se kvalita by tak vlastně mohla vést k tomu, že bude nahlášeno méně chyb. Proto Ingo připomíná, že musíme být vstřícnější k testerům, ale zároveň se i více snažit o opravdové měření kvality jádra:
Snažil jsem se poukázat na to, že se musíme oprostit od našeho současného subjektivního přístupu k posuzování kvality a přinejmenším si uvědomit, jak z vrchu se díváme na QA. Jakmile budeme schopni _změřit_, jak špatně si vedeme, vývojáři jádra se přizpůsobí a napraví to. Používejme tedy více debugovacích nástrojů, jak statických, tak dynamických. Také bychom měli měřit, kolik je testerů, a musíme měřit, kolik uživatelů, kteří začali používat nějakou vlastnost hned po uvedení, s tím zase seklo, a proč.
Obecně je pravda, že problémy, které lze změřit a vyčíslit, bývají vyřešeny rychleji a efektivněji. Klasický příklad je PowerTop, díky kterému jsou problémy se správou napájení jasně patrné. Jakmile měli vývojáři možnost vidět, kde je problém, a především, o kolik jejich opravy situaci zlepšily, tak velký počet chyb zmizel během chvíle. V tuto chvíli mají vývojáři mnoho možností, jak se snažit o zlepšení kvality jádra, ale nemají možnost zjistit, jestli jejich úsilí k něčemu vede, nebo ne. Když není k dispozici objektivní měření, jsou snahy o zlepšování jen tápáním ve tmě.
Jako příklad může posloužit diskuze o funkci "git bisect". Pokud se snažíte vyhledat příčinu regrese, ke které došlo mezi 2.6.23 a 2.6.24-rc1, dalo by se čekat, že budete muset prohlédnout několik tisíc patchů, abyste objevili ten, který potíže způsobil - což je úkol, který většina lidí považuje za poněkud děsivý. Půlení [bisection] testerovi pomůže provést binární hledání v určitém rozsahu patchů přičemž s každou rekompilací a restartem se polovina vyloučí. S pomocí "bisect" lze tedy regresi vystopovat relativně automatickým způsobem při provedení přibližně "pouze" desítky kompilací a restartů. Na konci procesu bude provinilý patch nezvratně identifikován.
Půlení funguje tak dobře, že vývojáři často po testerech požadují, aby vysledovali kořeny problému, který nahlásili. Někteří lidé to považují za způsob, který používají líní vývojáři ke shození práce spojené s vyhledáním svých vlastních bugů na uživatele, kteří tou chybou trpí. Sestavit a otestovat desítku jader je na testery trochu moc velký požadavek. Mark Lord například říká, že většinu bugů je poměrně snadné najít, když se vývojář na kód skutečně podívá; celý proces půlení je často zbytečný.
Na druhou stranu, někteří vývojáři vidí v půlení mocný nástroj, který testerům usnadnil aktivně se na procesu podílet. David Miller napsal:
Podobně jako u Internetu i v tomto případě je takto strávený čas ku prospěchu věci, protože to znamená přesouvání práce na koncové body. Git bisect je ve skutečnosti skvělý příklad principu koncových bodů v akci při vývoji softwaru a QA. Je to výhra pro vývojáře i koncového uživatele, který čeká, až bude jeho bug opraven, protože ten, kdo bug nahlásil, má opravdu možnost se na tom aktivně podílet a pomoci s rychlejším vyřešením.
Zpět k původnímu seznamu bugů: další věc, o které se mluvilo, je používání jiných konferencí kromě linux-kernel. Některé z chyb nebyly řešeny, protože nebyly hlášeny do konferencí zaměřených na daný subsystém. Jiné zase Andrew označil jako bez odpovědi, a přitom se o nich mluvilo (a někdy byly i vyřešeny) v těch oddělených konferencích. V obou případech za to může nedostatečná komunikace mezi konferencemi subsystémů a širší komunitou.
V reakci na to někteří vývojáři začali (opět) požadovat, aby se subsystémové konference používaly méně. Tvrdí, že když všichni pracujeme na stejném jádře, takže chceme všichni vědět, co se se ním děje. Debatování o subsystémech na oddělených konferencích povede k nižší kvalitě jádra. Ingo Molnár to vyjádřil takto:
Nucenou izolací diskuzí ztrácíme mnohem více než získáváme tím, že do konference přijde méně mailů. Je _MNOHEM_ snazší informace filtrovat (podle vláken, témat, lidí atd.), než je shromažďovat z více zdrojů. Znovu a znovu se ukazuje, že izolace diskuzí o jádře vede k problémům.
Přesun diskuzí zpět do linux-kernel by však šlo prosadit jen těžko. Většina subsystémových konferencí má menší množství zpráv, přátelštější atmosféru a diskutuje se tam více k věci. Většina těch, kteří jsou členy takových konferencí, nebude mít pocit, že by jim přesun zpět do linux-kernel nějak usnadnil život. Nezbývá než doufat, že se více vývojářů přihlásí do obou a pohlídají, aby oběma směry proudily relevantní informace.
