V aktuálním přehledu vývoje renderovacího jádra webového prohlížeče Servo (Wikipedie) bylo oznámeno vydání nové verze 0.4.0. Výrazně se zlepšilo vykreslování stránek jako lichess.org, Zulip nebo Speedtest.
Vládní CERT upozorňuje (𝕏) na kritické zranitelnosti v produktech VMware: CVE-2026-59309, CVE-2026-59310 a CVE-2026-47876. Zranitelnosti v VMware vCenter umožňují vzdálenému útočníkovi se síťovým přístupem obejít autentizaci a získat neoprávněný přístup k vCenter, případně zneužít directory traversal ke spuštění libovolného kódu na vCenter.
Společnost Coinkite upozorňuje na bezpečnostní chybu svých hardwarových kryptopeněženek Coldcard. Jedná se o kritickou chybu v generování náhodných čísel (RNG). Místo hardwarového generátoru náhodných čísel (TRNG) byl omylem používán softwarový fallback (PRNG).
Představena byla nová linuxová distribuce Shadowfetch Linux. Na rozdíl od mnoha nováčků, které nabízejí převážně jiné téma a výběr softwaru, tato distribuce založená na Debianu Testing s desktopovým prostředím KDE Plasma 6.6, klade lokálně běžící umělou inteligenci do centra svého desktopového zážitku.
Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.

Dnešní díl se věnuje se technologii superfetch, správě procesů a sledování výkonu systému. Nudu a šeď těchto témat jsem se pokusil vyvážit nadstandardním počtem obrázku… a také tím, že vám už dopředu prozradím, že Vista to tentokrát docela nekompromisně vyhrála. Bez bulvarizace úvodníku to v dnešním světě asi nejde 
Disková cache v pamětí počítače má i přes svoje nesporné výhody řadu problémů.
Neexistuje ani opačná možnost, tedy naznačit systému, že některá data budu používat často a má se je snažit držet v paměti dokud to jen jde. Systém má k dispozici jen svůj algoritmus nejčastěji založený na LRU.
Pokus o řešení prvních dvou a částečně i třetího problému od soudruhů z Redmondu se nazývá Superfetch. Za základě pozorování chování uživatele v určitých dnech a denní době se snaží předvídat, která data bude uživatel potřebovat a aktivně je načítá do diskové cache s nejnižší IO prioritou. Podstatné je, že přitom jde na nižší úroveň než jsou soubory- načítá jen jejich potřebné části. Mnozí uživatelé tuto funkci vypínají a nejčastější příčinou je… špatně odhlučněný disk. Disk čtoucí data s iddle IO prioritou práci neovlivní a jediným projevem je chroupání disku. Jiný důvod než výše zmíněný mě tedy nenapadá.
Funguje to v praxi? Čím je chování uživatele ze statistického hlediska více předvídatelné, tím lépe. Pokud pracujete se stejnou nepříliš velkou sadou aplikací (což je nejčastější případ na pracovních/kancelářských počítačích) pak budete profitovat nejvíce. V takových situacích je rychlost prvního spouštění aplikace v podstatě stejná jako opakované spuštění téže aplikace. Stejně tak načtení projektu je výrazně urychlené pokud delší dobu pracujete na stejném. Abych nezapomněl… chce to alespoň 2 GiB paměti.
Zkrátka a dobře- pokud si každý pátek pravidelně spouštíte hudební přehrávač a v něm T.G.I.F od skupiny Lonestar tak ty věci už budete mít přednačtené v paměti
Hodnotit těžko, když Linuxu chybí protikus.Vista má zkrátka velký plus za krok správným směrem při řešení jednoho z nejnepříjemnějších úzkých hrdel současných systémů.
K základní manipulaci s procesy a sledování zátěže procesoru, paměti a sítě slouží správce úloh neboli Task Manager. Spouští se trojhmatem Ctrl+Shift+Esc, který by měl současně zaručit přenesení focusu na správce ať se systém nachází v jakémkoliv stavu. Často je to jediný způsob jak odpravit třeba zaseknutou hru okupující fullscreen.
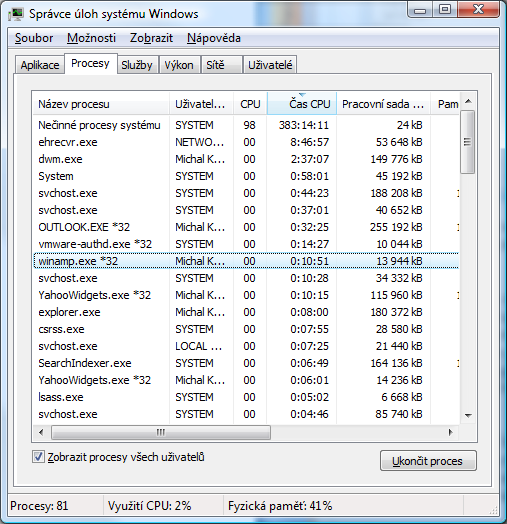
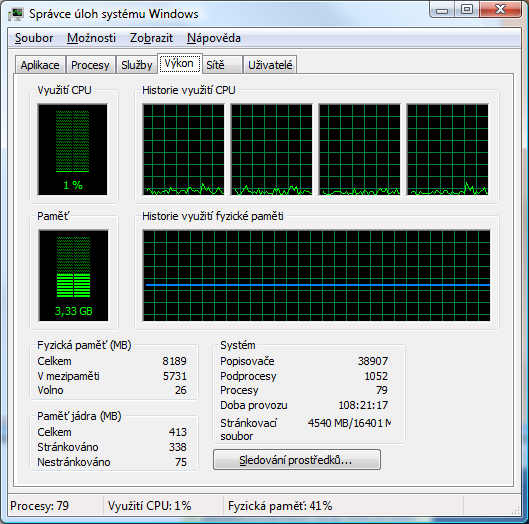
Správce úloh, krom vraždění úloh (či hromadných vražd v podobě zabití celého podstromu procesů) dokáže také nastavit jejich prioritu a afinitu neboli přiřazení jednotlivým procesorům. Tato vlastnost tam je snad už od doby NT, ale poměrně málo se o ní ví. Přitom v XP, které nerozuměly vícejádrovým procesorům se sdílenou cache paměti, se dalo správným rozvržením úloh docílit zajímavého nárůstu výkonu. Ve Vistě to už není nutné. Příjemnou novinkou je možnost kliknout na svchost.exe (do těchto procesů se zapouzdřují systémové služby), zvolit z kontextové nabídky přejít na službu a zjistit tak, které služby přesně jsou v daném procesu schovány. Pomocí značky *32 jsou označeny 32bit procesy. Jen málokterá nesystémová aplikace takto označená není, ale to je zase námět na jinou pohádku.
Volně ke stažení je nástroj Process Explorer z kolekce Sysinternals, který je takovým task managerem v DeLuxe provedení. Umí zobrazit mnohem více informací jak sumarických tak k jednotlivým procesům (proměnné prostředí, navázané TCP spojení, vlákna, hodnoty bezpečnostního tokenu...). Umí najít okno k procesu a proces k oknu. Zkrátka je to takový multifunkční kombajn na správu a sledování procesů.
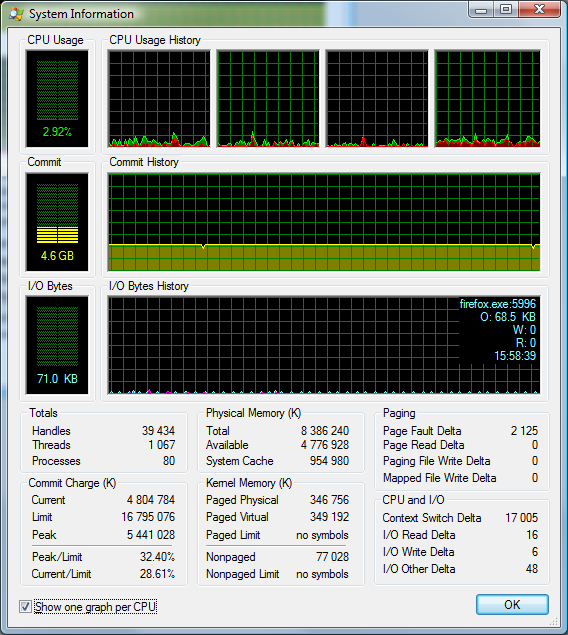
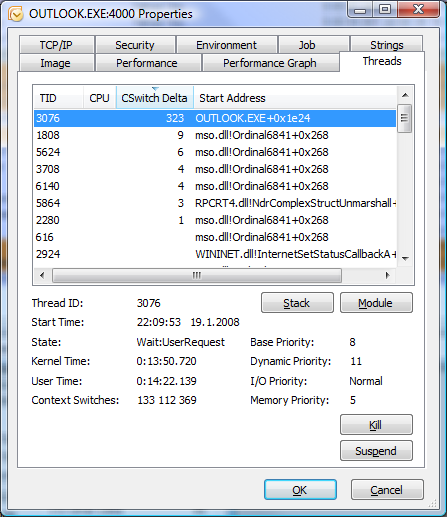
Nástroj "Sledování prostředků" je integrován přímo v systému a slouží k identifikaci procesů, které nejvíce v daném časovém období vytížily počítač z hlediska procesoru, paměti (hlavním kritériem je zde počet page faults), disku a sítě. Zejména poslední dvě položky jsou zajímavé. Pohled na záložku disk umožňuje zobrazit, který proces přistupoval ke kterému souboru a kolik bajtů přečetl/zapsal. V záložce síť je to podobné- který proces přenesl z/na kterou adresu kolik bajtů. Zkrátka odpověď na dotaz "proč mi pořád chroupe disk" naleznete zde.
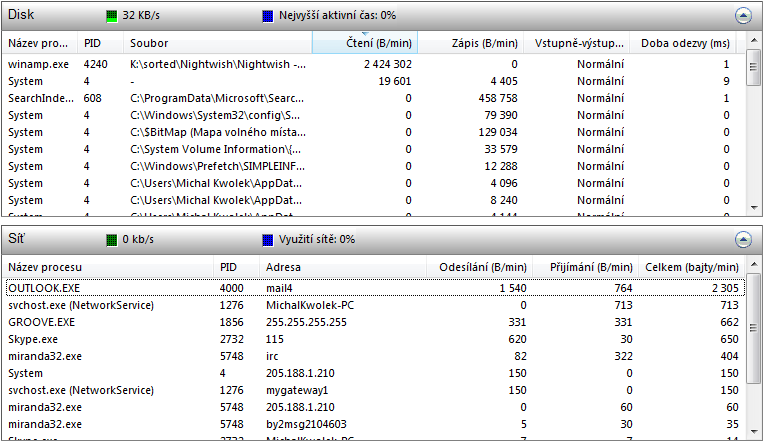
Zajímavým nástrojem v této kategorii je "Sledování výkonu". Umožňuje vynést do grafu libovolný počet z mnoha možných sledovaných číselných hodnot (čítačů), sledovat maximum, minimum a průměr dané hodnoty. Množství sledovaných hodnot je vskutku impozantní, od sledování zatížení procesoru přes počet zavedených tříd v .NET runtime, procentuální úspěšnost diskové vyrovnávací paměti až po počet odeslaných Echo zpráv přes ICMPv6. Řádově stovky. Mnoho sledovaných údajů má navíc tzv. instance. Třeba při sledování počtu přerušení lze zvolit buďto sumární hodnotu nebo zvolit konkrétní jádro procesoru, které nás zajímá. Zkrátka pokud se v tom moři (bohužel lokalizovaných) parametrů dokážete zorientovat, tak budete jistě nadšení. Aby toho nebylo málo, tak jde do jednoho grafu vynést hodnoty z několika počítačů místní (nebo přes VPN propojené) sítě. Abych jen nechválil, konkrétně u těch přerušení jsem nenašel možnost zobrazit zvlášť každé přerušení, což je docela zajímavý údaj a Linux ho v /proc/interrupts nabízí.
