Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
LDAP (Lightweight Directory Access Protocol) je protokol pro přístup k údajům v adresáři – jak pro čtení a vyhledávání, tak pro přidávání, modifikaci a mazání. Protokol vznikl ze složitějšího protokolu DAP (X.511), který je součástí množiny X.500 vytvořené ITU-T a je pro běžné použití příliš složitý. Veškerá data jsou uložena ve stromové struktuře. Celý systém funguje na bázi klient-server, čili někde běží jeden nebo více serverů, k nimž se připojují klientské programy.
Strom LDAP je složen z objektů, každý objekt má své atributy. Například objekt třídy inetOrgPerson má atributy uid, cn, sn, gn, mail, userPassword (reprezentují identifikátor uživatele, jeho celé jméno, příjmení, křestní jméno, e-mailovou adresu a heslo) a mnohé další. Objekt je v rámci stromu jednoznačně identifikován pomocí rozlišovacího jména (Distinguished Name, DN), které vlastně popisuje cestu k objektu. Na každé úrovni se používá ještě relativní rozlišovací jméno (RDN), které zajišťuje unikátnost každého objektu. K rozlišování se používá vhodný atribut v rámci daného objektu (např. u uživatelů jejich přihlašovací jméno).
V rámci DN se používá tzv. sufix, což je část DN, která se při běžném používání adresáře nemění. Může se použít například doménový název (pokud je neměnný), případně nějaký jiný rozlišovač. Cílem je zajistit celosvětovou unikátnost každého rozlišovacího jména.
Pro přístup k záznamům lze nastavovat přístupová oprávnění. Typicky administrátor může měnit uložené údaje, všichni mají právo číst určité informace, někteří uživatelé mohou číst i další údaje apod.
O tom, jak budou třídy objektů vypadat, jaké atributy budou obsahovat, jakou budou mít kardinalitu atd., rozhoduje schéma. Typická instalace LDAP serveru obsahuje základní schémata definovaná v dokumentech RFC (například RFC 2256 definuje, jak vypadá schéma pro objekty uživatelů), může obsahovat i nějaká specifická. Pokud to jde, je dobré se držet základních schémat, usnadňuje to pozdější manipulaci, přechod na jiný software apod. – nevýhodou je, že to často znamená použití atributů k jiným účelům, než pro které vznikly, byť se tak třeba nepoužívají.
Informace z LDAP lze využít k řadě účelů. Asi nejjednodušší je obyčejné vyhledávání informací (například z poštovního klienta při hledání e-mailové adresy nějaké osoby). Dále lze podle LDAP autentizovat uživatele (záznamy mohou obsahovat hesla, certifikáty a další údaje), zjišťovat jejich parametry (např. domovský adresář, shell, periodu pro změnu hesla) a třeba také doručovat poštu. To bude také jedním ze dvou účelů využití technologie LDAP na poštovním serveru (tím druhým bude samozřejmě autentizace uživatelů). V adresáři LDAP může být i mnoho dat nesouvisejících s uživateli, třeba počítače, různé skupiny všeho možného, geografické informace, konfigurace programů apod.
Implementací LDAP serverů existuje celá řada. Ve světě GNU/Linuxu je asi nejznámější OpenLDAP, často se používá Microsoft Active Directory, dále tu máme například Apache Directory Server, OpenDS, Novell eDirectory, tinyldap, Mandriva Directory Server a mnoho dalších. Liší se především ve způsobu uložení dat, v konfiguraci, v použitých technologiích apod. K využití služeb LDAP není až tak důležité, o který konkrétní server se jedná, záleží hlavně na tom, jak je nastaven a s jakou strukturou dat pracuje. Struktura může být dána řadou požadavků, které je potřeba skloubit.
Poštovní server obvykle využívá LDAP v režimu čtení (dotazování), neprovádí žádné změny v datech, byť to obecně není úplně vyloučeno. Při doručování pošty je třeba ověřit, zda cílová adresa existuje a kam se má pošta doručovat. Při přístupu k poště (protokoly POP3 a IMAP) je důležité opět samozřejmě úložiště, ale také ověřování uživatelů. Uživatele je případně třeba ověřovat i při odesílání pošty.