David Miller připomněl, proč se některým chybám nedostává tolik pozornosti: vývojáři si musejí vybrat, kterými chybami se budou zabývat. Problémy, které postihují hodně uživatelů a které je snadné reprodukovat, daleko snadněji upoutají vývojářovu pozornost. Hlášení o chybách, které skončí na konci seznamu priorit ("plívy" [chaff]), mají tendenci tam zůstat dlouho. David však říká, že takový systém funguje poměrně dobře:
Naštěstí je to tak, že když to ignorované hlášení není plíva, objeví se znovu (a znovu a znovu), což způsobí změnu priorit, protože nejenže už to není plíva, ale ještě je k tomu k dispozici mnohem více informací, takže je dvojnásob zajímavé se tím zabývat.
Vzhledem k tomu, nakolik je nepravděpodrobné, že by kdy bylo dost vývojářů na to, aby mohli zareagovat na každé hlášení o chybě, vězí hlavní problém ve stanovování priorit. Andrew Morton má jasnou představu o tom které chyby by měly být řešeny nejdříve: regrese oproti předchozím verzím.
Pokud bychom byli opravdu aktivní při likvidaci regresí, pak myslím, že bychom si mohli být jisti, že se kvalita jádra nezhoršuje. Pravděpodobně se bude spíš zlepšovat, protože také opravíme některé dlouhodobé chyby.
Regresím se za poslední dva roky začalo věnovat mnohem více pozornosti. Jsou aktivněji sledovány a před vydáním nových verzí se kontrolují seznamy známých regresí. Největší potíž je podle Andrewa v tom, že regrese, které zůstanou i po vydání nové verze, často ze seznamu vypadnou. Kdyby se dával větší pozor i na tyto problémy, kvalita jádra by se časem zlepšovala.
Jednou z největších výhod víceprocesorových počítačů je skutečnost, že je hlavní paměť dostupná všem procesorům v systému. Tato schopnost sdílet data dává programátorům spoustu volnosti. Jednou z prvních věcí, kterou se tito programátoři naučí (nebo by se měli naučit), je však to, že sdílení dat mezi procesory by se měli za každou cenu vyhýbat. Sdílení dat - obzvláště dat, která se mění - způsobuje všelijaké nepěknosti s keší a velmi snižuje výkon. Nedávno dokončená série What every programmer should know about memory se těmto problémům věnuje velmi podrobně.
Během let se vývojáři jádra snažili co možná nejvíce využívat dat jednotlivých procesorů [per-CPU data], aby se minimalizovalo soupeření o paměť a související dopad na výkon. Jako jednoduchý příklad si můžete představit statistiky o diskových operacích, které udržuje bloková vrstva. Navyšování globálního čítače při každé diskové operaci by způsobilo, že by příslušný řádek keše [cache line] neustále lítal mezi procesory; operace s diskem jsou dost časté na to, aby byl dopad na výkon měřitelný. Takže si každý procesor udržuje svůj lokální čítač; nikdy tak nemusí s ostatními procesory soupeřit o jeho navýšení. Když je potřeba celkový počet, všechny čítače jednotlivých procesorů se sečtou. Vzhledem k tomu, že jsou čítače dotazovány daleko méně často než navyšovány, ukládání počtů pro jednotlivé procesory přináší výrazné výkonnostní zlepšení.
V současných jádrech je většina těchto proměnných u jednotlivých procesorů spravována pomocí pole ukazatelů. Takže například struktura kmem_cache (kterou implementuje SLUB alokátor) obsahuje pole:
struct kmem_cache_cpu *cpu_slab[NR_CPUS];
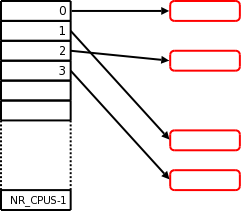
Všimněte si, že je pole dimenzováno tak, aby mohlo mít jeden ukazatel pro každý případný procesor v systému. Většina nasazených systémů však má méně než maximální počet procesorů, takže obecně není důvod pro dané pole alokovat NR_CPUS objektů. Místo toho jsou zaplněny jen ty položky pole, které odpovídají existujícím procesorům; pro každý z nich je alokován potřebný objekt pomocí kmalloc() a uložen do pole. Výsledkem je pole, které vypadá asi jako diagram vpravo. V tomto případě byly alokovány objekty pro čtyři procesory, přičemž zbývající položky pole zůstávají nealokovány.
Letmý pohled na diagram však okamžitě ukazuje jeden potenciální problém tohoto schématu: každé z těchto polí pro jednotlivé procesory bude mít ke konci pravděpodobně nevyužité místo. NR_CPUS je konstanta nastavovaná při konfiguraci; většina jader pro obecné využití (např. ta, která jsou dodávána s distribucemi) mívá NR_CPUS nastaveno tak vysoko, aby jádro fungovalo na většině nebo všech systémech, na které lze narazit. Zkrátka, je velmi pravděpodobné, že NR_CPUS bude o dost vyšší, než je skutečný počet přítomných procesorů.