Pokud řešíte nějaký problém projevující se za určitých konkrétních okolností tak je nejlepším řešením vytvoření tzv. sady kolekce dat. V podstatě se jedná o vytvoření předpisu, které hodnoty ze "Sledování Výkonu" se mají zaznamenávat a v jakém intervalu. Dále je možné zaznamenávat události jdoucí do logu prohnané vlastním filtrem (což je samo o sobě zajímavé vzhledem k podrobnosti logu, viz předchozí díly). Spouští může být časový údaj nebo nějaká událost zapsána do logu. Podobně nastavitelný je i konec logování. Všechna data za měřené období se zaznamenávají do několika (žel až na výsledný report binárnách) souborů. Výsledky lze zobrazit v podobě grafů nebo reportu. Existuje samozřejmě možnost zaznamenávat i hodnoty ze vzdálených serverů a vidět tak v jednom kontextu jak se třeba mění zátěž databázového serveru a současně webserveru. Když všechny tyto vlastnosti sečtete dohromady vznikne neuvěřitelně mocný nástroj pro lokalizaci problémů všeho druhu.
Teď k hodnocení. Je to docela problém. Jak rozlišit velmi dobré možnosti Linuxu, beze sporu ještě lepší možnosti Visty a naprosto ultimátní možnosti Sunovského DTRACE? Jinak než dát Vistě dvojku a Linuxu trojku to nejde. Váha: 2.
Příští díl by určitě měl rozvinout dnes nakousnuté téma 64bit aplikací. Pro odlehčení bych tam chtěl zařadit jedno z flamovacích témat, které mám v zásobě a to buďto widgety, gadgety, screenlety, desklety a podobné příšery nebo písma a jejich vyhlazování.
![Dávám Windows šanci aneb Vista z pohledu Linuxáka [6], obrázek 7](/images/screenshots/9/1/107319-davam-windows-sanci-aneb-vista-z-pohledu-linuxaka--6--6001.png)
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 26.1.2008 18:52
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
26.1.2008 18:52
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Hodnotit těžko, když Linuxu chybí protikus.Vista má zkrátka velký plus za krok správným směrem při řešení jednoho z nejnepříjemnějších úzkých hrdel současných systémů.V Linuxu se vyskytuje nanejvýš (v některých distribucích) to, že se přednačtou soubory ze staticky definovaného seznamu. Čili i když používám KDE, nachroustají se tam kvanta dat pro GNOME apod., která vůbec nebudu potřebovat. Už jsem se o zmiňoval ("Chytrý přednačítač") o tom, jak hodně je potřeba to vyřešit. Do jisté míry se to také řešilo tady, ale reálné výsledky nevidím.
 26.1.2008 20:01
Josef Kufner | skóre: 70
26.1.2008 20:14
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
26.1.2008 20:40
Josef Kufner | skóre: 70
26.1.2008 20:44
Josef Kufner | skóre: 70
26.1.2008 21:55
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
26.1.2008 20:01
Josef Kufner | skóre: 70
26.1.2008 20:14
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
26.1.2008 20:40
Josef Kufner | skóre: 70
26.1.2008 20:44
Josef Kufner | skóre: 70
26.1.2008 21:55
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Vůbec se nedivim, že se do toho nikomu nechce, když to s příchodem "masově použitelnejch" SSD disků již brzy prakticky nebude potřeba.
27.1.2008 00:46
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Problém se SATA2 bych neviděl, do té doby vzniknou rychlejší sběrnice (nehledě na to, že SSD může být třeba i přímo na kartě připojované do PCI Express).
Pokud si myslis, ze v dobe SSD disku nebude cache zapotrebi tak se asi pletes
Rozhodně si nemyslim, že bude zbytečná cache. Ale prefetch™ tak jak je dneska znám z Vist, tzn. odhad, dle nějakého "magického" algoritmu co by asi tak uživatel mohl chtít spustit.
V linuxu jsou mnohem horší "Achilovy paty", co se týče desktopu, například katastrofálně pomalé (co se "reakční doby" týče) gtk, které by potřebovaly vylepšit, prefetch je až to poslední co hoří*. Ono totiž existují tři scénáře využití aplikace:
* než si tady zase nějakej "linuxák" začne otvírat hubu, jak jemu na jeho "hyper ultra mega" stroji běží v linuxu i Firefox krásně rychle, poznamenám, že spravuju firemní linux síť s ~30PC, reálným HW, a naprostými BFU uživateli, takže mám velmi dobrou představu o tom, co na linuxovém desktopu nejvíc hoří (tzn. na co uživatelé nejvíce nadávají a argumentují při tom: "Ale ve Windows...").
27.1.2008 14:30
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
A pak uz jen takova drobnost v podobe ceny ~250Kc/GB.Takže budou asi malé. Pak se teda bude muset řešit úloha, které soubory dát na rychlý disk a který na velký disk (a kdy...). Co mi to připomíná?
 27.1.2008 00:42
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
27.1.2008 00:42
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
 Skor je to vystizny postreh
Skor je to vystizny postreh
Zajímavým nástrojem v této kategorii je "Sledování výkonu". Umožňuje vynést do grafu libovolný počet z mnoha možných sledovaných číselných hodnot (čítačů), sledovat maximum, minimum a průměr dané hodnoty. Množství sledovaných hodnot je vskutku impozantní, od sledování zatížení procesoru přes počet zavedených tříd v .NET runtime, procentuální úspěšnost diskové vyrovnávací paměti až po počet odeslaných Echo zpráv přes ICMPv6.Mám pocit, že něco podobného v menším provedení bylo již ve Windows 95 nebo 98. V XP jsem to neviděl, zdá se, že to zase vzkřísili.
 26.1.2008 22:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
28.1.2008 07:28
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
26.1.2008 20:04
Josef Kufner | skóre: 70
26.1.2008 22:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
28.1.2008 07:28
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
26.1.2008 20:04
Josef Kufner | skóre: 70
 26.1.2008 20:33
rADOn | skóre: 44
| blog: bloK
| Praha
26.1.2008 22:00
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
26.1.2008 20:33
rADOn | skóre: 44
| blog: bloK
| Praha
26.1.2008 22:00
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Superfetch je jiste fain ale rekl bych ze pripojeni tmpfs do /tmp a spravnej IO planovac resi plusminus to samy. ano, nekesujou se tak hezky binarky ale to AFAIK ani ve vistach uz moc ne pacz si tam kazda app muze drzet vlastni instance dllek.To není pravda. Kvalitní I/O plánovač je samozřejmost, o tom není třeba diskutovat. Ale problém neřeší. Neřeší ho ani použití tmpfs, protože mnoho programů vůbec s dočasnými soubory nepracuje. Největší brzdou je načítání mnoha malých souborů, zejména pokud jsou rozcourané po disku. Tam by chytré přednačítání mohlo výrazně pomoci - zejména tam, kde je po startu velká část paměti nevyužitá a mohla by se bez problémů využít právě k přednačtení souborů, které budou v nejbližších chvílích použity.
Největší brzdou je načítání mnoha malých souborů, zejména pokud jsou rozcourané po disku. Tam by chytré přednačítání mohlo výrazně pomoci - zejména tam, kde je po startu velká část paměti nevyužitá a mohla by se bez problémů využít právě k přednačtení souborů, které budou v nejbližších chvílích použity.To by slo realizovat i bez sahani do jadra, stacilo by jen sledovat syscally open, read a mmap (myslim, ze tyhle tri staci, nebo ne?), pripadne pres preload knihovny zahakovat jim odopvidajici funkce z libc. Pak je treba jen udaje ulozit, vyhodnotit a podle nich pri staru nekde v initscriptech spustit demona, co bude mit nizkou I/O prioritu (pres ionice -c 3) a seznam souboru, co proste jen otevre a precte, pripadne seznam rozsahu odkud-pokud ma soubor precist.
27.1.2008 00:55
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
To by slo realizovat i bez sahani do jadra, stacilo by jen sledovat syscally open, read a mmap (myslim, ze tyhle tri staci, nebo ne?), pripadne pres preload knihovny zahakovat jim odopvidajici funkce z libc.To nestačí. Např. při použitím mmap() by to sledovalo jen samotné namapování, ale už ne skutečné využití (tj. kam to doopravdy sahá). Nehledě na řadu dalších volání. Pokud bych chtěl sledovat jen přístup k souborům, stačilo by využít inotify - bez nutnosti kamkoliv hrabat. I když nevím, jaké by to mělo výkonnostní dopady, protože by to znamenalo vytvořit na každém adresáři v systému jeden watch. Někdy to zkusím změřit.
Pak je treba jen udaje ulozit, vyhodnotit a podle nich pri staru nekde v initscriptech spustit demona, co bude mit nizkou I/O prioritu (pres ionice -c 3) a seznam souboru, co proste jen otevre a precte, pripadne seznam rozsahu odkud-pokud ma soubor precist.Takového démona už někde mám, ale je (stručně řečeno) k prdu. Aby to mělo smysl, musí takový démon fungovat dynamicky, tedy na základě dat, které má k dispozici, volit v reálném čase soubory k přednačítání (např. vědět, že když si spustím nějaké IDE, tak za chvíli budu potřebovat gcc). A to není vůbec triviální a jde o jádro celého pudla.
.
27.1.2008 10:28
rADOn | skóre: 44
| blog: bloK
| Praha
Kvalitní I/O plánovač je samozřejmost, o tom není třeba diskutovat.Proto jsem psal spravny a ne kvalitni, jeden planovac tezko bude optimalni pro vsechny typy zateze. Takze co jsem tim mel na mysli nebyl jeden nejlepsi™ planovac ale moznost vybrat si.
Největší brzdou je načítání mnoha malých souborů...Stejny pripad - zalezi na vyberu, tentokrat filesystemu. Tahle moznost me ani nenapadla, uz jsem moc dlouho mimo widli eko(no)system abych vyber filesystemu povazoval za neco mimoradnyho. Vzato kolem a kolem, cim vic to tady ctu tim vic mam pocit ze superfetch bude pro widle velky zlepseni ale ze je to jen skryvani priznaku a ne reseni zdroje problemu.
27.1.2008 10:49
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Stejny pripad - zalezi na vyberu, tentokrat filesystemu.
No to ani ne. Pokud hlavička disku bude poskakovat po plotně - protože pořadí načítání jednotlivých souborů je jiné, jako jejich uspořádání na disku - tak každý FS pohoří. Najít uspořádání dat na disku tak, aby vyhovovalo všem situacím je v podstatě nemožné. V podstatě by to šlo částečně řešit změnou API tak, že OS dostane od aplikace seznam souborů, které daná app bude potřebovat - namísto součastného otevířání po jednom - a OS už ví, jak jsou ty soubory na disku a v tomto pořadí je může načíst.
28.1.2008 10:48
rADOn | skóre: 44
| blog: bloK
| Praha
Pokud hlavička disku bude poskakovat po plotně - protože pořadí načítání jednotlivých souborů je jiné, jako jejich uspořádání na disku - tak každý FS pohoří.... a prave proto maji filesystemy pro pevne disky veci jako interni cache, readahead buffery a antifragmentacni algoritmy. Mozna se to bude zdat neuveritelne, ale vyvojari filesystemu nejsou az TAK pitomi.
28.1.2008 11:04
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
podľa mňa sa snažíte vyhnúť sa dôsledku, a nie príčine.
Nějak si nedovedu představit, že bych se např. před odchodem z počítačové učebny neodhlásil. Ale dejme tomu, že bych byl tak odvážný. Jak by se asi systém popral s těmi tisícovkami spuštěných a odswapovaných aplikací, se stovkami uživatelských sezení?
ad druhý odstavec ... oddeliť aplikačné data od aplikácií
28.1.2008 13:13
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Pamäte budú vždy pomalé a pomalšie. Ani SSD vám nepomôže.
btw, optimalizovať by sa malo vždy
28.1.2008 16:38
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Lenivosť programátorov naprogramovať svoje aplikácie lenivé.Snad naopak, ne? Ale jinak souhlasím.
Príklad: save dialog ... hoci nezobrazí obsah adresára, aj tak načíta jeho obsah (gtk 2.8.13)Tohle už jsme tu řešili. Typický případ špatného řešení.
Pamäte budú vždy pomalé a pomalšie. Ani SSD vám nepomôže.Není pravda. Latenci v desítkách ms mít SSD nebude. Navíc u něj nezáleží na umístění dat, takže není potřeba řešit optimalizaci vzhledem k pozici.
optimalizovať by sa malo vždyPokud se to vyplatí. Většinou nemá smysl prodloužit čas vývoje na dvojnásobek, pokud se tím získá 5% nárůst výkonu.
Snad naopak, ne? Ale jinak souhlasím.lenivé v zmysle nerobiť veci v aktuálnom čase zbytočné. Chovanie aplikácií štýlom "toto možno budem potrebovať, tak mi to priprav (thread na pozadí?), ja si neskôr na to možno počkám", a nie "toto možno budem potrebovať, tak si to teda teraz pripravím".