Dotazování LDAP se principiálně neliší od dotazování jiných datových zdrojů, například databáze MySQL. Rozdíl je jen v drobnostech, které se ale samozřejmě mohou poměrně zásadně promítnout do konfigurace poštovního softwaru. Přestože má LDAP pověst mlhou zahalené a těžko zkrotitelné technologie, při dobrém pochopení základních principů není složité nastavit programy Postfix a Dovecot tak, aby správně komunikovaly se LDAP serverem.
Záleží samozřejmě na tom, zda se využívá již existující strom s informacemi, do kterého se případně jen doplní další potřebné údaje, anebo se začíná „na zelené louce“ a struktura LDAP informací bude přizpůsobena potřebám poštovního serveru.
Pokud se bude LDAP používat pro účely lokálních (systémových) uživatelů, je situace o něco jednodušší, protože lze celou problematiku vytěsnit z konfigurace poštovního serveru a ponechat ji jen v konfiguraci systému jako celku. Pak se pro ověřování uživatelů a zjišťování dalších údajů o nich (jak pro poštovní účely, tak i pro všechny ostatní) využije NSS a PAM (konkrétně v GNU/Linuxu knihovny libnss_ldap a pam_ldap). Proto se poštovní serverové programy nastaví stejně, jako kdyby se jednalo o obyčejnou uživatelskou databázi v souborech passwd, shadow atd. Jediné, co by se mohlo řešit přímo na úrovni poštovního serveru, by byly aliasy.
Jiná situace bude v případě uživatelů virtuálních, kde protokolem LDAP komunikují přímo Postfix a Dovecot. Oba programy pak musí být náležitě nastaveny, aby se správně připojovaly na LDAP server (případně více serverů; LDAP server bývá pro svou důležitost často přítomen v síti vícekrát, jeden jako hlavní, ostatní jako podřízené servery) a generovaly správné dotazy na potřebné údaje.
Jednoduchým případem je situace, kdy poštovní server obsluhuje pouze jedinou doménu. Znamená to, že se na domény vůbec není třeba dotazovat (ta jediná se uvede v konfiguraci) a struktura stromu LDAP by v podstatě vůbec nemusela informaci o doméně nést. Představme si například takovouto podobu adresáře LDAP:
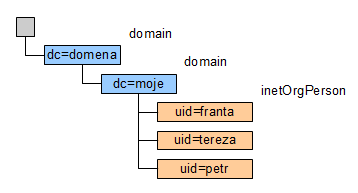
Znamená to, že například uživatel s přihlašovacím jménem (a též názvem e-mailové schránky) franta bude mít DN v podobě uid=franta,dc=moje,dc=domena. Sufix bude v tomto případě dc=moje,dc=domena, protože to je část, která zůstane vždy stejná. Nyní jde o to, jak rozlišit, co je skutečný uživatel, co alias a jak rozlišit uživatele, kteří nemají e-mailovou schránku. Protože ale objekt inetOrgPerson, který je vhodné použít pro uložení dat o uživateli, obsahuje mnoho atributů, z nichž řada zůstává nevyužita, lze některý z těchto atributů použít pro uložení dalších údajů.
Vhodným kandidátem může být například preferredDeliveryMethod, což je původně atribut určující, jak přednostně doručovat uživateli informace. Protože tento atribut často zůstává nevyužitý, lze například určit, že jeho hodnota physical bude odpovídat e-mailové schránce, zatímco mhs bude alias. Ostatní hodnoty nebudou mít pro e-mailový server význam. Takto se při dotazech vyfiltrují relevantní hodnoty.
Protože u aliasu je potřeba ještě definovat cílovou adresu, bude nutné zvolit ještě další vhodný atribut (atribut mail není vhodný; pokud se totiž adresář LDAP používá i pro vyhledávání příjemce pošty v poštovních klientech, měl by obsahovat vždy adresu příslušející k objektu, ne cílové adresy použité k přesměrování). Volný bývá například atribut physicalDeliveryOfficeName, který je původně určen pro název kanceláře pro fyzické doručování (a tedy dost pravděpodobně není využit).
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 11.12.2009 07:00
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
11.12.2009 07:00
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Jen bych se chtel zeptat, zdali bude take uvedena konfigurace dovecotu jako LDA ( treba se Sieve ci procmail pro presun SPAMU do adresare ci automaticke promazavani SPAM adresar)?Samozřejmě bude.
Pak taky, zda-li byste mohl dokoncit tu vsuvku o podadresarich kvuli pluginum. Co vsechno se zmeni (user_attrs?).Teď jen ve stručnosti. Jde o to, že pokud se například využívá Sieve a nad domovským adresářem pracuje ManageSieve (ať už jako součást Dovecotu nebo jako samostatný program, např. PySieved), budou se v klientovi zobrazovat i soubory, které nemají. A obráceně, Dovecot bude adresář vytvořený pro účely Sieve (kam se budou ukládat Sieve skripty) považovat za poštovní složku (pokud bude název začínat tečkou, jak je obvyklé), čili ji bude klientům nabízet společně s jinými složkami. To není stav, o který by člověk zrovna stál. Ale znovu říkám, ve všech příkladech dosud používaných v seriálu využití "domovského adresáře virtuálního uživatele" nijak nevadilo, proto jsem také nevytvářel další adresářovou úroveň. Při použití se samozřejmě user_attrs nezmění, protože tam je právě domovský adresář, který zůstane stejný. Změní se naopak mail_location (například na maildir:/var/mail/virtual/%d/%n/Maildir, pokud bude pošta v adresáři Maildir pod domovským adresářem). U Postfixu by se změnil result_format (v tomto případě na %d/%u/Maildir/).
12.12.2009 15:15
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
 12.12.2009 15:43
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
12.12.2009 15:43
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 ), umím z něj číst, ale vůbec nechápu princip jeho činnosti (nenašel jsem ani návod pro blbé, takže soudím, že to bude triviální a někdy prostě nastane ahááááá efekt) ani jej neumím nainstalovat. Přesto jsem mnoho let spokojeným adminem.
12.12.2009 16:25
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
), umím z něj číst, ale vůbec nechápu princip jeho činnosti (nenašel jsem ani návod pro blbé, takže soudím, že to bude triviální a někdy prostě nastane ahááááá efekt) ani jej neumím nainstalovat. Přesto jsem mnoho let spokojeným adminem.
12.12.2009 16:25
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
vůbec nechápu princip jeho činnostiCo na tom nechápeš? Základní princip je naprosto triviální. Je to prostě strom objektů a každý objekt může mít atributy (jaké přesně a které jsou povinné atd., to záleží na schématu). Ten strom může vycházet třeba z hierarchie DNS nebo být úplně jiný, podle potřeby. Představ si to třeba jako XML strom nebo něco takového (třeba registry ve Windows
 ), je to jedno. Jak si to server vnitřně reprezentuje (třeba klidně jako nějaký XML soubor, databázi nebo jako objekty v C++, které se pak binárně zapisují na disk), to už je čistě implementační záležitost.
K jednotlivým objektům a atributům lze pak nastavovat práva.
), je to jedno. Jak si to server vnitřně reprezentuje (třeba klidně jako nějaký XML soubor, databázi nebo jako objekty v C++, které se pak binárně zapisují na disk), to už je čistě implementační záležitost.
K jednotlivým objektům a atributům lze pak nastavovat práva.
ani jej neumím nainstalovatInstalace je taktéž triviální. Netriviální může být u některých implementací počáteční konfigurace (např. u OpenLDAP). Ale jsou implementace, kde je to také jednoduché (třeba Apache Directory Server; pro něj existuje také klikátko Apache Directory Studio, kterým lze jak pracovat se stromem, tak i konfigurovat server).
12.12.2009 18:37
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
, resp. napadají mě technologie, které zvládnou totéž co si myslím, že má být LDAP (nasazení LDAPu tak jak jej máme u nás by šlo snadno přepsat do SQL).
ad 2) Zde to bude zřejmě tím OpenLDAPem.
Není to technologie, kterou bych musel znát (nemám to kde využít), takže to nechám v klidu jiným. Pokud o tom někdo napíše srozumitelný článek včetně příkladů nasazení (od nejjednodušších, řekněme pro ověřování uživatelů na jedné mašině (místo /etc/passwd)), rád si jej přečtu. A jistě nebudu sám.
12.12.2009 22:04
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Pokud je to ovšem celé, tak pak nechápu smysl samotného LDAPu , resp. napadají mě technologie, které zvládnou totéž co si myslím, že má být LDAP (nasazení LDAPu tak jak jej máme u nás by šlo snadno přepsat do SQL).LDAP je především komunikační protokol. O to jde v první řadě. A protože tento protokol má poměrně širokou podporu, lze ho využívat v mnoha programech. Lze měnit klientský i serverový software podle potřeby, aniž by se musel měnit zbytek celku.
 13.12.2009 21:52
otula | skóre: 45
| blog: otakar
| Adamov
13.12.2009 21:52
otula | skóre: 45
| blog: otakar
| Adamov
Pokud o tom někdo napíše srozumitelný článek včetně příkladů nasazení (od nejjednodušších, řekněme pro ověřování uživatelů na jedné mašině (místo /etc/passwd)), rád si jej přečtu. A jistě nebudu sám.Jo, k tomu článku pro blbé se také přidávám
S (open)LDAP jsem se dostal do fáze, kdy běží (jakože se jen samoúčelně spustí bez použitelných dat), ale nejsem tam schopen nic rozumného nasáčkovat tak, abych to mohl jakkoliv použít. Většina návodů se spoléhá na nějaké skripty, které udělají většinu práce (ale tyto skripty v Archu nejsou). Chtěl jsem začít zdrojem adres pro mailové klienty, ale nějak jsem se neprokousal k výsledku.
Pro Lukáše: kdyby se ti chtělo napsat knihu o LDAP, určitě bys měl jistého minimálně jednoho kupce
Pro Luka - pokud budeš psát knihu, dobře si to rozmysli, moc čtenářů mít nebude. LDAP je hodně komplexní a vyžaduje dost znalostí souvisejících věcí. O Tebe starost nemám, evidentně o tom hodně víš. Problém je se čtenáři, protože je to může odradit. Příklady použití jsou docela komplexní, leckdy zasahují spíš do podnikové sféry a vyžadují dost času a experimentů.
14.12.2009 00:40
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Pro Luka - pokud budeš psát knihu, dobře si to rozmysli, moc čtenářů mít nebude.Knihu psát nebudu - viz níže
14.12.2009 11:43
otula | skóre: 45
| blog: otakar
| Adamov
14.12.2009 00:40
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Pro Lukáše: kdyby se ti chtělo napsat knihu o LDAP, určitě bys měl jistého minimálně jednoho kupceZaprvé nejsem odborník na LDAP (proto píšu v článku, že "lépe se vyjádří znalec LDAP" - a to já bohužel nejsem), zadruhé teď dokončuji zapracování odborné korektury do knihy na úplně jiné téma, takže o psaní knih zase nějakou dobu nebudu chtít ani slyšet
14.12.2009 11:47
otula | skóre: 45
| blog: otakar
| Adamov
Zaprvé nejsem odborník na LDAP (proto píšu v článku, že "lépe se vyjádří znalec LDAP" - a to já bohužel nejsem), zadruhé teď dokončuji zapracování odborné korektury do knihy na úplně jiné téma, takže o psaní knih zase nějakou dobu nebudu chtít ani slyšetTo je škoda. Píšeš pěkně "čitelně" :)
13.12.2009 00:55
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Čemu by tak hrozně vadilo to, kdybychom si vytvořili vlastní schema ?Nevadilo by. Tedy aspoň v tomto případě (u některých programů by vadilo, protože ty napevno počítají s objekty určitých tříd). Akorát že by se muselo vymýšlet a muselo by se nainstalovat. Pokud se použije hotové schéma, toto celé odpadá.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz