Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »Byla vydána nová verze 1.58 sady nástrojů pro správu síťových připojení NetworkManager. Novinkám se v příspěvku na blogu NetworkManageru věnuje Josephine Pfeiffer. Vypíchnout lze možnost nmtui zobrazit nastavení Wi-Fi jako QR kód nebo podporu CLAT (464XLAT) a tunelů GENEVE (Generic Network Virtualization Encapsulation).
Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Poslední dobou mě velmi zaujal komprimační nástroj lrzip (Long Range ZIP). Dosahuji s ním lepších komprimačních poměrů, než s čímkoliv jiným, a to ne o pár procent, ale často o celé desítky.
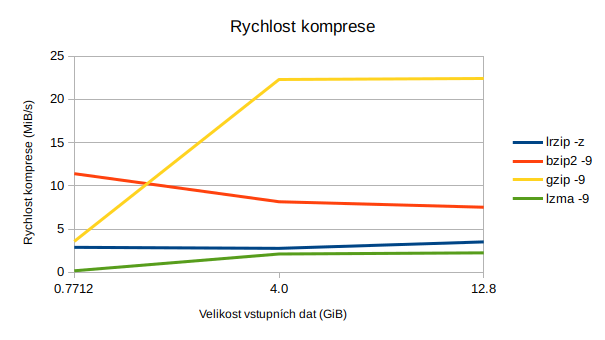
lrzip je poměrně pomalý (s parametrem -z pro kompresi ZPAQ) a vyžaduje velké množství paměti. U mě na počítači se však průměrná rychlost komprese pohybuje okolo 3 MB/s, což není zas až tak špatné, je to lepší než například lzma (0,7 až 2 MB/s).
Osobně se snažím dělat pravidelné inkrementální zálohy pomocí rsync. Tyto zálohy pak jednou za čas šifrované pomocí GPG vypaluji a kopíruji mj. na různá internetová úložiště. V tuto chvíli je pro mě velikost výsledného souboru podstatná, zatímco čas na kompresi mě v podstatě nezajímá a může trvat klidně celý den.
Všechny příklady probíhaly na stroji vybaveném Intel Core i5-4590S (3,0 GHz), 16GB RAM a SSD.
Mám adresář syncthing_delta, kam se pravidelně kopírují inkrementální zálohy. Velikost zatarovaného adresáře je 12,8 GB (12836904960 bajtů). V adresáři se nacházejí textová data, gitové repozitáře, obrázky, PDF soubory a celkově takový různý mix běžných uživatelských dat. Gzipovaných souborů je tam hodně, protože jsou interně používány rsyncem.
Tento tarovaný soubor potřebuji něčím následně zmenšit. K tomu jsem historicky využíval gzip, bzip2 a lzma. Zde je tabulka výsledných velikostí a času, který to zabralo:
| Program | Čas | Výsledná velikost (GB) | Rychlost komprese (MB/s) | Komprese o (%) | Čas dekomprese | Rychlost dekomprese (MB/s) |
|---|---|---|---|---|---|---|
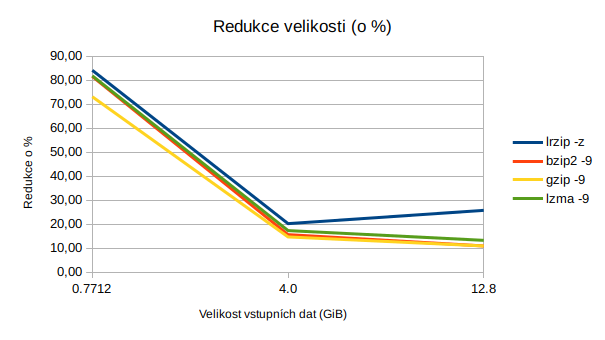
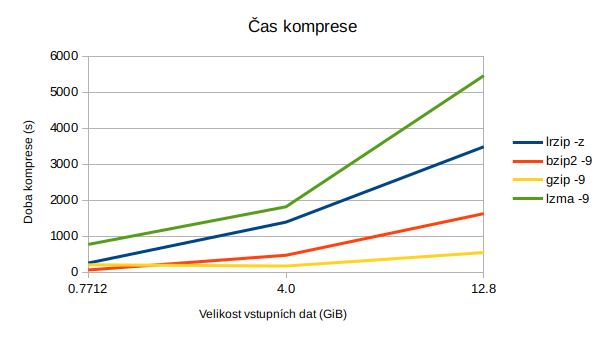
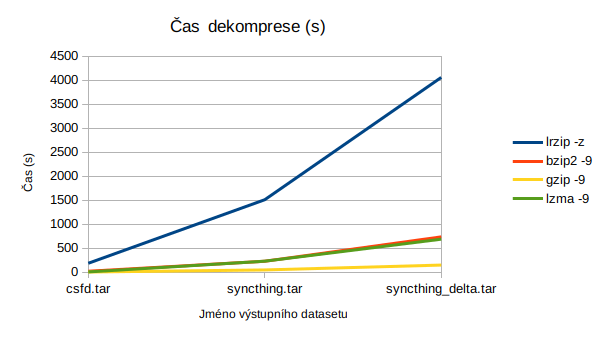
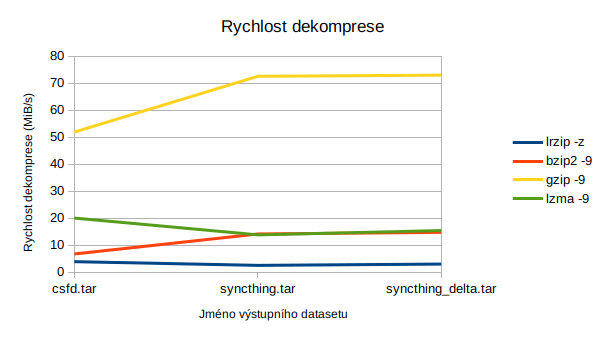
| lrzip -z | 58m 4s | 9,5 | 3,51 | 25,78 | 67m 37s | 3.01 |
| bzip2 -9 | 27m 7s | 11,4 | 7,52 | 10,93 | 12m 16s | 14,77 |
| gzip -9 | 9m 6s | 11,4 | 22,42 | 10,93 | 2m 29s | 72,97 |
| lzma -9 | 90m 58s | 11,1 | 2,24 | 13,28 | 11m 28s | 15,43 |
Předchozí příklad je lehce zkreslený, neboť komprimovaný soubor obsahuje velký počet souborů gzip, které si do ní ukládá rsync. Zde je ukázka benchmarku na zatarované složce Syncthing. Vstupní soubor tar má velikost 4,0 GB (4036546560 bajtů).
Ve složce se nachází 29 592 souborů. Četnost některých zajímavějších typů souborů je následující:
| py | 3471 |
| txt | 1315 |
| png | 1034 |
| jpg | 932 |
| pyc | 919 |
| sample | 894 |
| self | 858 |
| log | 589 |
| hh | 434 |
| cache | 385 |
| cpp | 362 |
| html | 354 |
| js | 344 |
| java | 294 |
| md | 285 |
| gif | 232 |
| json | 221 |
| css | 208 |
| rst | 190 |
| gz | 148 |
| sh | 113 |
| pyo | 103 |
| 102 | |
| zip | 94 |
| xcf | 85 |
| pym | 80 |
| yml | 70 |
| dat | 52 |
| st | 48 |
| z | 42 |
| c | 34 |
| rar | 34 |
| xml | 30 |
| doc | 27 |
| lzma | 26 |
Benchmark tentokrát vyšel takto:
| Program | Čas | Výsledná velikost (GB) | Rychlost komprese (MB/s) | Komprese o (%) | Čas dekomprese | Rychlost dekomprese (MB/s) |
|---|---|---|---|---|---|---|
| lrzip -z | 23m 12s | 3,2 | 2,76 | 20,24 | 25m 10s | 2,54 |
| bzip2 -9 | 7m 52s | 3,3 | 8,15 | 15,65 | 3m 49s | 14,17 |
| gzip -9 | 2m 52s | 3,4 | 22,3 | 14,69 | 0m 48s | 72,53 |
| lzma -9 | 30m 18s | 3,3 | 2,11 | 17,34 | 3m 50s | 13,83 |
Čas od času potřebuji provést zálohy různých databází, což jsou více či méně strukturované textové soubory. Někdy se jedná o JSON, jindy jde o SQL dumpy.
Vstupem byl soubor csfd.tar o velikosti 771,2 MB (771184640 bajtů), obsahující export z MongoDB v podobě souborů JSON.
| Program | Čas | Výsledná velikost (MB) | Rychlost komprese (MB/s) | Komprese o (%) | Čas dekomprese | Rychlost dekomprese (MB/s) |
|---|---|---|---|---|---|---|
| lrzip -z | 4m 15s | 122,6 | 2,88 | 84,10 | 3m 7s | 3,91 |
| bzip2 -9 | 1m 4s | 142,3 | 11,4 | 81,54 | 0m 21s | 6,77 |
| gzip -9 | 3m 26s | 207,6 | 3,57 | 73,08 | 0m 4s | 51,9 |
| lzma -9 | 12m 52s | 140,3 | 0,17 | 81,80 | 0m 7s | 20,04 |
Trochu nevýhodou jsou nestandardní přepínače a poněkud ukecanější výstup, než bývá běžně zvykem:
Output filename is: /home/bystrousak/Plocha/syncthing_delta.tar.lrz /home/bystrousak/Plocha/syncthing_delta.tar - Compression Ratio: 1.351. Average Compression Speed: 3.514MB/s. Total time: 00:58:04.10
Větší nevýhodou je pak nízká rychlost, a to nikoliv jen komprese, ale také dekomprese. To nebývá tak úplně zvykem. Například dekomprese pomocí gzipu je o řád rychlejší než komprese (3,57 MB/s komprese, 51,6 MB/s dekomprese).
