Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »
4.9.2021 16:34
| Přečteno: 5128×
| Linux
|  | poslední úprava: 4.9.2021 16:39
| poslední úprava: 4.9.2021 16:39
Ukážeme si dva nástroje pro efektivnější vývoj v C (a C++): Address Sanitizer a Perf.
V C je snadné si něčeho nevšimnout a střelit se do nohy:
-fwrapv, nebo nezarovnaný přístup do paměti) nebo minimálně podezřelého chování (například přetečení unsigned intu -- kompletní seznam). S undefined behavior mám problém hlavně v tom, že o něm vždycky někde čtu a pak si říkám co sakra všechno UB je a nechtěně jsem ho udělal.V nejlepším případě program s nějakou takovou chybou crashne hned (a tak to hned vidíte), v horším případě crashne až po dlouhé době při specifické konstelaci hvězd někde na produkci, a v nejhorším případě se tím vytvoří skrytá vzdáleně zneužitelná bezpečnostní díra.
Čtenáři zpráviček vědí, že správné řešení je přepsat všechno do Rustu, ale lidi, co to dělat neplánují, se můžou pokusit uvedené chyby nějakým asistovaným způsobem najít, i když se ještě nestihly projevit pádem programu. A k tomu právě slouží satanizéry.
Pro vysvětlení sanitizéru je potřeba udělat trochu odbočku. Mnohem starší projekt je Valgrind. Provádí binární instrumentaci existujícího kódu + nahradí některé knihovní funkce speciálními variantami: například malloc musí někam poznamenávat, jak dlouhý region je alokován (a detekuje se, jestli nepřistupujete mimo něj), a free musí poznamenávat, jaké adresy byly uvolněny, a držet je v karanténě (zatímco standardní malloc/free paměť ihned recykluje), aby se mohlo detekovat use-after-free.
(následující vysvětlení je podle toho co si pamatuju ze školy a možná to je blbě) Binární instrumentace funguje tak, že chceme přepsat kód (ve smyslu zkompilované binárky) programu tak, aby každý přístup do paměti nejdřív ověřil, že přistupuje do validního regionu - například se musí ověřit, že uvedená adresa byla alokována (mallocem nebo na stacku), že ještě nebyla uvolněna (use after free), a při čtení nás též může zajímat, že do ní bylo předtím zapsáno, tj. nejedná se o čtení neinicializované paměti. To se nedá udělat inplace, protože přidáním těchto kontrol se kód prodlouží, a my nevíme, jak zběsile můžou být někde jumpy kdo ví kam (třeba někde za chvíli bude computed jump, který bude chtít skočit doprostřed kódu, který jsme právě přepsali). Proto se program rozdělí na tzv. basic blocks, což je lineární sekvence instrukcí, které neobsahují jump, a končí jumpem. Taková sekvence se může bezpečně přepsat, někam uložit a spustit. Po jejím vykonání bude následovat jump někam, a my v cíli jumpu disassemblujeme kód až do dalšího jumpu, vyrobíme z toho další basic block (opatchovaný přidanými kontrolami) a spustíme ho. Takže na začátku vyrobíme basic block z main(), přidáme tam příslušnou instrumentaci (kontroly přístupů do paměti), a jakmile narazíme na jump, tak pokračujeme tam. Takhle při běhu programu postupně z celého spouštěného kódu vyrobíme basic blocky, mezi kterými se skáče, a samozřejmě pak se nám bude stále častěji dít, že budeme skákat na místa, která už známe, takže tu pomalou instrumentaci už nebudeme dělat znovu a použijeme již hotový basic block.
Výhoda Valgrindu je, že nepotřebuje program speciálně překompilovat (funguje s existující binárkou). Nevýhoda Valgrindu je, že vygenerované basic blocky a skákání mezi nimi je příšerně pomalé. Program se zpomalí třeba 30x. Je tak možné pod Valgrindem spustit nějaké malé automatizované testy nebo zreprodukovat konkrétní bug, ale většinou nejde program s Valgrindem normálně používat.
Sanitizéry používají instrumentaci na úrovni zdrojového kódu (a vlastní malloc stejně jako Valgrind). Před kompilací se každý přístup do pole a každá dereference pointeru obalí kontrolou a následně se program zkompiluje. To znamená, že veškeré optimalizace, které kompilátor dělá, dělá s tímto, a například o většině kontrol dokáže, že jsou redundantní a odstraní je, a ty zbylé může díky znalosti původního zdrojáku dále optimalizovat. Velkou výhodou je, že výsledný program je mnohem rychlejší než produkt Valgrindu. Podle konkrétní věci co dělá je zpomalení buď úplně neznatelné (pokud většinu času tráví nějakým výpočtem, kde nedochází k přístupům na mnoho nových míst v paměti, a tedy kontroly nemusí probíhat) nebo zhruba 2-3x (to se stalo třeba mé implementaci splay stromu, kde je spousta operací s pointery, a tedy se musí pořád kontrolovat). Program zkompilovaný se sanitizérem tak jde normálně používat a dokonce nasadit do produkce.
Velká nevýhoda sanitizérů je nutnost rekompilace. To u našeho programu typicky nevadí (když program vyvíjím, tak si ho kompiluju, že), ale není hned zjevné, že se to týká i všech použitých knihoven: představte si, že ve svém programu blbě naalokujete paměť, nesáhnete na ni (takže se nevyvolá kontrola a nepřijde se na to), a pointer na tuto paměť předáte do nějaké cizí knihovny. Následná chyba vznikne v této knihovně, která ale se sanitizérem nebyla zkompilovaná a tak se na to nepřijde, a problém je na světě. Měli byste tedy jakoby se sanitizérem překompilovat celý runtime. Problém pak ještě může nastat, když nějaká knihovna se sanitizérem zkompilovat nejde. Například se mi zdá, že si každý druhý píše vlastní alokátor (například talloc), a tyhle custom alokátory si nemusí rozumět s výše zmíněnou speciální implementací malloc a free.
Informace o tom, jakou paměť má proces namapovanou, nalezneme v souboru /proc/PID/maps. Příklad programu, který se spustil, naalokoval 30MB pole a skončil (kráceno + ručně dopsané velikosti regionů):
55674aaf8000-55674aaf9000 r-xp 00001000 fd:02 11796707 /tmp/mujprogram 7f05aec0e000-7f05aed59000 r-xp 00025000 fd:02 4456625 /lib/x86_64-linux-gnu/libc-2.31.so 55674b395000-55674b3b6000 [132 KiB] rw-p 00000000 00:00 0 [heap] 7f05acf4c000-7f05aebe9000 [30 MB] rw-p 00000000 00:00 0 7ffcd47e2000-7ffcd4803000 [132 KiB] rw-p 00000000 00:00 0 [stack] 7ffcd4869000-7ffcd486b000 [8 KiB] r-xp 00000000 00:00 0 [vdso]
Vidíme namapovaný kód programu a přilinkovaných knihoven (libc). Dále vidíme heap, anonymní alokaci, stack a VDSO.
stack roste když v programu voláme funkce víc a víc do hloubky a případně tyto funkce mají velké lokální proměnné (takové to když ve funkci jen tak napíšete int pole[1000], tak to se alokuje na stacku). Případně se dá na stacku alokovat explicitně pomocí alloca a přidružených funkcí (jako strdupa). Proces (přesněji řečeno vlákno) začíná s nějak velkým stackem (zde 132 KiB) a nestará se o tuto velikost: když si sáhne do prázdna, dojde k page faultu, a kernel mu přimapuje další stránky. Existuje nějaká maximální velikost stacku (určená asi pomocí ulimit -s), po které vás kernel odstřelí. Problém to může být v multithreadových programech na 32bit architekturách, každé vlákno má vlastní stack a v 32bit prostoru začne být těsno.
heap je to, z čeho bere paměť malloc(3). Při startu procesu je taky přidělena nějaká malá a může se zvětšovat. Na rozdíl od stacku se to neděje automaticky, ale program o to musí požádat pomocí syscallu brk(2) (konci haldy se z historických důvodů říká program break). Pomocí brk se taky může halda zmenšit když už není potřeba. Uživatel céčka ale typicky brk nevolá sám, protože používá alokátor, který to řeší za něj. Typicky to pak funguje tak, že alokátor začíná s těmi 132 KiB, programátor pak volá malloc(pár_bajtů), alokátor to bere z toho a když už to dochází, tak si přes brk vyžádá další paměť.
Anonymní alokace (mmap(2) + MAP_ANONYMOUS) je něco jako halda, ale řekli jsme tím kernelu, aby nám někam jinam do adresního prostoru dal kus paměti. To udělal alokátor automaticky, když jsem po něm chtěl 30 MB paměti. Zcela validní postup by též byl, kdyby alokátor v takovém případě pomocí brk rozšířil heap aby na něm bylo 30 MB místa a dal mi paměť z toho. Mohlo by se ovšem stát následující:
Alokátor teď ale nemůže pomocí brk haldu zmenšit a paměť vrátit kernelu, protože halda nemůže být nesouvislá a brání tam těch 32 bajtů, které pořád používáme. Takže teď zabíráme 30 MB které nevyužíváme. Tomu se +/- říká fragmentace paměti a alokátory mají různé heuristiky, jak tomu předcházet. V tomto případě heuristika rozhodla, že pro velkou alokaci (defaultní limit je asi 128 KiB) nebude zvětšovat haldu, ale vytvoří nový anonymní region. Když pak paměť uvolníme, dá se kernelu snadno vrátit. Heuristiky lze tunit pomocí funkce mallopt a pokud v programu zavoláme mallopt(M_MMAP_THRESHOLD, 31000000); (nastaví limit na 31 MB), tak to místo toho vyrobí velkou haldu a ne tu novou anonymní alokaci. (btw. tento limit má taky nějaký limit a nad 32 MB to stejně bude vždycky dělat anonymní alokace)
Alokátory jsou obecně magie se spoustou heuristik, které se snaží předcházet fragmentaci paměti a zlepšovat využití paměti. Jedna z dalších zajímavých technik je, jak optimalizovat malé alokace (krátké stringy, vrcholy binárního stromu nebo spojáku…). Typicky totiž chunk vypadá tak, že jsou nějaká metadata na začátku (např. jak je tento chunk dlouhý - aby se při free nebo realloc vědělo, kolik se má uvolnit/přesunout), pak je paměť kterou jste si vyžádali a pak jsou nějaká metadata na konci (například pointer na další volný chunk). Pokud alokujete spoustu 16bajtových objektíků, tak tato metadata sežerou víc paměti než vaše užitečná data. Proto má alokátor ještě speciální oblast na malé alokace rozdělenou třeba na 16B kousky (bezprostředně za sebou bez metadat) a někde bokem bitmapu popisující tuto oblast (v bitmapě je, které kousky jsou volné).
Další zajímavostí je alokace v multithreadových programech. Při alokaci z různých vláken se halda samozřejmě musí zamykat (aby dvě vlákna nealokovala vlivem race condition stejnou paměť) a pokud vlákna hodně alokují, tak je toto bottleneck. Alokátor tohle detekuje a rozdělí haldu na více částí, pro každé vlákno samostatně.
Osobně jsem ale tohle nikdy nepotřeboval řešit, defaultní malloc byl vždycky good enough. Setkali jste se někdy s případem, kdy by bylo potřeba alokátor ladit?
Vytvořme tedy následující program, který alokuje zadané množství paměti a pak se pokusí číst jiné množství paměti:
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv) {
// první parametr = kolik bajtů alokovat
char * a = calloc(atoi(argv[1]), 1);
// druhý parametr = kolik bajtů přečíst
for(int i = 0; i<atoi(argv[2]); i++) {
printf("%i : %02X\n", i, a[i]);
}
}
$ gcc -g -Og asan3.c -o asan3
$ ./asan3 16 40
0 : 00
[...]
