Max Leiter v roce 2019 zkusil zprovoznit X server na iPadu (iOS). Nyní se k tématu vrátil a s pomocí LLM a balíčkovacích nástrojů Procursus rozběhl desktop s X11 i Waylandem. Jeho balíčky jsou dostupné v repozitáři xiOS.
Společnost Google Cloud dnes oznámila, že její infrastruktura a služby byly oficiálně zařazeny do Katalogu cloud computingu vedeného Digitální a informační agenturou (DIA). Tato certifikace potvrzuje, že infrastruktura a služby Google Cloud splňují přísné bezpečnostní a regulační požadavky České republiky pro provoz cloudových služeb ve veřejném sektoru.
Vůbec poprvé v historii se stát při testování digitálních služeb obrací na širokou veřejnost. Digitální a informační agentura (DIA) a Ministerstvo vnitra zvou občany k zapojení do zátěžového testu eDokladů, které od loňského podzimu prošly optimalizací aplikace a posílením infrastruktury. Test proběhne 13. srpna ve 13:00 a pro jeho úspěch bude potřeba zapojení několika desítek tisíc občanů. Zapojení do testu je zcela dobrovolné a úkol
… více »FireDragon je webový prohlížeč, doposud založený na Floorpu, jednom z forků Firefoxu s větším důrazem na ochranu soukromí a přizpůsobení uživatelského rozhraní. Spravuje ho člen komunity distribuce Garuda Linux. Nové vydání verze 13 opouští Floorp a přechází přímo na Firefox s patchi z LibreWolfu a vlastními úpravami. Dostupný je také na Flathubu.
picogame (GitHub) je malý 2D herní engine pro mikrokontroléry jako RP2040, čip uvnitř kapesní konzole Picopad. Hru napíšeš v Pythonu a vyzkoušíš ji v prohlížeči nebo desktopovém simulátoru. Až bude hotová, zkopíruješ ji na podporovanou desku. Na začátku nepotřebuješ C, sestavení firmwaru ani hardware.
Multiplatformní prohlížeč elektronických knih KOReader byl vydán ve verzi 2026.07 "Sailing Walrus". U PDF souborů s SMask lze vyčistit pozadí. Přibyla podpora Kobo v5 nebo základní podpora OPDS 2.0.
Společnost Valve sponzoruje a společnost Collabora portuje RADV (open source Vulkan ovladač pro AMD GPU z projektu Mesa) na Windows.
Starling (GitHub) je desktopové prostředí vytvořeno umělou inteligencí (s dohledem jednoho vývojáře během šesti měsíců).
Dne 30. června 2026 byla završena fyzická realizace projektu Czech National Quantum Communication Infrastructure (CZQCI), tedy České národní kvantové komunikační infrastruktury. Projekt byl realizován od 1. března 2023 a financován z Národního plánu obnovy částkou 121,6 milionu Kč. Cílem podpořeného projektu bylo vybudovat základy národní kvantové komunikační infrastruktury a ověřit možnosti jejího praktického využití. Mezi
… více »Město Šumperk se stalo terčem kybernetického útoku, chod úřadu je omezen. Zjišťuje se, jestli unikla nějaká data. Cílem hackerů byla městská datová síť. První útoky zaznamenali odborníci na informační technologie již v pondělí večer, závady se ale plně projevily až dnes ráno. Město událost nahlásilo Národnímu úřadu pro kybernetickou a informační bezpečnost (NUKIB).
9.8.2021 06:06
| Přečteno: 4934×
| Meteopress
|  | poslední úprava: 6.8.2022 13:58
| poslední úprava: 6.8.2022 13:58
Pro debugování jakéhokoli systému zpracovávajícího rádiové signály se extrémně hodí umět si nakreslit waterfall (a.k.a. spektrogram či Short-time Fourier transform), který zobrazí, jaké frekvence se v jakém čase v signále vyskytují.
Začíná seriál DSP kuchařka o zpracování číslicových signálů, zaměřený především na rádiové signály. Je to kuchařka, ne rigorózní výklad, sorryjako. Příklady programů budou především v Pythonu, ale pro skutečné nasazení to nejspíš budete muset napsat v něčem rychlejším, třeba v C podle návodu co vyšel minule.
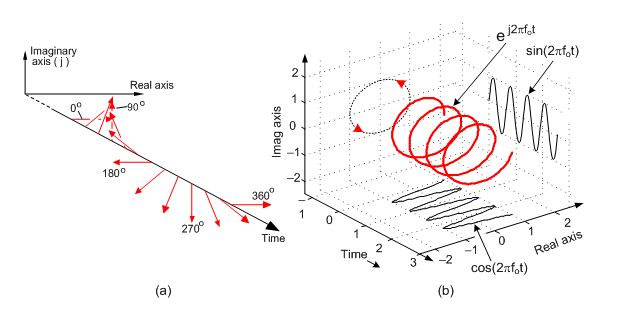
Na rozdíl od zvuku, kde se pracuje s reálnými vzorky, které vyjadřují něco jako okamžitý tlak vzduchu v daném čase, se u rádií signál reprezentuje komplexními vzorky. V počítači se reprezentují nejčastěji dvojicí (reálná část, imaginární část), označováno jako I a Q, nicméně při uvažování o problémech bývá užitečnější se na to dívat jako na dvojici (amplituda (absolutní hodnota), fáze) (označováno většinou r a phi). Na první pohled se může zdát použití komplexních čísel jako zbytečná komplikace - z antény nám přece vede jeden drát, na kterém je reálné napětí - ale věřte mi, je to opravdu mnohem lepší než se snažit provádět výpočty s reálnými čísly. Detailní popis naleznete třeba v článku tady, ilustrované příručce tady a nekonečném množství zdrojů tady. Několik bodů nutných pro tento zápisek:
U reálného signálu po jeho navzorkování rychlostí fs získáme signál s frekvencemi od 0 do fs/2, pokud si zkusíte nakreslit „rychlejší sinusovku“ a „položit na ni vzorky“, zjistíte, že pro fs/2 leží všechny na přímce (tj. nedokážeme takový signál odlišit od stejnosměrného) a pro vyšší navzorkujeme sinusovky s frekvencemi zase od nuly. Animace, obrázek.
(Zatím ignorujeme úmyslné podvzorkování a periodičnost spektra, to budeme řešit v příštím díle.)
U komplexního signálu vzorkovaného rychlostí fs získáme frekvence od -fs/2 do +fs/2, což tedy neznamená, že jsme ušetřili hardware, zase potřebujeme dvoukanálový převodník, ze kterého lezou I a Q složky, nebo 2x rychlejší jednokanálový a komplexní signál z toho udělat softwarově. Intuice za zápornými frekvencemi je taková, že vzorkujeme polohu bodu v komplexní rovině, a ten může obíhat buď po směru, nebo proti směru hodinových ručiček, a to je kladná, nebo záporná frekvence.
FFT se dá používat ke dvěma věcem (a určitě i mnoha dalším):
Co se stane, když do FFT strčíme kousek navzorkovaného komplexního signálu (délky N)? FFT počítá tohle:
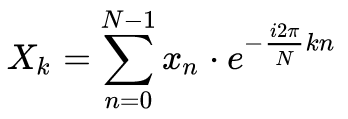
Tj. pro každý prvek výstupu (k) to projde celý vstup (postupně všechny prvky xn - proto má také naivní implementace složitost O(N2)) a vynásobí ho to nějakou zběsilostí, která se postupně mění podle n (ještě je tam N, to je konstanta - zvolili jsme si ji tím, jak dlouhý signál jsme do toho vložili; k, což záleží na tom, na který prvek výstupu se zrovna koukáme; 2π, což je úplně konstanta, a i, což vyřešíme právě teď). Jak vypadá e-i*postupně_se_zvětšující_číslo? Je to komplexní číslo a nakreslíme si ho v komplexní rovině:
import numpy as np
import matplotlib.pyplot as plt
args = np.linspace(0,6,30)
e = np.exp(-1j*args)
x = np.real(e)
y = np.imag(e)
plt.scatter(x, y)
for i in range(len(args)):
plt.annotate("e^-i*%.2f"%args[i], (x[i], y[i]))
plt.axvline(0)
plt.axhline(0)
plt.show()
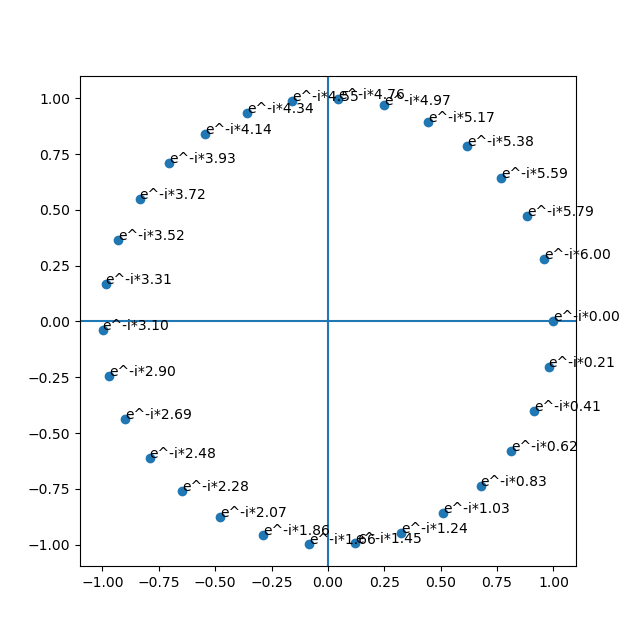
Je to tedy něco, co postupně rotuje po jednotkové kružnici, jako na tom obrázku z úvodu. (této věci se taky říká rotátor) Pak tam jsou ještě ty škálovací faktory - konkrétně k, které říká, jak rychle to má rotovat. Tedy vlastně v různých prvcích výstupního pole bude vynásobení vstupního signálu s různě rychle rotující komplexní exponenciálou. A co vlastně znamená tohle násobení po prvcích? No, pokud si signály „budou podobné“, tak se vždycky bude násobit velké kladné číslo s velkým kladným číslem, velké záporné číslo s velkým záporným číslem, malé číslo s malým číslem atd. a když se to všechno sečte, tak výsledkem bude velké číslo. Naopak pokud si podobné nebudou, tak se budou násobit různá náhodná čísla mezi sebou a výsledek bude „skoro nula“ protože se to navzájem vyruší. V každém prvku výstupu je tedy napsáno, jak moc si je vstup podobný s rotátorem o nějaké frekvenci. A ještě tím, jak je to celé komplexní, tak tam ve skutečnosti je absolutní hodnota - jak moc jsou si absolutně podobní - a fáze - jak moc jsou navzájem posunutí.
Ještě je potřeba trochu dořešit jednotky. n/N je číslo, které jde od 0 do 1, protože n jde od 0 o N (resp. do N-1, ale whatever). Pak tam je 2π, protože exp vyžaduje argument v radiánech, tak aby byla jedna otáčka od 0 do 2π. A pak je tam ještě k, což je tedy rychlost rotátoru v daném prvku výstupu. Pro k=1 to udělá jednu otočku (celý argument exp pojede od 0 do 2π), dalo by se tedy říct, že to odpovídá frekvenci 1 (myslete si třeba 1 Hz, ta věc samozřejmě neví vůbec nic o parametrech vašeho systému, takže pokud chcete znát konkrétní frekvence, musíte si to přepočítat). Pro k=2 to udělá za stejnou dobu dvě otáčky (od 0 do 4π; 2 Hz). Pro k=3 by to udělalo 3 otáčky atd. Co se ale stane, až dojedeme do půlky (k=N/2)? Rotátor se už točí tak rychle, že za jeden časový krok udělá více než polovinu otáčky, a dojde k aliasingu jako jsem ukazoval na začátku nebo jako když je ve filmu záběr na kolo rychle jedoucího auta, a zdánlivě to bude vypadat, jako kdyby se točil opačným směrem. Takže to do druhé poloviny vlastně nasype podobnost se zápornými frekvencemi.
No a pak tam je ještě celou dobu to mínus, protože to tak někdo definoval a tak to prostě je, jinak by se to točilo na druhou stranu.
Výsledek tedy vypadá tak, že první (nultý) prvek odpovídá nulové frekvenci („DC“), pak to stoupá do poloviny do fs/2, pak se to překlopí na -fs/2 a pak to zase stoupá k nule. Tohle je pro některá využití nepříjemné, protože když na to lidi koukají, tak by spíš chtěli mít to od -fs/2 do fs/2 a nulu uprostřed. Takže se někdy půlky toho výstupního pole prohodí. V numpy je na to funkce fftshift.
Vstupní signál, který budeme pomocí FFT analyzovat, bude vždycky konečný:
Nejjednodušší možnost samozřejmě je vzít ty samply z rozsahu co nás zajímá a s tím pracovat. To má ovšem nevýhodu v tom, že to má ostrý začátek a ostrý konec, a signál jakoby z nuly skočí přímo na nějakou hodnotu. Tento náhlý skok, diskontinuita, se projeví ve výsledné frekvenční analýze jako jakýsi šum, spousta různých frekvencí, které v originále ve skutečnosti nebyly. Proto se téměř vždy používá nějaké okno, což je funkce, která amplitudu signálu na začátku plynule zvýší a na konci zase plynule sníží do nuly a nedochází tak k náhlým skokům.
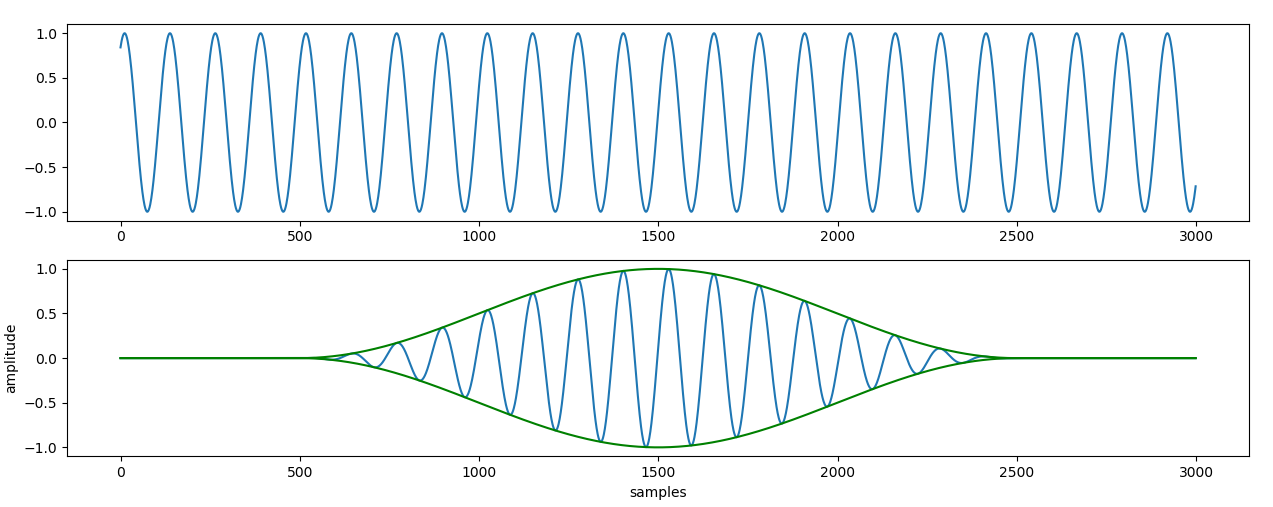
Nevýhodou pro změnu je, že jsme takhle přišli o nějakou informaci na krajích zkoumané oblasti, a frekvenční rozlišení výsledku nebude tak ostré (protože máme jakoby menší interval kde můžeme frekvenci měřit) Pokud tedy v signálu je někde jedna osamocená dominantní frekvence, tak se rozprskne do několika sousedních prvků výsledku; na druhou stranu, pokud tam byla frekvence, která by padla přesně mezi dva prvky výsledku (např. 20.5 Hz a naše rozlišení je po 1 Hz) a do žádného z nich pořádně, tak tohle to opraví.
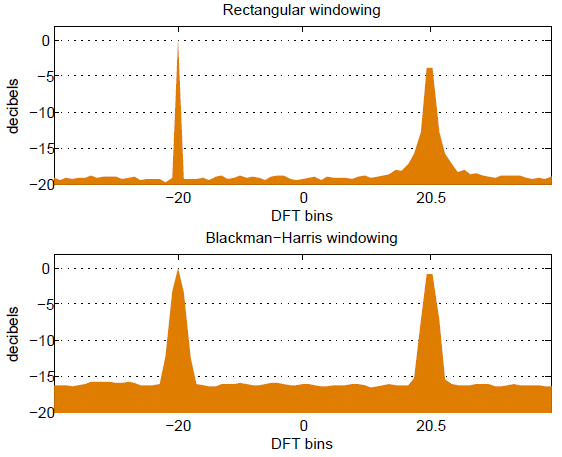
Na Wikipedii najdete hromadu různých okýnek, která jsou zvolena kompromisně mezi tím, kolik užitečného signálu nám zůstane a jak pozvolný je náběh. Osobně to neřeším a všude používám Hammingovo, a když mám pocit, že se to s ním rozbilo, tak Hannovo.
Setkal jsem se se 3 formáty, které se používají pro ukládání rádiových signálů.
np.complex64, v C complex float. Endianita se používá nativní, ale protože všichni mají little endian počítače, tak je to prostě little endian a tečka. Formát nemá žádná metadata (vzorkovací frekvence…), je to prostě soubor s vysypanými floaty. Osobně ukládám kratší metadata do názvu souboru, delší do souboru se stejným názvem a jinou příponou bokem. Výhodou formátu je dynamický rozsah a přesnost, nevýhodou poměrně velká velikost (na každý vzorek padne 8 bajtů).Takhle načteme cfile:
samples = np.fromfile("soubor.cfile", dtype=np.complex64)
S těmi dalšími je to horší, protože NumPy nemá komplexní intové typy, a navíc to stejně chceme převést do floatů, aby s tím šlo počítat. V céčku prostě načtu do bufferu int16_t a pak ve smyčce přiřazuju do pole floatů a pak to třeba přetypuju na complex float a ono se to stane samo. V NumPy:
samples = np.fromfile("soubor.i16", dtype=np.int16).astype(np.float32).view(np.complex64)
Pokud nemáte soubor na vyzkoušení, tak nahrávku z rtl-sdr ve formátu u8 jsem dealoval v předchozím zápisku. Můžete si ji stáhnout zde. Načteme ji tedy:
samples = np.fromfile("fm.bin", dtype=np.uint8) - 127.5
samples = samples.astype(np.float32).view(np.complex64)
Můžeme se podívat, jak to vypadá a že data dávají smysl (jsou to nějaké vlny, v očekávaném rozsahu zhruba -128 až 128).
import matplotlib.pyplot as plt plt.plot(np.real(samples[:10000])) plt.plot(np.imag(samples[:10000])) plt.show()
Vezmeme z toho začátek (třeba 1024 vzorků - rozumná mocnina dvojky), vyrobíme si okýnko, ztransformujeme a nakreslíme absolutní hodnotu.
win = np.hamming(1024) sample = samples[:1024] * win res = np.fft.fft(sample) plt.plot(np.abs(res)) plt.show()
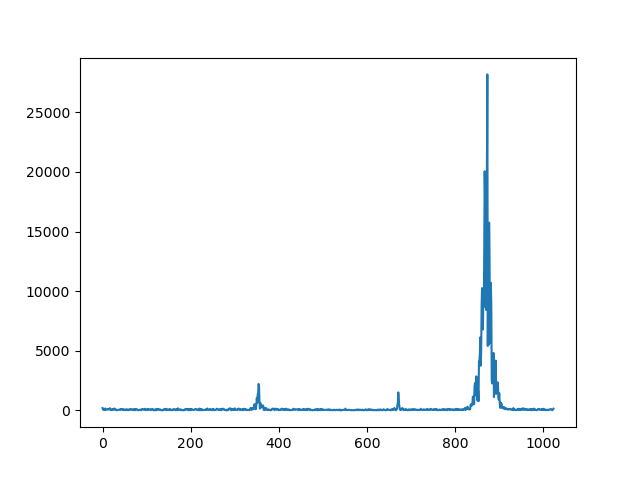
Výsledek je poněkud meh, protože hodnoty mají moc velký rozsah, což vyřešíme za chvíli zlogaritmováním. Ale něco to dělá.
Praktičtější, a minimálně pro mě vizuálně mnohem srozumitelnější, je kreslit 2D obrázek. Na jedné ose budou frekvence, na druhé ose bude čas, a barva obrázku bude kódovat výsledek FFT (resp. jeho absolutní hodnotu). Tak je vidět vývoj situace v čase. Pokud jste někdy viděli Gqrx nebo podobný software, tak tohle je přesně to, co zobrazuje. A waterfall se tomu říká, když to nahrává signál, v reálném čase ho to kreslí a stará data to posouvá dolu.
Jako první vyřešíme, jaké hodnoty budeme zobrazovat. Typicky se počítá logaritmus čtverců: 20*log10((Re2+Im2)/fftsize). Dělí se to velikostí transformace, protože FFT výsledek natahuje, jak jsem již zmínil. A pak se to ještě násobí 20 a výsledek jsou přímo decibely, což je praktické.
Dále si musíme vymyslet časové a frekvenční rozlišení. To záleží čistě na konkrétní aplikaci a volí se podle toho velikost transformace (větší transformace samozřejmě zvýší frekvenční rozlišení, ale zhorší časové, protože se kouká na delší časový úsek najednou a v rámci tohoto úseku již nejde rozlišit různé časy) a případně overlap, tj. překryv okýnek položených vedle sebe (ten je ale většinou rozumné nastavit na 0.5, tj. další okýnko vždy pokládáme tak, aby se polovinou krylo s předchozím, díky čemuž tak nějak rozumně zachytíte něco, co třeba zrovna vyšlo přesně na kraj jednoho a zrovna je to tak v místě, kde je okýnko skoro nulové). Pokud naopak chcete časové rozlišení nižší, tak se průměruje vždycky několik výsledků po sobě. Asi by se to mělo průměrovat před zlogaritmováním. No a pak se ještě občas průměruje ve směru frekvence (tj. například spočítáte FFT velkou 2048, ale kreslíte to jenom 1024 pixelů široké), protože vlivem okýnka je to trochu rozmazané a tohle tomu pomůže.
No a pak se ještě udělá fftshift, aby byla nulová frekvence uprostřed, a to je všechno. Tohle to celé vyrobí:
fftsize = 1024 win = np.hamming(fftsize) output = [] for i in range(0, len(samples)-fftsize, fftsize//2): # posouváme se vstupním polem vždy o fftsize/2 vzorků = overlap 0.5 data = samples[i:i+fftsize] * win transformed = np.fft.fft(data) power_spectrum = 20*np.fft.fftshift(np.log10((np.square(np.real(transformed))+np.square(np.imag(transformed)))/fftsize)) output.append(power_spectrum) plt.imshow(output, aspect='auto', cmap="nipy_spectral") plt.show()
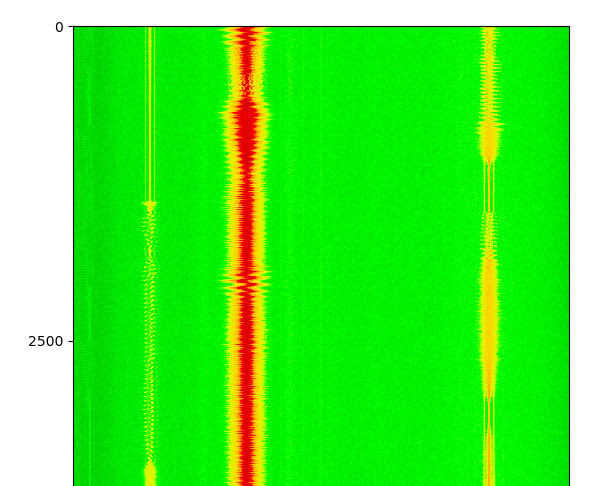
Výsledek vypadá podobně tomuto obrázku ze zápisku o GNU Radiu, no aby taky ne, když jsme spočítali to stejné, akorát tady s vyšším časovým rozlišením.
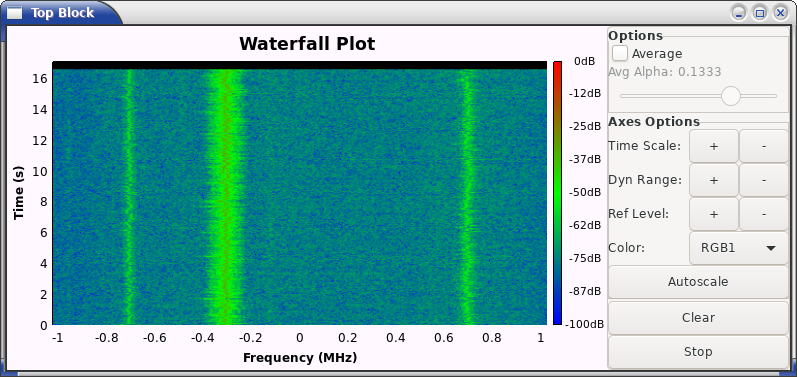
Vidíme tam tři stanice, jednu silnou a dvě slabší. Na té silné je nějaký provoz a na těch slabších je asi řeč, protože jsou tam vidět pauzy kdy se nic nevysílá (to časem nakoukáte…). Co si konkrétně ze spočítaného spektrogramu odnést záleží opravdu na tom, co zrovna děláte. Můžete takhle dělat reverzní inženýrství neznámého komunikačního protokolu, hledat rušení a zjišťovat, jestli je časově nebo frekvenčně omezené a tedy zda by šlo potlačit, nebo pokud sami signál generujete, tak si kontrolovat, jestli opravdu vypadá tak, jak si představujete.
Na internetu si přečtete, že LoRa (fyzická vrstva, kterou používá síť LoRaWAN, což je bezdrátová síť určená pro posílání párbajtových zpráv každých několik minut a je optimalizovaná na nízký odběr energie) kóduje jedničky a nuly pomocí upchirpu a downchirpu, což zároveň slouží pro rozprostírání spektra. Na spektrogramu mi to pak nekreslilo takovéto krásné patterny:
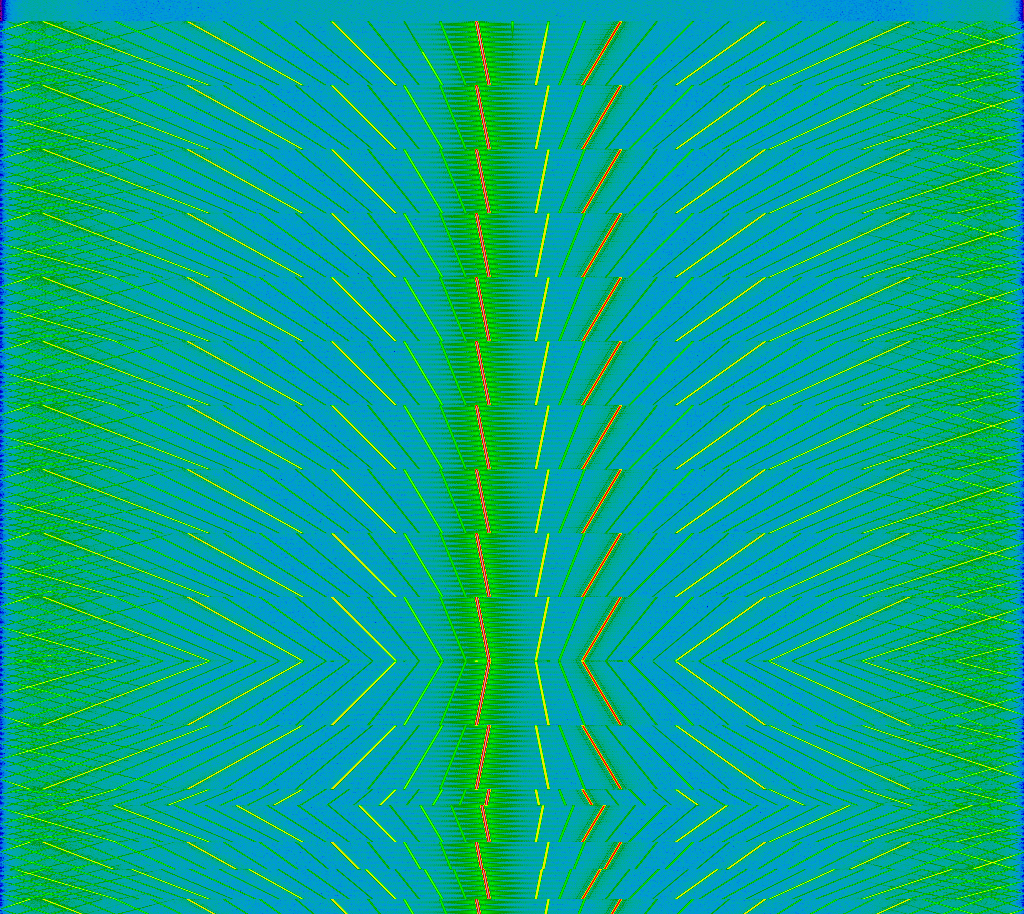
Hned tu vidíme druhý efekt, to, že tam toho je takhle strašně moc a ještě se to zrcadlí kolem nulové frekvence značí, že byl vstupní signál strašlivě silný, resp. byl nastavený strašně velký zisk ve vstupním zesilovači rádia, a došlo k brutálnímu zkreslení.
V tomto konkrétním případě šlo o mrtvé lorawanové zařízení, o kterém dodavatel tvrdil, že jemu funguje, zatímco nám nešlo registrovat do sítě. Porovnáváním záznamů z funkčního kusu a z tohoto jsme zjistili, že vysílaný signál je mnohem slabší (i když to zrovna z tohoto obrázku nevypadá  ), což jsme následně ověřili fyzicky přímo vedle lorawanové gatewaye (kde to fungovalo v pořádku - asi na 30 metrů).
), což jsme následně ověřili fyzicky přímo vedle lorawanové gatewaye (kde to fungovalo v pořádku - asi na 30 metrů).
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 9.8.2021 12:28
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
9.8.2021 12:28
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
supr vodopád :D ;D
 9.8.2021 13:20
Max | skóre: 73
| blog: Max_Devaine
9.8.2021 13:20
Max | skóre: 73
| blog: Max_Devaine
 9.8.2021 17:59
Jendа | skóre: 78
| blog: Jenda
| JO70FB
9.8.2021 21:19
Jendа | skóre: 78
| blog: Jenda
| JO70FB
9.8.2021 17:59
Jendа | skóre: 78
| blog: Jenda
| JO70FB
9.8.2021 21:19
Jendа | skóre: 78
| blog: Jenda
| JO70FB
 9.8.2021 13:36
AsciiWolf | skóre: 41
| blog: Blog
9.8.2021 13:36
AsciiWolf | skóre: 41
| blog: Blog
 9.8.2021 14:01
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
9.8.2021 17:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
9.8.2021 14:01
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
9.8.2021 17:55
Jendа | skóre: 78
| blog: Jenda
| JO70FB
 10.8.2021 20:17
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
11.8.2021 09:19
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
11.8.2021 14:40
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
10.8.2021 20:17
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
11.8.2021 09:19
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
11.8.2021 14:40
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
aby to ovšem zároveň nebyla vyloženě nějaká jejich emulace
Vtip je v tom, že s komplexními Hilbertovými prostory obvykle pracuje přímo axiomatika kvantové mechanikyNerozumim tomu, tak se možná zeptám úplně blbě: Je pro kvantovku podstatný, že imaginární část je násobek i a má to nějaké s tim spojené vlastnosti, nebo jsou to jen glorifiovaný 2d vektory?
 11.8.2021 10:56
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
11.8.2021 17:43
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
11.8.2021 10:56
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
11.8.2021 17:43
⧠ A = 0 | skóre: 11
| blog: Technokratovo_zrcadlo
| 上海
Jinak v klasické elektrodynamice se (ve standardním formalizmu) 'neobjevují komplexní čísla s Fourierovou transformací', nýbrž jsou úměle zavedena hned na začátku při řešení Maxwellových rovnic právě pro snazší analytická řešení.... čili nikoliv hned na začátku, nybrž až při řešení soustavy lineárních differenciálních rovnic pomocí Fourierovy transformace
 Maxwellovy rovnice jako takové žádné komplexní členy neobsahují (a řešení jsou taky obvykle potřeba reálná), zatímco i pitomá Schrödingerova rovnice má v sobě rovnou imaginární činitel.
Maxwellovy rovnice jako takové žádné komplexní členy neobsahují (a řešení jsou taky obvykle potřeba reálná), zatímco i pitomá Schrödingerova rovnice má v sobě rovnou imaginární činitel.
čili nikoliv hned na začátku, nybrž až při řešení soustavy lineárních differenciálních rovnic pomocí Fourierovy transformaceZ pohledu teorie elektromagnetického pole je řešení soustavy Maxwellových rovnic opravdu úplný začátek. Navíc standardně se postupuje tak, že se nejprve odvodí vlnová rovnice (hyperbolická parciální rovnice druhého řádu) a ta se následně řeší (obecně) separací proměnných.
Maxwellovy rovnice jako takové žádné komplexní členy neobsahují (a řešení jsou taky obvykle potřeba reálná), zatímco i pitomá Schrödingerova rovnice má v sobě rovnou imaginární činitel.Jenže to je právě pouze otázka použitého formalizmu. I Maxwellovy rovnice je možné vyjádřit ve formě komplexních operátorů. A stejně tak i (některé, viz dále) kvantově mechanické systémy je možné popsat bez použití aparátu komplexnich čísel tak, že se bězně používaný komplexní Hilbertův prostor zamění za prostor reálný o vyšší dimenzi. Nicméně jsem díky tomu narazil na zajímavý článek, který doporučuji (minimálně úvod a závěr): Quantum physics needs complex numbers (https://arxiv.org/pdf/2101.10873.pdf). Řeší tam otázku, zda jsou komplexní čísla v kvantové teorii jen a convenient mathematical tool or an integral part of the theory. A dochází tam ke stejnému závěru co ty. Nicméně ta argumentace je o něco komplikovanější než že ve Schrödingerově rovnici je imaginární jednotka. Člověk se pořád učí. Útěchou mi může být fakt, že: The occurrence of complex numbers within the quantum formalism has nonetheless puzzled countless physicists, including the fathers of the theory, for whom a real version of quantum physics, where states and observables are represented by real operators, seemed much more natural.
9.8.2021 20:26
Jendа | skóre: 78
| blog: Jenda
| JO70FB
10.8.2021 21:45
Jendа | skóre: 78
| blog: Jenda
| JO70FB
13.8.2021 19:44
AsciiWolf | skóre: 41
| blog: Blog
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz{kind=link}
{kind=link}