pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na Seznam nepovolených internetových her (Wikipedie) se k 13. 7. 2026 dostala predikční platforma Polymarket.
Nová čísla časopisů od nakladatelství Raspberry Pi zdarma ke čtení: Raspberry Pi Official Magazine 167 (pdf) a Hello World 30 (pdf).
Byla vydána nová verze 3.22.0 grafického vývojového prostředí a platformy Gambas (Wikipedie) založené na interpretru programovacího jazyka Basic s rozšířením o objektově orientované programování. Přehled novinek v poznámkách k vydání. Zdrojové kódy jsou k dispozici na GitLabu.
FreeBSD odstranilo poslední GPL kód ze základního systému. Konkrétně dpv, libdpv, libfigpar a dialog. Instalátor před čtyřmi lety přešel z dialogu na bsddialog.
Sociální síti 𝕏 (dříve Twitter) má dnes 20 let. Pro veřejnost byla zpřístupněna 15. července 2006.
printf sloužící k formátování a výpisu textu, dále wc, který umí spočítat počet řádků, slov, znaků či bajtů v textu, potom nl, který umí očíslovat řádky, a nakonec tee, který umí výstup jiného programu ukládat do souboru a zároveň vypisovat na standardní výstup.Příkaz printf je podobný stejnojmenné standardní funkci jazyka C a slouží k formátování a výpisu textu. Název je zkratka anglického výrazu print formatted, tedy tisknout formátovaně.
Lze ho používat jako alternativu dříve zmiňovaného příkazu echo, ovšem zde se sluší zmínit diskuzní vlákno, které pod článkem vzniklo, a také citovat SUS standard, ze kterého pro tento článek čerpám. Přímo standard doporučuje se používání echo vyhnout a v nových skriptech používat printf, protože je přenositelnější (a lze pomocí něj snadněji vypsat „-n“ :-)).
Jak se printf používá? Stejně jako v C, ovšem s tím rozdílem, že Bash nerozlišuje datové typy, takže i čísla lze vypsat jako řetězce.
$ printf "Váš domovský adresář je %s\n" $HOME Váš domovský adresář je /home/dave $ printf "%f %f %.1f\n" 123 124,45 12 123,000000 124,450000 12,0
Nerad bych diskriminoval uživatele C netknuté, proto použití trochu rozeberu: Jako první argument se zadává řetězec s formátováním, obsahující fixní řetězce (např. „ahoj“), escapovací sekvence (např. „\n“ pro nový řádek, „\\“ pro zpětné lomítko či „\t“ pro horizontální odsazení – tab), a také řetězce, které budou nahrazeny za proměnné („%s“ za řetězec, „%d“ za celé číslo, „%f“ za desetinné číslo, „%c“ za 1 znak, atp.). Další argumenty jsou řetězce, které budou dosazeny za proměnné umístěné v prvním argumentu.
$ printf "První řetězec: %s, druhý řetězec: %s, atd.\n" str1 str2 První řetězec: str1, druhý řetězec: str2, atd. $ n=42,12 $ printf "Formátujeme číslo:\n\tCelé číslo: %.0f\n\t3 desetinná místa: %.3f\n" $n $n
Dávejte si pozor na oddělovač desetinného místa. Pokud váš systém používá českou locale (snadno zjistíte příkazem locale), potom je oddělovač čárka, zatímco ve výchozím locale („C“) je to tečka a v jiných to může být zase jiný znak, takže na to nespoléhejte. A chcete-li napsat znak „%“ tak, jak je, pište „%%“.
$ printf "%%c vypíše pouze 1 znak ze zadaného řetězce: %c%c%c%c%c\n" z n "" a ky %c vypíše pouze 1 znak ze zadaného řetězce: znak
Program wc slouží ke zjištění počtu řádků, slov, znaků či bajtů v daném textu. Název je zkratkou word count, česky počet slov.
Text lze programu zadat na standardní vstup
# vypíše počet řádků, které by příkaz „ps ax“ jinak vypsal na výstup $ ps ax | wc -l 195 # vypíše počet bajtů textu v /proc/cpuinfo $ wc -c < /proc/cpuinfo 3240
nebo je možné dodat názvy souborů, které se mají analyzovat. Použijete-li wc takto, vypíše za požadovaná čísla ještě název souboru.
# vypíše počet řádků, slov a bajtů textu v daném souboru $ wc qconf.patch 46 115 921 qconf.patch
Z komentářů u jednotlivých ukázek je zřejmé, že wc bez argumentů vypíše počet řádků, slov a bajtů (v tomto pořadí) a že lze zajistit i výpis jen požadovaných počtů: Přepínač -l (v GNU též --lines) zajistí výpis počtu řádků, -w (v GNU i --words) počet slov, -c (v GNU také --bytes) počet bajtů a ještě jsem nezmínil přepínač -m (v GNU i --chars), který slouží pro výpis počtu znaků.
Program nl slouží k očíslování řádků. Název je zkratkou number lines, česky očísluj řádky.
Základní použití je zjevné:
$ printf "raz\ndva\ntři\n" > txt
$ nl txt
1 raz
2 dva
3 tři
Stejného efektu lze docílit pomocí cat -n:
$ cat -n txt
S využitím přepínačů lze ovšem docílit i komplexnějšího číslování. Přepínačem -v lze určit, jakým číslem číslování začne (výchozí je 1, programátoři si mohou nastavit 0). Přepínačem -i lze ovlivnit, o kolik bude číslo růst s každým novým řádkem (výchozí hodnota je 1).