Christoph Lameter si navíc povšiml, že problémů je ještě více; poslal tedy sérii patchů implementujících nový alokátor pro jednotlivé procesory. Kromě plýtvání místem na konci polí jednotlivých procesorů řeší Christophův patch ještě následující problémy:
Christophovo řešení je v principu docela jednoduché: změníme všechna ta malá pole u jednotlivých procesorů na jedno velké. Při takovém schématu by byl pro každý procesor při inicializaci systému alokován vyhrazený rozsah paměti. Ve virtuálním adresním prostoru jádra by všechny tyto rozsahy byly souvislé, takže mám-li ukazatel na oblast procesoru 0, chybí mi k oblasti kteréhokoliv dalšího procesoru přidání jen jediného ukazatele.
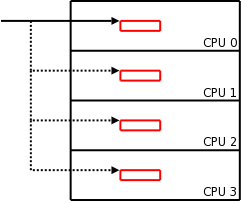
Když je alokován objekt procesoru, dostane každý procesor kopii získanou z jeho vlastní oblasti. Klíčové je, že offset do každé oblasti procesoru je stejný, takže adresa kteréhokoliv objektu procesoru se snadno vypočítá z adresy prvního objektu. Pole ukazatelů je tedy možno nahradit jediným ukazatelem na objekt v oblasti rezervované pro procesor 0. Výsledná organizace vypadá (s dostatečnou dávkou představivosti) asi jako diagram vpravo. Pro daný objekt existuje jen jeden ukazatel; všechny ostatní verze objektu se hledají přidáním konstantního offsetu.
Rozhraní nového alokátoru je relativně přímočaré. Nová proměnná procesoru se vytvoří pomocí:
#include <linux/cpu_alloc.h>
void *per_cpu_var = CPU_ALLOC(type, gfp_flags);
Toto volání alokuje sadu proměnných udaného type, přičemž se pro ovládání toho, jak bude alokace provedena, použije běžné gfp_flags. Ukazatel na specifickou verzi proměnné některého procesoru lze získat takto:
void *CPU_PTR(per_cpu_var, unsigned int cpu);
void *THIS_CPU(per_cpu_var);
THIS_CPU() vrací, jak by se dalo předpokládat, ukazatel na verzi proměnné alokované pro aktuální procesor. K dispozici je makro CPU_FREE(), které systému vrací objekt daného procesoru. Christophův patch konvertuje všechny stávající uživatele rozhraní a pak staré rozhraní odstraňuje úplně.
Tento způsob má několik výhod. Každý přístup k proměnné některého procesoru znamená o jednu operaci s ukazateli méně. Pro všechny procesory se používá jeden ukazatel, což má za následek menší datové struktury a lepší využití řádků keše. Proměnné jednotlivých procesorů jsou v paměti seskupeny, což by mělo také vést k lepšímu využití keše. Získali jsme zpět všechnu paměť vyplýtvanou ve starých polích ukazatelů. Christoph také tvrdí, že tento mechanismus, díky kterému je snazší sledovat paměť jednotlivých procesorů, usnadňuje podporu výměny procesorů za chodu [CPU hotplugging].
O návrhu se zatím moc nediskutovalo. Objevilo se pár připomínek k používání VERZÁLEK pro pojmenování maker. Největší stížnost se však týká toho, že statické oblasti jednotlivých procesorů zaplácávají datový prostor jádra. Na některých architekturách je kvůli tomu jádro tak velké, že nemůže nabootovat, a na všech architekturách je to velká režie. Není jasné, jak bude tento problém řešen. Pokud se však řešení najde, je dost velká šance, že se nový kód dostane do hlavního jádra v rámci vývojového cyklu verze 2.6.25.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 18.12.2007 02:22
Prcek | skóre: 43
| Jindřichův Hradec / Brno
18.12.2007 02:22
Prcek | skóre: 43
| Jindřichův Hradec / Brno
 .
.
ale v jaderném prostoryMůj oblíbený překlep (y/u)
aby vysledovali kořeny problémy
 (Díky za opravy.)
(Díky za opravy.)
Klasický příklad je PowerTop, díky kterému jsou problémy se správou paměti jasně patrné.Jak PowerTop souvisí se správou paměti? Není to spíš správa napájení?
Plevy jsou takový ten bordel z obilí. A plívy sice nevím co je, ale má to přesně ten správný význam - moje babička třeba používala slovo plívy, když dostala do rukou špatné (slabé) karty Prostě plívy jsou něco, co nestojí za řeč. Aspoň u nás na Severní Moravě
 18.12.2007 19:13
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
18.12.2007 19:13
Luboš Doležel (Doli) | skóre: 98
| blog: Doliho blog
| Kladensko
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}