38 : 32
39 : 0A
Přečetli jsme tedy data, která nám nepatřila, a nikdo si toho nevšiml. Na mém systému mi program crashne až na 134496. bajtu (což odpovídá výše zmíněné defaultní velikosti haldy 132 KiB) - teprve pak se to dostane do nenamapované oblasti za brk, dojde k page faultu a kernel zjistí že v tomto místě nemáme co dělat. Sanitizér zapneme jednoduchým přidáním parametru gcc. V některých případech se pak musela výsledná binárka spouštět s LD_PRELOAD=/usr/lib/gcc/x86_64-linux-gnu/10/libasan.so.
$ gcc -g -Og asan3.c -o asan3 -fsanitize=address
$ ./asan3 16 40
[...]
15 : 00
=================================================================
==861648==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x602000000020 at pc 0x5570bc26c26a bp 0x7ffe6f1cc7a0 sp 0x7ffe6f1cc798
READ of size 1 at 0x602000000020 thread T0
#0 0x5570bc26c269 in main /home/jenda/tmp/smrst-2018/asan3.c:10
#1 0x7f21239acd09 in __libc_start_main ../csu/libc-start.c:308
#2 0x5570bc26c0f9 in _start (/home/jenda/tmp/smrst-2018/asan3+0x10f9)
0x602000000020 is located 0 bytes to the right of 16-byte region [0x602000000010,0x602000000020)
allocated by thread T0 here:
#0 0x7f2123bf9987 in __interceptor_calloc ../../../../src/libsanitizer/asan/asan_malloc_linux.cpp:154
#1 0x5570bc26c1ef in main /home/jenda/tmp/smrst-2018/asan3.c:6
#2 0x7ffe6f1cd276 ([stack]+0x20276)
SUMMARY: AddressSanitizer: heap-buffer-overflow /home/jenda/tmp/smrst-2018/asan3.c:10 in main
Shadow bytes around the buggy address:
0x0c047fff7fb0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fc0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fd0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fe0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7ff0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x0c047fff8000: fa fa 00 00[fa]fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8010: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8020: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8030: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8040: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8050: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==861648==ABORTING
Přístup hned na další bajt (po alokovaném 15.) byl okamžitě odhalen. A díky tomu, že máme debug symboly, to rovnou vypsalo, na jakém řádku se to stalo a kde byla závadná paměť alokována.
Pro zajímavost k tomu, jak to funguje a co znamenají ta fa fa fa. Pokud se podíváte třeba do htopu zatímco program s asanem běží, tak zjistíte, že má ve sloupečku VIRT 20 TB paměti. Ale to je v pohodě, tu má jenom namapovanou a fyzicky se nepoužívá -- nejspíš to používá Copy on Write, kdy všechno ukazuje na jednu stránku, a až v okamžiku, kdy je v ní potřeba něco změnit, se stránka zduplikuje a změna se udělá v tomto duplikátu. Funguje to tak, že se vytvoří takovéto velké pole, a každý bajt v něm odpovídá 8 bajtům paměti programu. Začíná se s tím, že je celé pole popsané FA, a když alokuji paměť, tak se příslušná místa v něm vynulují. A ty kontroly, o kterých jsem psal celou dobu výše, spočítají v tom, že se koukne do tohoto pole, jestli tam je nula - a to je samozřejmě velmi rychlá operace. A v tomto reportu když jsme crashli nám asan ukazuje, že jsme si sáhli na adresu, které v poli odpovídá FA.
Z uvedeného popisu je vidět, že to krásně odchytí přístupy pár bajtů mimo, ale pokud máte dva objekty za sebou a z toho prvního uděláte přístup o hodně dopředu tak, že se trefíte do toho druhého, tak to to neodchytí. Pravděpodobnost, že se tohle stane, to snižuje tím, že to mezi objekty vkládá padding, aby nebyly blízko za sebou.
