Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
Samba, svobodná implementace síťového protokolu SMB/CIFS, byla vydána ve verzích 4.24.5, 4.23.10 a 4.22.11. Řešeno je 6 zranitelností.
Přední technologické společnosti (Adobe, Cadence, Capital One, Cisco, Cloudera, Cloudflare, Cognition, CrowdStrike, Databricks, Dell Technologies, DoorDash, Elastic, HPE, Hugging Face, IBM, LangChain, Linux Foundation, Microsoft, NAVER, NetApp, Nous Research, NVIDIA, OpenClaw, Palantir, Palo Alto Networks, Red Hat, Reflection AI, Salesforce, SAP, ServiceNow, Siemens, SK Telecom, Snowflake, SpacexAI, Synopsys, Thinking
… více »Krabix.cz je online 3D konfigurátor krabiček pro 3D tisk s exportem do STL. Běží přímo v prohlížeči. Nic se neposílá na server.
Nadace Open Home Foundation spustila veřejnou preview verzi komunitní databáze zařízení pro Home Assistant. Má fungovat jako „Wikipedie pro chytrá zařízení".
Na stránce nového panelu Firefoxu přibudou nové widgety. Například denně aktualizována interaktivní křížovka.
Překladač je program, který (velice zjednodušeně řečeno) postupně prochází kód napsaný v nějakém programovacím jazyce a z něj generuje spustitelný soubor. Samotný překlad se sestává z několika fází, z nichž druhá se nazývá:
/* program v C */
int n = 10;
char* s = "Hello, world!";
if (n == 10) {
printf("%s\n", s);
}
" program ve Smalltalku "
n := 10.
s := 'Hello, world!'.
[n = 10] if:
[ Transcript show: n, s; cr. ]
Nahoře jsou ukázky zdrojového kódu napsaného ve dvou různých programovacích jazycích — C a Smalltalk (Squeak). Jsou to přesně ty samé, které byly uvedeny v minulém díle. Pokud máte zkušenosti s programováním, tak víte, že jazyky očekávají lexémy na přesně definovaných místech (snad s výjimkou jazyka Perl, který má nejvolnější pravidla, co znám :-)). Což je úkol, na který už lexikální analyzátory nestačí, protože ty na zápise
printf("%s\n", s) if (n == 10);
neuvidí nic zvláštního. Přesto, jak už určitě tušíte, překladač jazyka C s tím souhlasit nebude a bude si stěžovat:
perl.c:7: error: syntax error before ?}? token
To znamená, že syntaxe je nejen množina lexémů jazyka, jak víme z minulého dílu, ale něco víc.
Než se zaměříme na naši obvyklou implementační otázku, bude nutné opět udělat menší výlet do oblasti teorie. Pokud si pamatujete z prvního dílu, tak formální jazyky bývají generovány gramatikami. Programovací jazyky jsou zcela jistě jazyky formálními, to znamená, že mají svoje gramatiky. A právě ony zabezpečují část toho, co nazýváme slovem syntaxe. Například gramatika jazyka C přikazuje, že po klíčovém slovu if následuje výraz v závorkách následovaný buďto příkazem anebo skupinou příkazů (ohraničenou znaky {}). Zatímco gramatika jazyka Perl dovoluje, aby byla podmínka i za výrazem, gramatika jazyka C nikoliv. A protože se jí řídí jak programátor (většinou), tak i překladač (vždy, pokud nemá chybu), je možné, aby překladač dokázal zpracovat kód napsaný člověkem.
Gramatiky programovacích jazyků patří do třídy bezkontextových jazyků podle Chomského hierarchie. V této oblasti počítačoví vědci definovali několik podtříd, ke kterým patří jisté parsovací algoritmy. Pohled do příslušné kategorie na wikipedii (Category:Parsing algorithms) nám dává představu o jejich počtu. Samotný proces, který nazýváme parsování (nebo syntaktická analýza), jsou postupné derivace řídící gramatiky (respektive tvorba derivačního stromu — parsing tree) a ověřování, zda jí lexémy odpovídají. Většina parserů potom používá jednu ze dvou strategií.