$ nl -v 0 -i 2 txt
0 raz
2 dva
4 tři
Pomocí přepínače -b lze určit, které řádky budou číslovány. S argumentem „a“ budou očíslovány všechny řádky, s „t“ pouze neprázdné řádky, s „n“ žádné řádky a s „pregex“ budou očíslovány pouze řádky odpovídající základnímu regulárnímu výrazu regex:
# očísluje pouze řádky, které začínají řetězcem „int“ grep "int" zdrojak.C | nl -b p^int
Přepínač -w umožňuje zadat počet znaků použitých pro číslo řádku. Výchozí počet je 6. Přepínač -s umožňuje změnit oddělovač čísla řádku od samotného textového obsahu řádku. Výchozí oddělovač je tab.
$ nl -w 2 -s ": " txt 1: raz 2: dva 3: tři
tee je program, který umí data, jež jsou mu předána na standardní vstup, ukládat do souboru a zároveň je vypisovat na standardní výstup. Název vychází z toho, jak angličané vyslovují samotné písmeno „T“.
Dovolil jsem si pro ilustraci vypůjčit (GPL) obrázek z wikipedie a lokalizovat jej, protože velmi pěkně vystihuje to, co tee dělá (a proč se tak jmenuje):
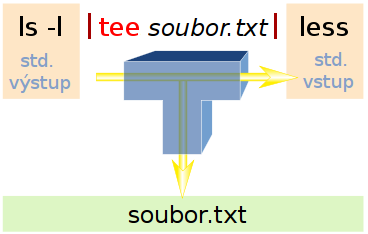
Představte si, že chcete spustit upovídaný program a přejete si jeho std. výstup ukládat do souboru, a zároveň si jej číst, hned jak je vypisován.
# takto docílíte pouze první část požadavku (std. výstup je ukládán do souboru) # na výstupu uvidíte jen stderr, čili std. chybový výstup $ ls -l /usr/bin > soubor.txt # řešení pomocí tee $ ls -l /usr/bin | tee soubor.txt
Je důležité si uvědomit, že když tee umístíte za rouru, jako jsem to udělal v předchozí ukázce, tak se na std. vstup dostane pouze to, co program před rourou vypisoval na std. výstup, ale už ne to, co vypisoval na chybový výstup (stderr). Pokud chcete ukládat obojí (a mít tak v souboru uložený kompletní výstup programu tak, jak jej vidíte na terminálu), potom je třeba provést patřičné přesměrování výstupu programu.
$ make 2>&1 | tee kompletni_vystup.txt ../dalsi_kopie_vystupu.txt
Nakonec zmíním ještě dostupné přepínače. Přepínač -a (v GNU též --append) zajistí, aby se daný soubor, pokud již existuje, nepřepsal, ale aby se místo toho výstup připojil na jeho konec. Přepínač -i (v GNU též --ignore-interrupts) zajistí ignorování signálu SIGINT, který se příkazu pošle například stisknete-li Ctrl+C při jeho provádění.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 11.8.2010 08:22
tsLnox | skóre: 31
| blog: Blog jednoho ukecaného Gentoolemana
| Žďár nad Sázavou
11.8.2010 08:22
tsLnox | skóre: 31
| blog: Blog jednoho ukecaného Gentoolemana
| Žďár nad Sázavou
 11.8.2010 10:35
David Watzke | skóre: 74
| blog: Blog...
| Praha
11.8.2010 10:35
David Watzke | skóre: 74
| blog: Blog...
| Praha
The tee utility shall not buffer output.
Docela mne deprimuje, proč bych měl zcela základní funkcionalitu shellu nahrazovat perlem.Protože shell má jen omezené možnosti využití. Od jisté hranice je lepší použít nějaký silnější nástroj. Tvorba pseudo terminálu je patrně za touto hranicí.
Perl neumím a co teď?Zkuste se to naučit, třeba se Vám zalíbí.
Mám se ptát v poradně abclinuxu?Určitě.
Jinak dotazů na tenhle problém jsem na googlu našel dva tisíce.Pak je to asi častý problém. Čím častější, tím déle se řeší :)
Nechápu, proč si člověk nemůže nastavit buffering mode (block, line, unbuffered) přímo v bashi.Protože to nemá nic společného s bashem, ale se způsobem jak funguje OS. BTW, podle toho komentáře níže byste možná mohl uspět také s tím příkazem stdbuf.
11.8.2010 22:52
David Watzke | skóre: 74
| blog: Blog...
| Praha

Protože si myslí, že tee místo fwrite(3) použije write(2), který žádný buffer sám o sobě nezavádí. To ovšem vůbec nemusí být pravda, klidně může použít fwrite(3), ale bufferování musí podle POSIXu vypnout.
Takže bych se osobně přikláněl k verzi, že konkrétní implementace tee byla prostě rozbitá. Jestli na stdout zapisuje tee nebo jiný proces, je totiž z hlediska terminálu jedno.
$ printf "Hello world!" bash: !": event not found $ printf 'Hello world!' Hello world!Jakym zpusobem ale vyresit nasledujici? Expanze promenych vs. specialni znaky, tzn. chci zobrazit hodnotu prom. HOME ale nechci aby mi bash hlasil chybu 'event not found'.
$ printf "$HOME !" bash: !": event not found vs. $ printf '$HOME !' $HOME !Asi takhle:
$ printf '%s !' $HOMENebude teda lepsi davat formatovaci retezec do jednoduchych uvozovek (v pripade BASHe)?
Raději:$ printf '%s !' $HOME
$ printf '%s !' "$HOME"
Nebude teda lepsi davat formatovaci retezec do jednoduchych uvozovek (v pripade BASHe)?Určitě. Bonusová otázka: co je špatně u následujícího?
$ printf "$HOME"'!'
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz A kolega se diví, co že je na tý práci tak vtipnýho
A kolega se diví, co že je na tý práci tak vtipnýho