Další tipy k používání sanitizeru:
ASAN_OPTIONS=detect_leaks=0, protože v mých programech, jak jsem popsal ve starším článku, memory leaky nehrozí (nepoužívám alokaci za běhu v C), a občas to reportuje falešné memory leaky z používaných knihoven a Pythonu (mohlo by to souviset s tím, že Python má taky vlastní alokátor).-fsanitize=address existuje -fsanitize=undefined (detekuje undefined behavior), -fsanitize=memory (čtení neinicializované paměti, asi nefunguje s gcc ale jenom s clangem) a -fsanitize=thread, což je velmi zajímavý nástroj, který sleduje přístup ke sdíleným proměnným u jednotlivých vláken, a pokud dvě vlákna přistupovala ke stejnému prostředku aniž by mezitím došlo mezi nimi k použití mutexu, tak vyhlásí chybu.Další užitečný nástroj je perf. Řekne nám, kde se v našem programu tráví nejvíce času. Funguje to tak, že to spustí program, nechá ho chvilku běžet, pak ho zastaví a podívá se, jaká instrukce se právě vykonává. Tohle udělá mnohokrát a pak se vypíše statistika, kde se program nacházel nejčastěji a tedy tyto kousky asi trvají nejdéle. Procesory naštěstí obsahují hardwarovou podporu pro performance counters, takže se to přerušování programu nedělá takhle nevhodně softwarově, ale procesor přímo někam ukládá tuto diagnostiku. Kromě základního „kde se program jak často nacházel“ různé procesory podporují i jiné statistiky (zadejte "perf list", vypíše schopnosti vašeho procesoru), například „kde docházelo k cache missům L1 cache“. Na některých low-endových procesorech se tomu musí občas trochu pomoct.
Je potřeba mít program zkompilovaný s debug symboly (gcc ... -g). Pak pustíme perf record náš_program. Pokud to běží dlouho, můžeme to po chvíli killnout Ctrl+C, pro základní statistiku stačí třeba sekunda běhu. Toto vyrobí soubor perf.data. Obsah souboru zobrazíme pomocí perf report. Zobrazí se textové rozhraní, kde můžeme kód procházet, a zobrazuje se disassembly proložené zdrojákem a procenta kolik času se kde trávilo.
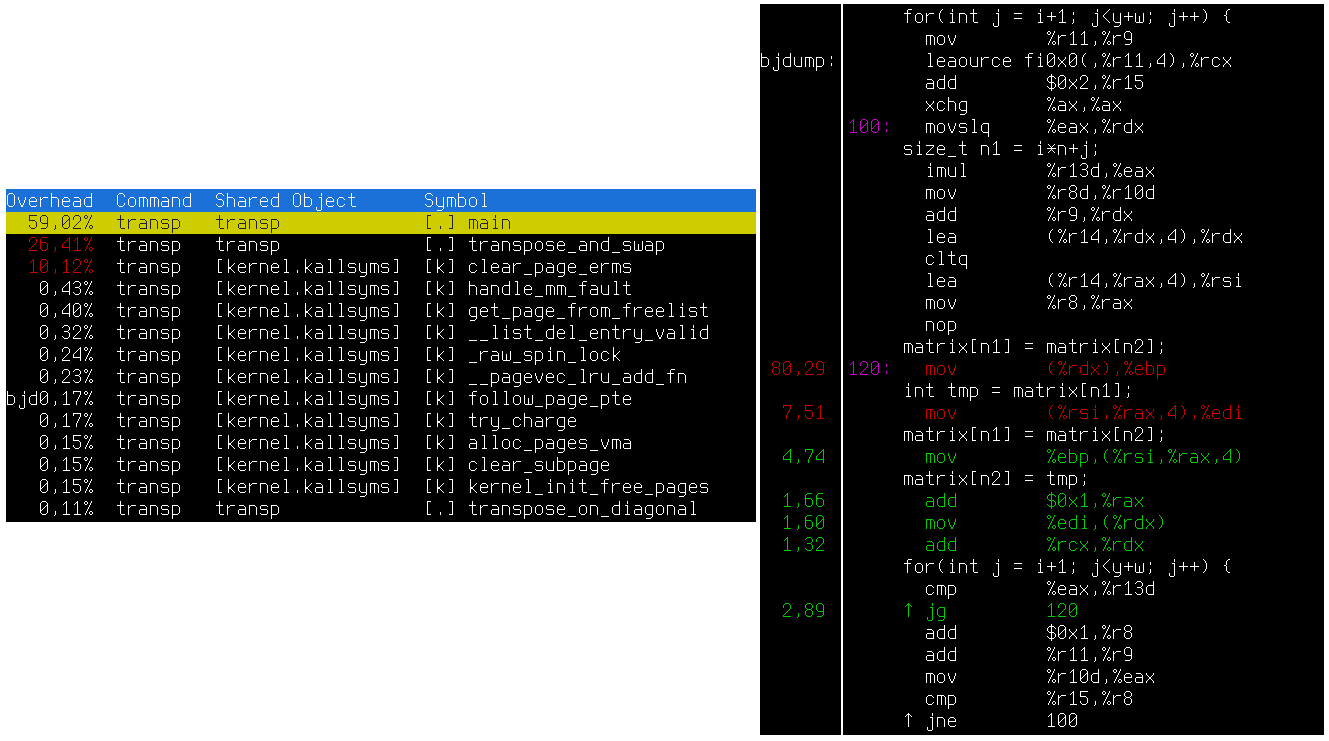
Udávané hotspoty můžou být o pár instrukcí špatně - z důvodu vykonávání více instrukcí současně a out-of-order execution v současných procesorech se může stát, že náročná instrukce je někde předtím a perf zobrazí až čekání na její výsledek. To stejné s čekáním na přístup do paměti.
Pokud budete profilovat program, který tráví většinu času v cizích knihovnách (v mém případě je teď například populární FFTW), tak pokud nemáte ke knihovnám nainstalované debug symboly, tak perf zobrazí jenom náhodné adresy. Například na Debianu je potřeba doinstalovat dbgsym balíčky ze speciálního repozitáře.
Postupně jsem dokonvergoval k následujícím flagům gcc, které považuji za užitečné. Jsou to rozšířená varování a nějaké drobnosti. Najděte si v dokumentaci (dokumentace varování) co dělají, já už si to taky nepamatuju.
-fno-common -fno-omit-frame-pointer -std=gnu11 -Wall -Wextra -Wduplicated-cond -Wduplicated-branches -Wlogical-op -Wrestrict -Wnull-dereference -Wjump-misses-init -Wdouble-promotion -Wshadow -Wformat=2 -pedantic
Tady je zajímavý příklad nečekané díry způsobené race condition.
Tady je krásný writeup o hledání občasného náhodného pádu Go.
Tady je ukázka, že podmínku zarovnaného přístupu není možné v C ignorovat ani na architekturách, kde to procesor hardwarově ošetří (byť za cenu zpomalení), protože se to stejně náhodně vysype.
Výše jsme řešili, že nejde automaticky předělávat kód protože se (minimálně na x86) může skákat náhodně někam doprostřed a instrukce jsou různě dlouhé a nezačínají zarovnaně. Native Client je omezení na jumpy zarovnané na 32 bajtů, díky čemuž se pak kód dá automaticky skenovat na přítomnost zakázaných instrukcí. Používalo se to pro spouštění nativního kódu v javascriptových browserových aplikacích než přišel WebAssembly.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 4.9.2021 17:57
Člověk z Horní Dolní
| blog: blbeczhornidolni
4.9.2021 17:57
Člověk z Horní Dolní
| blog: blbeczhornidolni
Měli byste tedy jakoby se sanitizérem překompilovat celý runtime.Ha, teď jsi se prozradil, už vím kdo je Gréta.
 4.9.2021 18:05
Jendа | skóre: 78
| blog: Jenda
| JO70FB
4.9.2021 19:06
Člověk z Horní Dolní
| blog: blbeczhornidolni
4.9.2021 18:05
Jendа | skóre: 78
| blog: Jenda
| JO70FB
4.9.2021 19:06
Člověk z Horní Dolní
| blog: blbeczhornidolni
 6.9.2021 12:27
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
6.9.2021 12:27
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
jestli jako myslíš že tvuj vodhad je jakoby víc lepšejší než bystroušákovy statistický analízy komentů :D
6.9.2021 21:55
Člověk z Horní Dolní
| blog: blbeczhornidolni
 7.9.2021 17:53
xxxs | skóre: 25
| blog: vetvicky
8.9.2021 23:21
Člověk z Horní Dolní
| blog: blbeczhornidolni
10.9.2021 12:17
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
7.9.2021 17:53
xxxs | skóre: 25
| blog: vetvicky
8.9.2021 23:21
Člověk z Horní Dolní
| blog: blbeczhornidolni
10.9.2021 12:17
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
si myslim že to nemá smysl to s nim dál řešit protože už je jakoby rozhodnutej čemu chce věřit :D ho ale teda jako dorazim když mě takle provokuješ :D :D ;D ;D
 Q.E.D.