První z nich je top-down parsing (shora dolů). Tento parser pracuje tak, že vychází ze startovacího symbolu gramatiky a postupně hledá derivace. Ten se také často implementuje rekurzivním sestupem, kdy se pro každý (non)terminální symbol napíše obslužná funkce, které se při parsování postupně volají.
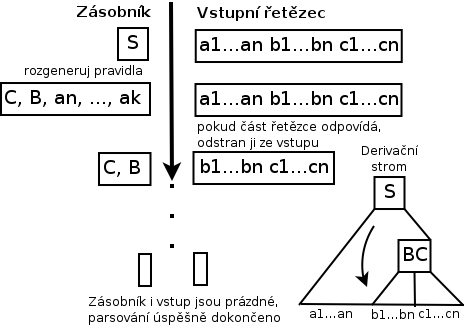
Druhá je bottom-up parsing (zdola nahoru). Ten naopak dělá postupně operace shift-reduce a pracuje od nejnižších symbolů gramatiky nahoru ke startovacímu.
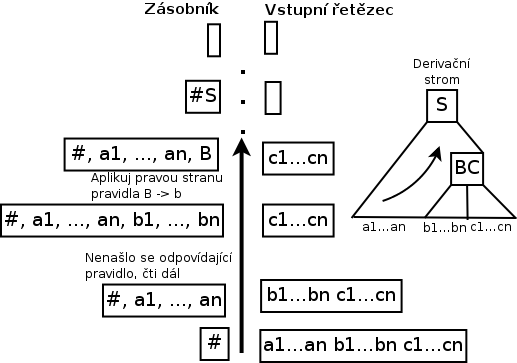
Obecně můžeme říct, že je gramatika určitého typu, pokud k ní můžeme sestrojit parser stejného typu.
LL parsery používají parsing shora dolů, zpracovávají vstup zleva doprava a konstruují nejlevější derivaci. Proto se také nazývá L (left-to-right) L(leftmost derivation). Občas se setkáváme s označením LL(k), kde k značí počet tokenů, které potřebujeme znát při rozhodování o průběhu další analýzy bez toho, aby bylo třeba používat backtracking. Také se v této souvislosti používá pojem look-ahead. Těmto parserům se říká evropské, mimo jiné i proto, že se jim věnoval Niclaus Wirth, který publikoval množství prací o optimalizaci LL(1) parserů. Wirthovo zaměření na rychlost překladu je jeden z důvodů, proč je překlad Pascalu obecně rychlejší, než překlad podobných jazyků. Rozhodně to platilo na 486 a překladačích společnosti Borland. Pascal se překládal bleskově, C už pomaleji (o C++ ani nemluvě). Prakticky do nedávné doby se tyto gramatiky příliš nepoužívaly, ovšem na počátku 90. let minulého století došlo ke změně přístupu.
Vezměme jednoduchoučkou gramatiku s pravidly (pravidlo 3 není formálně správně zapsané, ale doufám, že mi bude odpuštěno, \d značí libovolné číslo).
Vidíme, že gramatika obsahuje terminální symboly (, ), \d, + a navíc si doplníme symbol pro konec vstupu $. Potom bude parsovací tabulka (pravidla pro konstrukci přeskočím) vypadat
( |
) |
\d |
+ |
$ |
|
| S | 2 | -- | 1 | -- | -- |
| N | -- | -- | 3 | -- | -- |
Top-down parsing začíná ze startovacího symbolu, takže na počátku je v zásobníku
[ S, $ ]
Projdeme si výraz (1 + 2)$. Když parser požádá lexikální analyzátor o další token, získá znak (. V parsovací tabulce je pro symbol na vrcholu S a vstup ( příkaz, použij pravidlo #2 (přičemž se v dalším kroku znak ( ze zásobníku zahodí). Tím dostaneme
[ S, +, N, ), $ ]
V dalším kroku lexikální analyzátor vrátí 1, to znamená, že pro dvojici [S, 1] použijeme pravidlo #1 (nahrazení znaku S za N). Abychom si to zkrátili, rovnou i pravidlo #3 (nahrazení N za \d).