28.1.2008 18:44
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Myšleno zřejmě bylo psát aplikace tak, aby nedělaly hned, co mohou udělat pozdějiLenivosť programátorov naprogramovať svoje aplikácie lenivé.Snad naopak, ne? Ale jinak souhlasím.
Tedy ne lenivé z pohledu výkonu, ale z pohledu množství vykonané práce. Prostě něco jako kapitola 3.5 v SICP
Myšleno zřejmě bylo psát aplikace tak, aby nedělaly hned, co mohou udělat pozdějiTohle by bylo asi na delší diskuzi, není až tak jednoznačné, co je správně. Buď můžete
28.1.2008 21:33
Josef Kufner | skóre: 70
Ono hlavně taky ten procesor nebude stačit. Datové struktury, které Gtk používá v TreeView jsou poněkud neefektivní. Jediné co to umí jsou seznamy a stromečky, které se obtížně a pomalu procházejí a celé to trvá nechutně dlouho. Je úplně jedno jak rychlý disk bude. Než Gtk vyrobí seznam, než ho patřičný widget zobrazí, než se to seřadí, než se tam umístí kurzor,... blé... Krásným příkladem ja gmpc vs. xmms a vyhledávání v seznamu skladeb (v xmms klávesa 'j'). Při stejném množství položek v seznamu to xmms stíhá v reálném čase (rychleji než píšu na klávesnici) a gmpc asi minutu chroustá. Do zdrojáků jsem koukal a gmpc nic zvrhlého ani náročného nedělá. Položek je cca 14 297.Pamäte budú vždy pomalé a pomalšie. Ani SSD vám nepomôže.Není pravda. Latenci v desítkách ms mít SSD nebude. Navíc u něj nezáleží na umístění dat, takže není potřeba řešit optimalizaci vzhledem k pozici.
28.1.2008 21:42
Josef Kufner | skóre: 70
28.1.2008 22:25
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
28.1.2008 17:28
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
ale vyvojari filesystemu nejsou az TAK pitomi.
Ulevilo se ti alespoň? Pokud vezmu za příklad těch 100 Lukových souborů, tak všech možných pořadí jejich čtení je:
93326215443944152681699238856266700490715968264381621468592963895217\ 59999322991560894146397615651828625369792082722375825118521091686400\ 0000000000000000000000
Pro tohle nelze žádný FS optimalizovat. Kdyby ten FS dostal od aplikaci informace o souborech, které bude potřebovat, mohl by si je nachystat do cache a číst je v pořadí v jakém jsou uloženy na disku. Ve chvíly, kdyby je program skutečně potřeboval, již by byly v RAM.
plus priority, plus no-disk-cache operácie, plus runtime zmena. Aplikácia bežiaca v popredí má iné nároky ako v pozadí, a pod.
26.1.2008 22:45
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
, ale dik, nastudujem si to
27.1.2008 10:52
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Na preload se podívam. Jak už bylo ale řečeno výše, obávám se, že ádro neposkytuje nyní dostatek údajů pro běh takového démona.
27.1.2008 16:13
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
27.1.2008 14:50
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Navíc porovnáním ukazuje, co by stálo zato "okopírovat" v Linuxu.S tím okopírováním v Linuxu je to ošemetné. Mnoho věcí (zrovna třeba SuperFetch a mnoho dalších) je kryto řadou patentů. Tady nás to nemusí trápit, ale např. v USA ano a proto i když třeba implementace vznikne, v mnoha distribucích nebude.
27.1.2008 15:11
Luk | skóre: 47
| blog: Kacířské myšlenky
| Kutná Hora
Chce prokazat, ze skutecne plati, ze kazda hul ma dva konce?Spíš že každá p.... má dvě půlky

 28.1.2008 09:06
xvasek | skóre: 21
| blog:
| Zlín
A mimochodem, strace je i v ve windows (cygwinu)...
28.1.2008 09:06
xvasek | skóre: 21
| blog:
| Zlín
A mimochodem, strace je i v ve windows (cygwinu)...
 28.1.2008 10:53
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
28.1.2008 10:53
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
spustil jsem si strace na běžící procesSákryš, mě ani nenapadlo, že by to mohlo jít i takhle. Člověk se pořád učí
Díky
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz