FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
Insula Faktury je open source generátor faktur, který běží přímo ve webovém prohlížeči. Žádná registrace, žádné sledování, žádné omezení. Zdrojové kódy jsou k dispozici na Codebergu.
První Mobile Linux Hackday v Plzni, tj. komunitní setkání věnované Linuxu na mobilních zařízeních, proběhne 24. července od 10:00. Akce je otevřená všem zájemcům – od zvědavců po zkušené vývojáře. Dopoledne proběhnou přednášky Davida Heidelberga a Petra Hodiny o aktuálním stavu mobilního Linuxu: proč vůbec chtít tučňáka v kapse, jaké telefony jsou dnes dobře podporované a co taková podpora obnáší. Po obědě se zaměříme na konkrétní
… více »3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
FreeCAD (Wikipedie), tj. svobodný multiplatformní parametrický 3D CAD, má nový vtipný a současně užitečný doplněk Banana For Scale (GitHub). Aktuálně umožňuje do výkresu vložit banán nebo plechovku pro porovnání a určení měřítka.
9.6.2010 17:27
| Přečteno: 5719×
| Za vším hledej Linux
| 
Taky vás tak prudí, kolik místa zabírají DVD s filmy stažená na disk? Mě děsně. Protože však nemám dost času ani na to abych je vůbec stíhal zkouknout, natož zkonvertovat do únosnějšího objemu, píšu si na to skriptík, se kterým by šlo pracovat dávkově.
Na rozdíl od mých poloslepých žen preferuji u filmu originální znění s titulky, proto by měl skript produkovat dual avi + soubor s titulky a fungovat po spuštění pokud možno bez nějaké další asistence. Proto jsem potřeboval nějakou OCR utilitu, co by produkovala alespoň částečně použitelný výsledek.
Před nějakým časem jsem zkoušel extrahovat titulky pomocí dvdsub i pgm2srt, ale s výsledkem jsem moc spokojen nebyl. Druhý zmíněný na tom byl sice přeci jen o něco lépe než ten první, co používá jako backend gocr ale pořád nic moc. Proto jsem se kouknul v Synapticu co v oblasti OCR Debian aktuálně nabízí.
Název aplikace cuneiform mi nic moc neříkal, tak jsem ji vyzkoušel jako první. Předhodil jsem jí jeden starý sken stránky ze samizdatového časopisu, co se mi zrovna válel v domovském adresáři a nestačil se divit. Ve výsledném textu byly pouze dvě problémové věci. Nejčastější chybou byla záměna "í" (většinou za písmeno "f") a špatně byly rozpoznané pouze dvě slova, které byly v kurzívě. Podotýkám předem, že kvalita skenu byla spíš lepší než horší, ale na rozdíl od ostatních cuneiform nezmátla grafika na stránce.
Tesseract jsem zkoušel již dřív, a jelikož nemá podporu pro češtinu, tak jsem jej vynechal rovnou. Výsledek který vyprodukoval gocr a ocrad - škoda slov. Takže jednoznačným favoritem pro můj skript se stal cuneiform. O této aplikaci zde zatím jak se zdá zmínka nepadla, tak proto tento zápis.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 9.6.2010 17:35
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
9.6.2010 17:35
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň

a zrovna sem se ho chystal dneska vyzkouset, zeby nahoda? 
9.6.2010 17:40
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
nevim jestli je to koser, linkovat ke konkurenciNení! Smrt Rootu!
 -- Ne, co se dá dělat, když to nevyšlo u nás? Od toho existuje HTML, že jo... Ale ty linky pro příště prosím pojmenuj jinak než "tady" - z toho nejde (bez bližšího zkoumání) poznat, kam to vede.
9.6.2010 17:53
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
9.6.2010 20:26
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
-- Ne, co se dá dělat, když to nevyšlo u nás? Od toho existuje HTML, že jo... Ale ty linky pro příště prosím pojmenuj jinak než "tady" - z toho nejde (bez bližšího zkoumání) poznat, kam to vede.
9.6.2010 17:53
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
9.6.2010 20:26
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
 9.6.2010 18:36
Amarok | skóre: 33
| blog: blogoblog
9.6.2010 18:46
Amarok | skóre: 33
| blog: blogoblog
9.6.2010 20:26
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
tam taky bez znalosti azbuky clovek z tech for nic nevycte.
9.6.2010 22:23
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
9.6.2010 18:36
Amarok | skóre: 33
| blog: blogoblog
9.6.2010 18:46
Amarok | skóre: 33
| blog: blogoblog
9.6.2010 20:26
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
tam taky bez znalosti azbuky clovek z tech for nic nevycte.
9.6.2010 22:23
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
Program super, ale nejak nechapu, co ma spolecneho OCR s tim, ze pri grabovani DVD se ma ulozit
soubor s titulky?
a to to jako skenujes z ceho ty titulky? je mas nekde vytisteny na papire?
 9.6.2010 19:14
Limoto | skóre: 32
| blog: Limotův blog
9.6.2010 19:14
Limoto | skóre: 32
| blog: Limotův blog
 9.6.2010 19:09
stativ | skóre: 54
| blog: SlaNé roury
Avidemux má cli rozhranie, ale neviem ako je použiteľné a pri OCR ako som písal je potrebná interakcia.
9.6.2010 19:09
stativ | skóre: 54
| blog: SlaNé roury
Avidemux má cli rozhranie, ale neviem ako je použiteľné a pri OCR ako som písal je potrebná interakcia.
Avidemux má cli rozhranie, ale neviem ako je použiteľné a pri OCR ako som písal je potrebná interakcia.Také používám avidemux, ale už jen na úpravu hotového videa. Pokud jde o to OCR - to je právě výhoda cuneiform - není nutná interakce a výsledek je natolik kvalitní, že stačí zkontrolovat výsledek přes aspell (opět na konzoli). Avidemux pro OCR nejspíš využívá (podobně jako to dělal
pgm2srt) toho že se u titulků zase tak moc šumu neobjevuje, takže lze vzorky porovnávat poměrně jednoduše. Kdežto OCR engine který používá cuneiform má (pravděpodobně) zabudovanou i nějakou další logiku. Proto je výsledek dobrý i bez interakce.
tj. najde shluk pixelů (ideálně je to 1 znak) a zeptá se uživatele, co to je a příště (v rámci jednoho spuštění) už přiřadí znak automaticky. Naprogramoval jsem to speciálně pro převod DVD titulků do TXT, rozhodně je to na nic pokud jde o skenovaný text. GUI má pak i funkce pro úpravu časování titulků, pročištění a převod mezi SUB a SRT.
.
10.6.2010 13:18
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
takze byste o tom meli minimalne uvazovat
10.6.2010 13:25
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
11.6.2010 10:45
Amarok | skóre: 33
| blog: blogoblog
11.6.2010 13:30
kotyz | skóre: 25
| blog: kotyzblog
| Plzeň
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz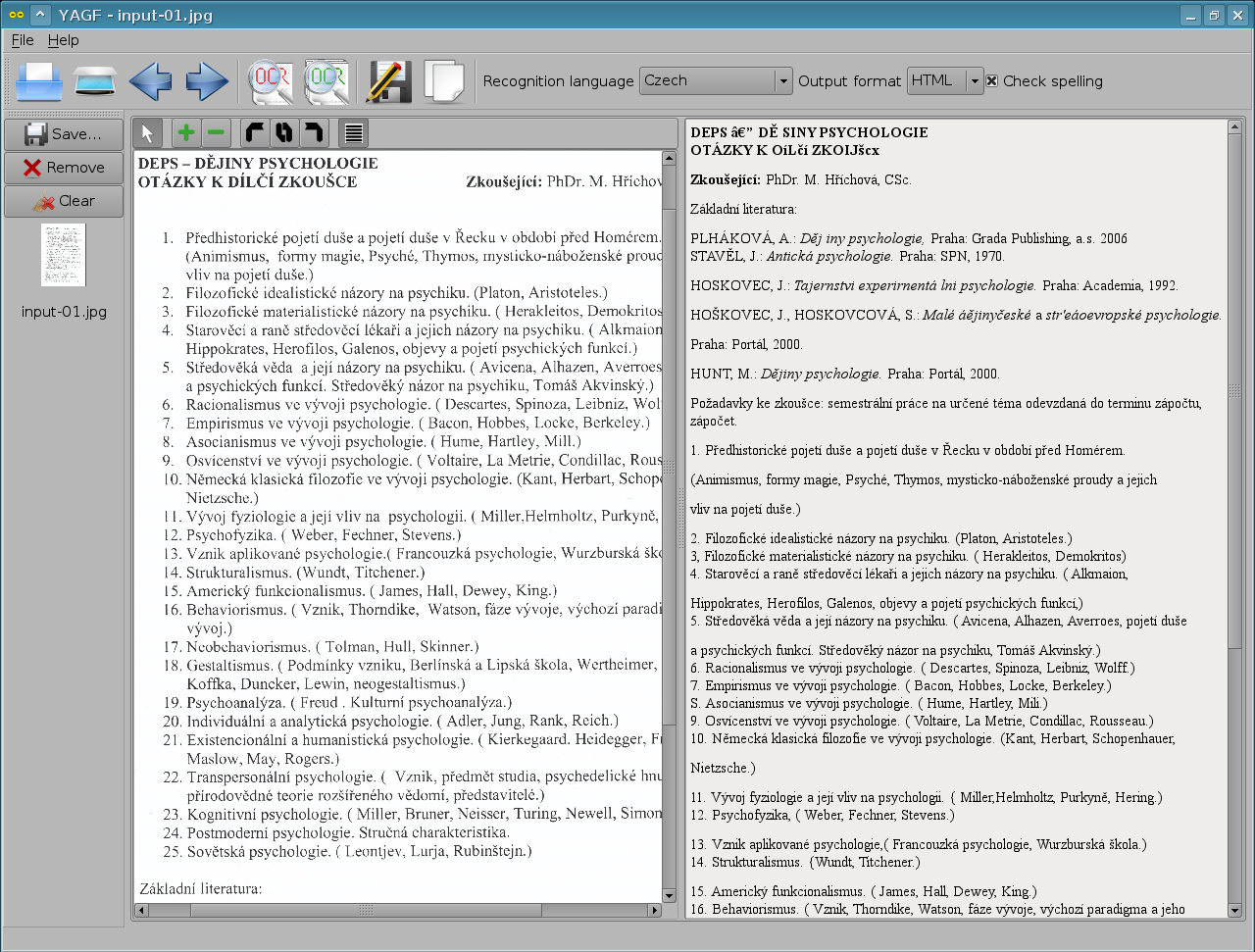{kind=link}
{kind=link}