[ \d, +, N, ), $ ]
Načtený symbol 1 odpovídá \d, takže jej můžeme ze zásobníku odstranit. Další kroky jsou již analogické:
[ +, N, ), $ ] // nacteno +, muzeme odstranit [ N, ), $ ] // nacteno 1, aplikujeme #3 [ \d, ), $ ] // nacteno 1, muzeme odstranit [ ), $ ] // nacteno ), muzeme odstranit [ $ ] // nacteno $, muzeme odstranit [ ] // parsovani uspesne dokonceno
Tímto postupem jsme získali nejlevější derivaci — S → (S + N) → (N + N) → (\d + N) → (\d + \d)
LR parsery potom logicky konstruují nejpravější derivaci, ale vstup zpracovávají zleva doprava. Používají parsing zespoda nahoru. Jejich výhodou je fakt, že je možné jejich parsery implementovat velice efektivně a mnoho používaných jazyků má LR gramatiku (jedna z výjimek je třeba Perl). Méně příjemné je to, že ruční konstrukce těchto parserů je obtížná a spousta lidí dává přednost generátorům analyzátorů. V závislosti na způsobu vytváření tabulky se tyto generované parsery dělí na SLR (Simple LR), LALR (look-ahead LR), Canonical LR a jiné.
SLR gramatiky jsou téměř identické s LR(0) gramatikami. Jedná se o nejjednodušší typ a pro mnoho jazyků je zcela nedostatečný. LALR parsery již dokáží zpracovat gramatiky LR(1) a velice dlouhou dobu byly oblíbené, protože dokáží vyjádřit více, než SLR gramatiky, přičemž je jejich parsovací tabulka rozumně velká.
Algoritmus LR parseru (i jeho tabulka) je daleko složitější. Občas se jim říká shift-reduce a to podle operací posun a redukce, které obsahují. Jejich princip spočívá v tom, že postupně redukují vstupní řetězec w pomocí pravých stran derivačních pravidel tak, až dojdou ke startovacímu symbolu gramatiky. A dále je tu i GOTO tabulka, která zobrazuje přechody mezi jednotlivými stavy automatu. Zájemce odkáži na popis ve wikipedii (Architecture of LR parsers).
Earley parser (top-down) je pojmenován po svém tvůrci, kterým je Jay Earley. Tento parser dokáže zpracovat libovolnou bezkontextovou gramatiku. Jeho složitost je kvadratická až kubická, ovšem při použití tohoto způsobu parsování není třeba gramatiku nikterak omezovat
. Nejlepší výsledky dává s gramatikami, které jsou zleva rekurzivní. Tento algoritmus implementují některé nástroje.
CYK, neboli Cocke-Younger-Kasami parser (bottom-up). Jeho algoritmus je velice jednoduchý, zápis v pseudojazyce zabírá 14 řádků a jeho implementace v C++ (včetně pomocných operátorů) přibližně 200 řádků. Nejhorší asymptotická složitost je kubická, což znamená, že je srovnatelný s Earleyho algoritmem. Ve své základní podobě vyžaduje, aby byla gramatika zapsána v Chomského normální formě, ale dá se rozšířit tak, aby používala libovolně zapsanou gramatiku.
Nejen pro sportovce, ale i pro gramatiky je důležitá forma. Před chvílí zmíněná Chomského normální forma znamená jistý způsob zápisu derivačních pravidel gramatiky, které ovšem přinášejí zajímavé vlastnosti. CNF je gramatika s pravidly ve tvaru
Dá se dokázat, že každá gramatika v Chomského normální formě je bezkontextová a navíc, že každá bezkontextová gramatika se dá převést na Chomského normální formu. Výhodou je, že při parsování produkuje binární strom, jehož výška je omezená velikostí největšího řetězce. Nebo fakt, že zpracování každého řetězce bude trvat 2n - 1 derivačních kroků, kde n je délka řetězce.
Ovšem daleko známější než Chomského forma, bude zcela určitě extended Backus Noam form — EBNF, která vznikla zjednodušením původní Backus-Noam formy (BNF). Například jazyk Algol-60 byl první jazykem, který byl popsán BNF. Tedy vznikla... vytvořil jí známý (a zde několikrát vzpomenutý) Niclaus Wirth. Postupem času se z ní stala norma ISO-14977. Skupina w3c používá upravenou verzi pro definici formátu XML a další varianta Augmented BNF se stala dopručením (RFC) číslo 4234 organizace IETF.
EBNF představuje často používaný způsob zápisu gramatik i proto, že jej mnoho lidí považuje za přehlednější než klasický zápis (nepotřebuje šipky a podobné speciální symboly). Navíc, pokud existuje k nějakému jazyku norma, bývá jeho syntaxe právě v této formě. Existuje jak grafická, tak i textová forma zápisu. Pro výše vzpomenutou podmínku if jazyka C existuje EBNF zápis
selection-statement:
if, '(', expression, ')', statement, [ else, statement ] |
switch, '(', expression, ')', statement
a jemu odpovídající grafická forma
![]()
V tomto díle jsme si představili teorii, která se zabývá parsováním zdrojového kódu. To je také důvod, proč obyčejné regulární výrazy nemohou nikdy nahradit plnohodnotný parser. Regulární jazyk nikdy nemůže obsáhnout gramatiku napsanou v bezkontextovém jazyce. Je ovšem třeba poznamenat, že tohle se týká především jazyků algolského typu. Existují programovací jazyky, které se obejdou i bez složitě definované gramatiky se spoustou syntaxe a které můžeme obsáhnout regulárním jazykem. Ovšem ty bývají většinou programátorů považovány za divné
a nepraktické. Příkladem může být Lisp, Fort anebo třeba Brainfuck (který je ovšem skutečně nepraktický). V příštím díle, který bude opět více praktický, si představíme generátory analyzátorů, protože je jejich ruční psaní nepochybně složitější než psaní lexikálního analyzátoru.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 .
.
C++ is an extraordinarily difficult programming language to parse.Podobně obtížné je parsování perlu. V podstatě je to tak složité, že jediný parser perlu je perl samotný. Pokud vím, tak používá upravenou verzi bisonu.
gamma = (alpha) + beta;
Tohle by udelalo chybu i v Perlu. Myslim, ze autor zamyslel napsat:
printf("%s\n", s) if (n == 10);
 Vždyť je tam uveden ten objektový jazyk nejobjektovějších, ten nejhezčí z nejhezčích, Smalltalk S tím se jav či C# nemůžou naprosto srovnávat... to jsou proti němu ubohé bezmeky
Vždyť je tam uveden ten objektový jazyk nejobjektovějších, ten nejhezčí z nejhezčích, Smalltalk S tím se jav či C# nemůžou naprosto srovnávat... to jsou proti němu ubohé bezmeky  I když já přesto radši Python, ač není tak čistoskvoucí jako Smalltalk
I když já přesto radši Python, ač není tak čistoskvoucí jako Smalltalk
if: tam standardně není, patří tam ifTrue:. I když syntakticky to dobře je a doprogramovat metodu if:, tak, aby se dala zaměnit s ifTrue: je tak jednoduché, až to hezké není .
U příjemce ifTrue: měly být obyčejné závorky, blok zde nedává smysl. Dále n je celočíselný objekt, která nezná zprávu čárka, takže by se této proměnné měla poslat nejdříve zpráva asString, a navíc se ten kód funkčně neshoduje s tím v C. Ale i tak to je syntakticky stále validní smalltalkovský kód.
Našel sem i nějaké prezentační video kde autoři mluví o Selfu, ale žádné skutečně použitelné materiály ne. Z toho vyhledávání mi přišlo, že je to bohužel mrtvý jazyk... krásný projekt, který však nikdy nebyl programátorskou veřejností nějak víc vzat v potaz...
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 1.9.2006 09:03
1.9.2006 09:03
 5.9.2006 01:02
5.9.2006 01:02