Tohle nevadí v některých konkrétních aplikacích, kdy nepotřebujete výsledné soubory často rozbalovat a jejich použití je spíše 1:1 (jednou zabaleno, jednou rozbaleno) než 1:N (jednou zabaleno, Nkrát rozbaleno). Typicky jde například o zálohování. Naopak pro distribuci software se program moc nehodí, neboť každý uživatel by na tom spálil mnoho výkonu.
Parametr -z specifikuje algoritmus ZPAQ. Ten je poměrně zajímavý mimo jiné tím, že provádí deduplikaci dat a jejich částečnou analýzu, na základě které pak vybírá různé pod-algoritmy, které se nejlépe hodí pro kompresi konkrétní části souboru.
V hlavičkách archivu poněkud netradičně nejsou specifikované samotné algoritmy použité pro kompresi, místo toho je použit formát ZPAQL pro popis dekompresního algoritmu formou bytecode, jenž je možné za běhu přímo překládat na x86 instrukce. Díky tomu je teoreticky možné popsat výstupní data čistě algoritmicky a vygenerovat na tomto základě velké množství výstupu, podobně jako třeba prográmky demoscény generují desetiminutová videa z 64KiB binárky.
Deduplikace probíhá na základě vyhledávání již zkomprimovaných bloků dat. Tyto bloky dat přitom mají variabilní velikost a jsou děleny a identifikovány na základě svého hashe. Podle mého názoru se jedná o velmi pěkný způsob zajištění deduplikace bez ohledu na to, kde jsou data v souboru uložena a jak moc jsou v něm posunuta.
Nejlepší kompresní poměr. Komprese lepší než lzma, dekomprese pomalejší než všechno ostatní mnou testované. Dobré na zálohy, špatné na distribuci software a cokoliv, kde data plánujete často rozbalovat.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 24.4.2018 12:06
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
24.4.2018 12:06
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Osobně se snažím dělat pravidelné inkrementální zálohy pomocí rsync. … V tuto chvíli je pro mě velikost výsledného souboru podstatná, zatímco čas na kompresi mě v podstatě nezajímá a může trvat klidně celý den.Všechno je to pouze o objemu dat. Pokud ti objem komprimovaných dat naroste do takové míry, že ti přestane na kompresi 24 hodin stačit – máš problém.
 24.4.2018 11:29
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
25.4.2018 11:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
24.4.2018 11:29
Ilfirin | skóre: 32
| blog: ilfblog
| Liberec
25.4.2018 11:43
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Krom toho, ze lrzip je neudrzovan, mozna bych ti doporucil podivat se na lzma2 treba v 7zipu (u me p7zip na freebsd). Tech prepinacu, hlavne co se tyce ram a velikosti ruznych slovniku je tam x a s dostatkem ram se dostanes dal nez s lrzip. 16gb ram je pro max kompresi nedostatecnych.A umí to deduplikaci? Protože to je pro mě docela killer feature.
25.4.2018 13:06
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.4.2018 18:47
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Vedel by si povedať ako chceš programom definovať rozdiel v definícii dvoch technológií?Zajímá mě konkrétní řešení, pokud to chceš brát hypoteticko-filosoficky, tak na to nemám ani čas, ani náladu.
Pretože deduplikácia je slovníková kompresia, s pevnou dĺžkou slova a nekonečne dlhým slovníkom.Z praktického hlediska bych viděl menší zádrhel v tom nekonečném slovníku.
A ak urgentne potrebuješ funkčné riešenie, tak skús povedať cenovú hladinu. Hotových riešení pre deduplikáciu je plno. BSD s ZFS, Linux s BTRFS ...Tak jednoduché to zase není. Filesystém (např. btrfs) nebo blokové vrstva (např. vdo) s deduplikací je přece jiný use case než deduplikace při kompresi tarballu.
Ja nie, slovník sa nemusí alokovať na počiatku sveta.Pretože deduplikácia je slovníková kompresia, s pevnou dĺžkou slova a nekonečne dlhým slovníkom.Z praktického hlediska bych viděl menší zádrhel v tom nekonečném slovníku.
Áno. Pri deduplikácii na úrovni FS nepotrebuješ používať TAR.A ak urgentne potrebuješ funkčné riešenie, tak skús povedať cenovú hladinu. Hotových riešení pre deduplikáciu je plno. BSD s ZFS, Linux s BTRFS ...Tak jednoduché to zase není. Filesystém (např. btrfs) nebo blokové vrstva (např. vdo) s deduplikací je přece jiný use case než deduplikace při kompresi tarballu.
 .
.
 . Jinak kdybych měl úkol zazálohovat profesionální data, tak bych stejně použil bzip2 a to kvůli dlouhému času dekomprese lrzip (ztráta zisku při delším downtime).
25.4.2018 11:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
. Jinak kdybych měl úkol zazálohovat profesionální data, tak bych stejně použil bzip2 a to kvůli dlouhému času dekomprese lrzip (ztráta zisku při delším downtime).
25.4.2018 11:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
To jsem nepochopil. Rzip má jen o 0.1GB menší soubor, ale dekomprese trvá skoro o řád déle než u bzipu2 ?Záleží. Například u toho syncthing_delta.tar je to menší o 1.6GB než LZMA, což není zanedbatelné. Konkrétně to pálím na 25GB bluray, kde se každý volný gigabajt hodí.
26.4.2018 12:34
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A jak to vyjde s cenou elektřiny? Tedy jestli to znamená plný výkon 100W procesoru (plus běžící zbytek kompu a disky) po 1 hodinu na to abych ušetřil 1,5GB tak je to cca 0,5 Kč za elktřinu proti cca 1,2 Kč za cenu media (na rotačním disku). Před časem jsem kompresoval nějaké filmy do x265, ale postupně to oželím, protože i když film stisknu na cca 30'% původní velikosti, tak rychlost je někde kolem uspory 0,8 GB za hodinu výpočtu a to mi připadá málo efektivní.Elektřinu zanedbávám. Stojí tak málo, že se mi to v podstatě nevyplatí řešit. Počítač by stejně běžel tak jako tak, teď jen běží CPU na plný výkon. Šlo mi o to, že jinak bych musel pálit další bluray, trvalo by to další hodinu a byl by to další opruz, to dávat do vypalovačky, katalogizovat, nadepisovat a pak skladovat. Takhle se mi tam vešlo co jsem potřeboval. Na zálohování mám napsaný script, co všechno zkomprimuje, zašifruje, vytvoří md5sum a tak podobně, takže tam prostě přepíšu lrzip místo gzipu a tím to pro mě hasne.
25.4.2018 13:07
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
25.4.2018 13:31
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
27.4.2018 19:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
29.4.2018 11:44
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
#! /usr/bin/env bash
#
export ADDRESS="bystrousak@kitakitsune.org"
export GPG_PARAMS="--recipient $ADDRESS --compress-level 0 -e --yes --output"
function md5it {
pv "$1" | md5sum - > "$1.md5sum";
}
function pack_to_gpg {
echo "Packing $2 .. "
# tar -czO "$1" 2>/dev/null | gpg $GPG_PARAMS "$2";
tar -cO "$1" 2>/dev/null | pv -s $(du -sb "$1" | awk '{print $1}') | pbzip2 -5 -p3 -c | gpg $GPG_PARAMS "$2";
md5it $2;
echo "done"
}
if [ -d bluray ]; then
rm -fr bluray;
fi
mkdir bluray
cd bluray
pack_to_gpg /media/bystrousak/Internal/Backup/delta/xlit_delta xlit_delta.tar.bz2.gpg
pack_to_gpg /media/bystrousak/Internal/Backup/delta/syncthing_delta syncthing_delta.tar.bz2.gpg
pack_to_gpg /media/bystrousak/Internal/Backup/delta/dropbox_delta dropbox_delta.tar.bz2.gpg
pack_to_gpg /media/bystrousak/Internal/Backup/delta/pocketbook_delta pocketbook_delta.tar.bz2.gpg
cp /home/bystrousak/Plocha/scanny .
md5it scanny
10.5.2018 15:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
tady ale ztratite optimalizaci dle obsahu jednotlivych souboruJe to jen pocit, nebo to tak fakt je? Já myslel, že by na tom nemělo záležet, ale netestoval jsem to.
10.5.2018 17:15
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
protoze problem je takovy sorted tar vyrobitČistě jen pro inspiraci: python má tarfile. Tím si to můžeš namixovat.
Jeste jsem se koukal na zpaq ktery by mel byt konkurenci lrzipu, zkusim prohnat testovaci data jeste nim v max nastaveni a dam vedet.Počkat, já psal ten článek právě o lrzipu s
-z, což zapíná zpaq. Pokud myslíš zpaq jako program, tak to bude imho jen jiný frontend. Nebo ne?
12.5.2018 10:06
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 24.4.2018 12:21
24.4.2018 12:21