10.9.2021 12:19
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
Q.E.D.
10.9.2021 12:19
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
A zejména - koho než frantíka zajímají ty jeho podělaný relační roury
ttttsssss radar mě zajímá uplně stejně hele :O :O :D :D :D :D ;D ;D
-Wall -Wextra -Wshadow -fstack-protector-strong a na sanitizaciu -fsanitize=address -fsanitize=undefined -fsanitize=leak -fno-omit-frame-pointer. Tie niektore dalsie warningove parametre vyzeraju uzitocne.
Osobně jsem ale tohle nikdy nepotřeboval řešit, defaultní malloc byl vždycky good enough. Setkali jste se někdy s případem, kdy by bylo potřeba alokátor ladit?Presne kvuli zpomaleni kvuli (kontrolam na) race condition jsme museli naalokovat velkou pamet pro kazdy thread separatne a implementovat v asm vlastni alokator nad timhle vyhrazenym adresnim prostorem.
 5.9.2021 00:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
5.9.2021 00:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Tady je krásný writeup o hledání občasného náhodného pádu Go.Skvělý článek, díky. Trochu mi to (v malém) připomíná moje začátky s golangem, kdy jsem skoro hned narazil na chybu při procházení adresářů na sambě, kdy to vracelo různý počet nalezených souborů při každém dalším volání. Golang všechny relevantní syscally posílá s SA_RESTART a nikdy by se neměl vracet EINTR. Jenže se vrací. Ovladač pro sambu prostě ignoruje SA_RESTART a nechá to udělat klienta (potom se zjistilo, že je to ještě navíc ovlivněno velikostí bufferu) a nakonec vydali nové verze knihovních funkcí, ale toto řešení se mi nelíbí, protože to zakrývá původní a stále existujicí chybu v sambě. (Nehledě na to, že workaround je poměrně snadný a podle mě je mnohem lepší v kódu když už tak použít workaround na místo knihovní funkce, která zakrývá nějaký problém na systémové vrstvě. -- Potom se každý drží knihovní funkce a nechce nic slyšet o tom, že pod tím je to ale stále špatně, takže je lepší toto místo explicitně označit.) Sice na kritických místech používám NFS, kde se to neděje, ale i tak mě překvapuje, že takto často používaný způsob sdílení má tyto problémy.
5.9.2021 00:19
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Například se mi zdá, že si každý druhý píše vlastní alokátorJo, bavil jsem se s člověkem, který si běžně píše (C++) několik vlastních alokátorů v jednom programu pro různé účely, protože jinak to nejde a ten single thread program by jinak nezvládal zátěž (což je možná pravda, ale současně to extrémně zkomplikuje přepis na multithread nebo jiné rozsekání).
6.9.2021 22:35
Člověk z Horní Dolní
| blog: blbeczhornidolni
a pokud vlákna hodně alokují, tak je toto bottleneck. Alokátor tohle detekuje a rozdělí haldu na více částí, pro každé vlákno samostatně. Osobně jsem ale tohle nikdy nepotřeboval řešit, defaultní malloc byl vždycky good enough. Setkali jste se někdy s případem, kdy by bylo potřeba alokátor ladit?Kdysi dávno, tak před 15ti lety. Defakto webserver v C++, samozřejmě spousta requestů se zpracovávala paralelně a v té chvíli byl i na tehdy snad jenom čtyřjádru existující glibc malloc šílený bottleneck. Takže v té době jsem si i já napsal vlastní alokátor, kromě per-thread cache a rozdělení podle podobné velikosti bloků uměl i některé debug features popsané v článku, včetně detekce memory leaks, myslím, že i inaccessible stránky na začátku či na konci apod. Později s běžně dostupnými multicore procesory a multithreading se začaly používat podobné alokátory přes LD_PRELOAD a mám pocit, že i glibc má dnes něco podobného (nebo dokonce přímo převzali jemalloc?)...
Tady je ukázka, že podmínku zarovnaného přístupu není možné v C ignorovat ani na architekturách, kde to procesor hardwarově ošetří (byť za cenu zpomalení), protože se to stejně náhodně vysype.Na tohle jsem taky narazil, když jsem experimentoval s AVX-512. Alignment __mm512 sice funguje v rámci struktury, ale stack je zarovnaný jenom 16-bytes. Takže SSE v pohodě jede (__mm128), ale AVX-2 a AVX-512 může mít základní adresu struktury nezarovnanou a tedy i prvky uvnitř. Nejsem si jistý, jak to má malloc bez options, myslím, že taky musí vracet 16-byte, ale jestli i výš, nevím. Jinak, procesor x86_64 to právě hardwarově neošetří - na load/store se můžou použít instrukce, které vyžadují alignment (MOVAPD apod), pokud to kompilátor (mylně, viz výše) ví a to potom vede k pádům. Měly být původně rychlejší, ale myslím, že dneska je to skoro jedno... Kromě toho bych řekl, že instrukce na unaligned load/store nebudou atomické (ne ve smyslu compare-and-swap, ale v jednoduchém smyslu konzistence, že se přepíše či nahraje celá hodnota najednou bez přerušení jiným CPU).
 5.9.2021 16:11
xkucf03 | skóre: 50
| blog: xkucf03
5.9.2021 16:11
xkucf03 | skóre: 50
| blog: xkucf03
Typicky priklad jsou gcExistuje něco jiného než Boehm? Myslím veřejně dostupné.
5.9.2021 09:23
xkucf03 | skóre: 50
| blog: xkucf03
Pěkný článek, díky.
Nejvíc používám ASan. Bez něj by programování v C/C++ byla procházka minovým polem. S ním je to relativně v pohodě a řeší velkou část nebezpečnosti těchto jazyků.
Ještě bych doporučil použití fuzzeru, který taky může odhalit nějaké ty chyby – krmí program náhodnými/chybnými daty a zjišťuje, zda program spadne, zacyklí se atd. Může odhalit např. chybu typu, že ve vstupních datech je uvedena délka následujícího pole (TLV), parser si pro tuto délku alokuje paměť, aniž by předem ověřil, že tolik dat na vstupu vůbec je (tzn. chybnými vstupními daty lze program donutit, aby si alokoval zbytečně gigabajty paměti a nebo spadl). Ale zrovna tohle je chyba, které jsem si byl vědom a fuzzerem jsem si ji jen potvrdil.
například přetečení intu, ale to lidi často řeší kompilací s -fwrapvPěkné, využil jsem. Ušetřilo mi to v programu asi tak 4 instrukce.
 5.9.2021 14:15
xkucf03 | skóre: 50
| blog: xkucf03
5.9.2021 14:15
xkucf03 | skóre: 50
| blog: xkucf03
Nestačilo by ten kritický kód napsat jako knihovnu, kterou by šlo přeložit jak pro MCU, tak pro x86? (jasně, tam, kde pracuji s I/O to bude vázané na to MCU a musel bych si to nějak mockovat/simulovat, ale svoje vlastní algoritmy můžu klidně napsat jako .h soubor, který bude použitelný jako uvnitř firmwaru tak na desktopu).
Nezarovnaný přístup - problémy i na x86 Tady je ukázka, že podmínku zarovnaného přístupu není možné v C ignorovat ani na architekturách, kde to procesor hardwarově ošetří (byť za cenu zpomalení), protože se to stejně náhodně vysype.Někdy ale zarovnaný přístup nechceme, protože nezarovnaný bývá více než 2x rychlejší.
6.9.2021 00:27
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.9.2021 12:23
MakeIranBombedAgain❗ | skóre: 42
| blog: Grétin blogísek
| 🇮🇱==❤️ , 🇵🇸==💩 , 🇪🇺==☭
supr satanizér :D ;D
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz