HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Na úvod si řekněme pár slov k historii předcházející architektuře Fermi. Až do roku 2006 měla GPU oddělené pixel a vertex shadery a celkově tak byla velmi neefektivní ve svém konání, bez ohledu na prakticky mizivou (víceméně nulovou) možnost jakýchkoli obecných výpočtů. Změnu přineslo GPU NVIDIA G80 alias GeForce 8800 GTX, která přinesla unifikované shadery a první verzi programovací částí známé jako CUDA (Compute Unified Device Architecture). NVIDIA své rozhraní postupně inovovala, aktuálně jsme na verzi 2.3. Později přišlo též architektonicky inovované GPU GT200 známé z GeForce GTX 280 a jejích kolegyň. Třetím krokem v této řadě směřujícím k téměř finální unifikaci je NVIDIA Fermi.
Fermi není primárně vyvinuto jako grafický procesor pro hraní her. Samozřejmě toto podporuje, ale tím nejdůležitějším pro něj jsou výpočty. Za tímto účelem přináší řadu vylepšení, z nichž se sluší jmenovat implementaci ECC u pamětí, vyrovnávací paměti L1 a L2, zvětšení sdílené paměti, rychlejší přepínání obsahu mezi grafikou a výpočty a rychlejší atomické operace.
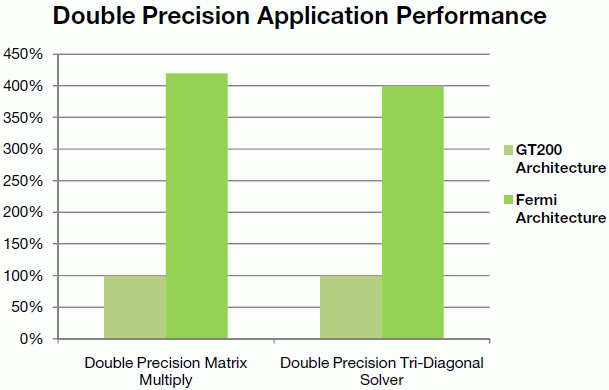
Na svět se tak pomalu blíží třetí generace Streaming Multiprocessoru NVIDIA, kde každý ve Fermi nese 32 CUDA jader (4× více než GT200). Výpočetní jednotky Fermi poskytují 8× tolik výkonu v double-precision než GT200, dual war scheduler umí obsluhovat 32 threadů/takt a celkově 64kB paměť je konfigurovatelná jako sdílená paměť a L1 cache, dle přání programátora (buď jako 16+48 kB, nebo jako 48+16 kB).
Druhá generace Parallel Thread Execution ISA nese další hlavní inovaci, a sice unifikovaný adresní prostor s plnou podporou jazyka C++ a s tím související optimalizace pro OpenCL a DirectCompute a plnou podporu IEEE 754-2008 v 32 (single) i 64bit (double) přesnosti (totéž umí ATI Radeon HD 58x0). NVIDIA zapracovala i na predikci v rámci čipu, která též zrychluje. Paměťový subsystém schovává pod označením Parallel DataCache konfigurovatelnou L1 a unifikovanou L2 cache, všechny paměti mají podporu ECC a zlepšený výkon v atomických operacích.
Nová generace GigaThread Engine slibuje 10× rychlejší přepínání aplikačního obsahu, souběžné spouštění kernelů, out of order spouštění bloků výpočetních a dualitu překrývajících se engine paměťových přenosů.
To hlavní z hlediska programátora úvodem: Připomenu, že CUDA jako architektura umí spouštět na GPU programy psané v C, C++, OpenCL, DirectCompute nebo třeba také ve Fortranu. Hlavní program volá kernely, které jsou vykonávány paralelně. Míru paralelismu může programátor řešit ručně v kódu, nebo to nechá na systému. Thready jsou organizovány do bloků a ty pak do větších celků.
Daný blok je vždy sekvencí několika současně vykonávaných threadů, které mohou spolupracovat přes synchronizační bariéru a sdílenou paměť. Fermi uřídí v jeden okamžik až 1 536 souběžně běžících threadů, opět významný nárůst proti předchozí generaci.
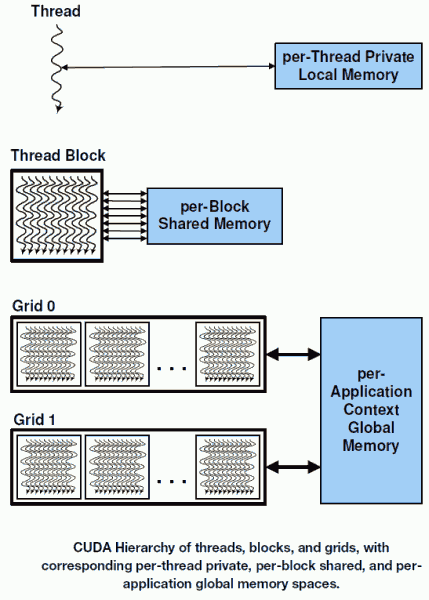
Jak již jsme si řekli, Streaming multiprocessor nese 32 CUDA jader, tudíž vykonává thready ve skupinách po 32. Takováto skupina se nazývá warp. Je na programátorovi, zdali se bude držet při programování jednoho threadu, nebo využije možné paralelizace v rámci CUDA.
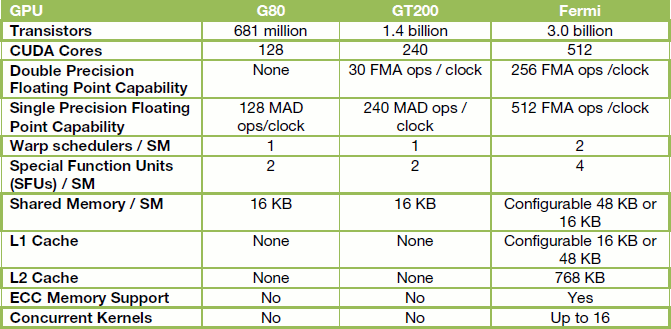
Zatímco GPU Radoenu HD 5870 by se svými 2,15 miliardami tranzistorů a 40nm výrobou mohlo komukoli připadat jako bomba (a nebudu to ani na chvíli popírat), NVIDIA jde s Fermi ještě dále. GPU nese při stejné 40nm výrobě rovné 3 miliardy tranzistorů a to byl (stále je?) patrně také dílčí kámen úrazu v podobě komplikací s výtěžností jeho výroby.
Jader CUDA, volně a archaicky řečeno „shaderů“, obsahuje Fermi rovnou 512, což představuje nárůst o 113 % oproti 240 v GT200. Jsou organizována v 16 streaming multiprocesorech po zmíněných 32. GPU má k dispozici šest 64bitových paměťových částí, celkově tedy 384bitové paměťové rozhraní, které může využívat až 6 GB pamětí GDDR5. To předpokládejme jako hodnotu pro výpočetní karty rodiny Tesla, které se objeví jako první. Základem bude na desktopových kartách GeForce dle mého 1,5 GB, vyšší modely a karty Quadro přinesou i 3GB variantu.
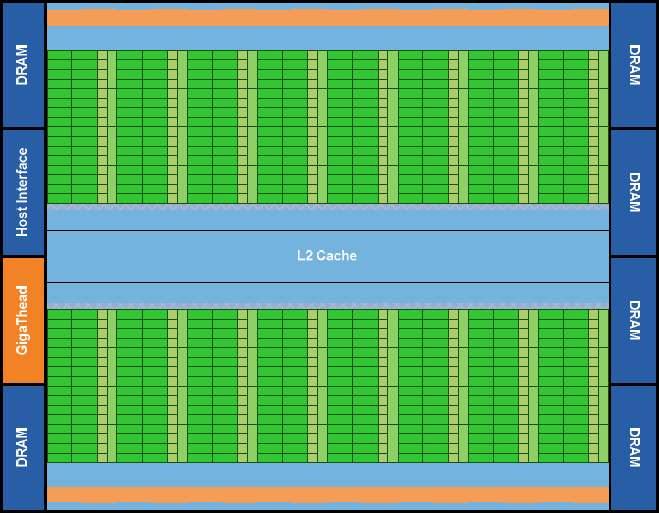
Komunikace čipu se systémem probíhá pochopitelně po sběrnici PCI Express. Modrá část schématu vlevo obsahuje GigaThread Scheduler, rozhraní PCI Express a část paměťového systému, pravá zbytek paměťového subsystému. Zelené bloky jsou výpočetní části, k nim přísluší jim společná L2 cache.
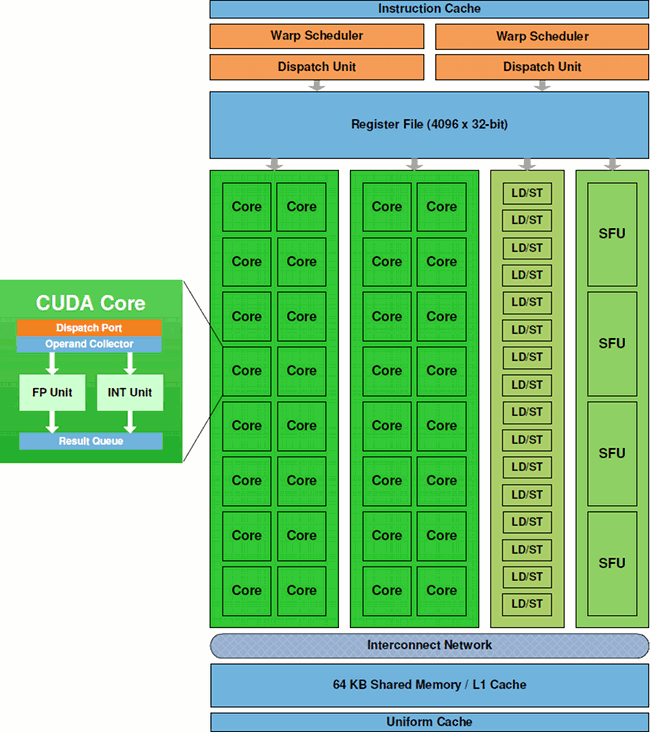
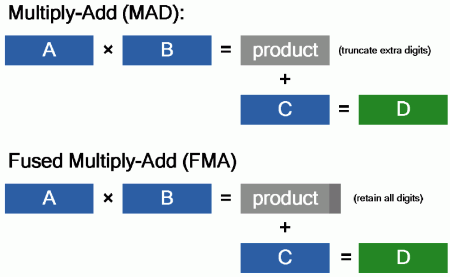
Každé CUDA jádro obsahuje jednu Integer ALU – Arithmetic Logic Unit – a jednu FPU. Plná podpora IEEE 754-2008 je novinkou této generace, stejně jako instrukce fused multiply-add (FMA) pro single i double-precision. FMA realizuje multiply-add beze ztráty přesnosti výpočtu při sčítání.
Nová Integer ALU nese optimalizace pro 64bit a extended přesnost a podporuje aritmetické, posuvné, logické, porovnávací, převodní a přesouvací operace. Každý Streaming Multiprocessor (SM) blok nese 16 load/store jednotek pro výpočty 16 zdrojových a cílových adres pro výpočetní vlákna v jediném taktu. Příslušná data se načítají/uchovávají v cache nebo DRAM.
Special Function Units (SFU) jsou celkem čtyři pro každý SM a realizují transcendentní funkce (sin, cos, reciproční a kvadratické). Každá SFU zvládne jednu instrukci pro dané výpočetní vlákno za takt; celý warp je spouštěn každých osm taktů. SFU pipeline je oddělena od dispatch jednotky, což umožňuje této jednotce využívat další výpočetní jednotky zatímco SFU pracuje na něčem jiném.
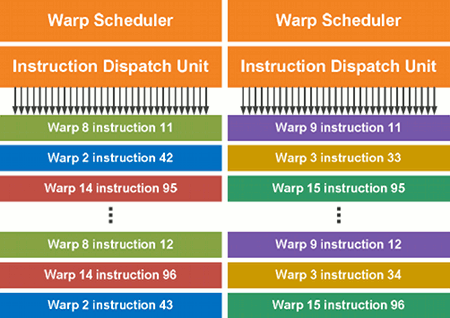
SM ve Fermi obsahuje Dual Warp Scheduler a dvě instruction dispatch unit, což umožňuje zpracovávat dva warpy najednou. DWS vždy vezme dva warpy, jednu instrukci z každého z nich a přiřadí je skupině šestnácti CUDA jader, šestnácti load/store jednotkám nebo čtyřem SFU. Warpy jsou vždy vykonávány okamžitě, což umožňuje dosahovat téměř maximální dosažitelný výkon. Většina instrukcí může být realizována touto duální cestou: Dvě integer instrukce, nebo dvě floating instrukce, nebo mix integer a floating, načítání, uchovávání a SFU instrukce; vše může být zpracováváno současně.
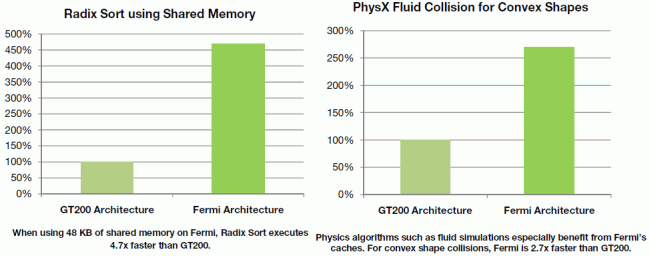
S nově konfigurovatelnou L1 cache resp. sdílenou pamětí může být Fermi až třikrát rychlejší na stejném kódu než předchozí generace. Pokud programátor do aplikace nezabudoval využití sdílené paměti, bude tato nyní automaticky těžit z L1 cache.
Fermi jako první u NVIDIE podporuje Parallel Thread eXecution (PTX) 2.0, což je nízkoúrovňová virtuální mašina a ISA (Instruction Set Architecture) navržená pro paralelní operace. PTX instrukce programů jsou ovladačem GPU překládány na strojové instrukce. PTX jako celek má za úkol nabídnout ISA přeživší několik generací GPU, zajistit maximální využití výkonu GPU, nezávislé ISA pro C, C++, Fortran a další jazyky, code distribution ISA pro vývojáře aplikací a middlewaru, společné ISA pro generátory a překladače kódu, usnadnit psaní knihoven a výkonných kernelů a nabídnout škálovaný programovací model, který se přizpůsobí velikosti GPU od několika jader až po mnoho paralelních jader. PTX 2.0 bylo primárně navrženo vedle jazyků jako OpenCL a DirectCompute pro programovací jazyk C++ a jeho plnou podporu.
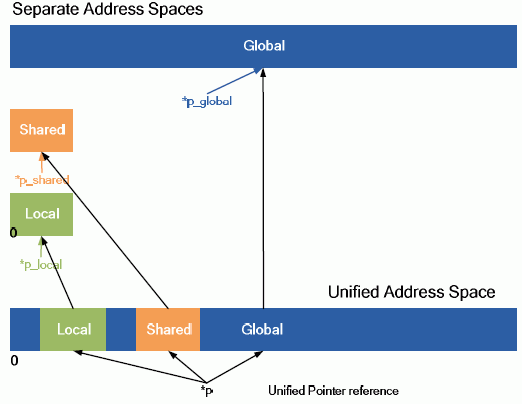
S tím souvisí jednotný adresní prostor (pro C++), který sjednocuje tři dosud oddělené adresní prostory (threadový lokální privátní, blokový sdílený a globální) pro načítání a uchovávání operací. Dosud bylo obtížné až nemožné implementovat C a C++ ukazatele, neboť cíle ukazatelů v adresním prostoru nemusely být v momentě kompilace známy a bylo možné je určovat pouze dynamicky za běhu.
Na architektuře Fermi definovaný 40bitový adresní prostor podporuje až 1 TB adresovatelné paměti, ISA pro načítání a ukládání podporuje až 64bitové adresování pro budoucí růst parametrů.
Nechybí ani podpora virtuálních funkcí, ukazatelů na funkci a operátorů „new“ a „delete“ pro dynamickou alokaci objektů a dealokaci. Též jsou podporovány operace pro výjimky „try“ a „catch“.
Oba nové GPGPU standardy jsou původní implementaci v CUDA velmi podobné, takže s nimi nebude nejmenší problém. Fermi disponuje i hardwarovou podporou pro OpenCL a DirectCompute surface instrukce s konverzí formátu, což umožňuje grafickým a výpočetním programům jednoduše pracovat s těmi samými daty. PTX 2.0 ISA přidává i další DirectCompute instrukce jako population count, append a bit-reverse.
Instrukce single-precision floating point nově podporují subnormální čísla a také zaokrouhlovací módy IEEE 754-2008 (nearest, zero, positive infinity a negative infinity). GT200 a dřívější takové subnormální hodnoty vypouštěly a dávaly hodnoty jako nula, což vedlo ke ztrátě přesnosti výpočtů.
NVIDIA si v minulosti na mnoha GPGPU aplikacích ověřila, že někde je vhodné použít sdílenou paměť, jinde zase cache. Proto je implementován systém konfigurovatelné 64kB paměti, jak jsem uvedl výše.
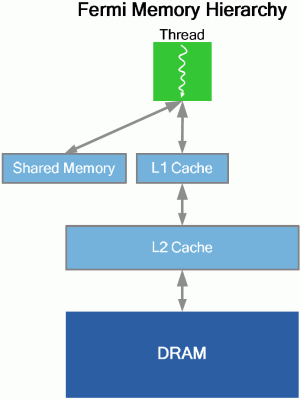
Vedle toho Fermi obsahuje sdílenou 768kB L2 cache, ta obstarává požadavky pro načítání, ukládání a texturování.

Atomické paměťové operace jako add, min, max a compare-and-swap jsou atomickými v tom smyslu, že čtení/modifikace/zápis jsou prováděny bez přerušení jinými thready. Jsou využívány pro třídění, redukční operace, paralelní budování datových struktur atd. Kombinací několika atomických jednotek v hardwaru a přidání L2 cache je vykonávání těchto operací na Fermi výrazně rychlejší. Atomické operace vůči dané adrese vykonává Fermi až 20× rychleji než GT200, operace do kontinuálních paměťových oblastí až 7,5× rychleji.
Pipeline ve Fermi nese optimalizace za účelem co nejrychlejšího přepínání výpočtů tak, aby docházelo k co nejmenším ztrátám. Přepnutí obsahu se podařilo srazit na interval 10 až 20µs, díky čemuž mohou programátoři využívat ve větší míře jen s minimální ztrátou výkonu GPU interkernelovou komunikaci jako třeba kooperaci mezi grafickou a PhysX částí aplikace.
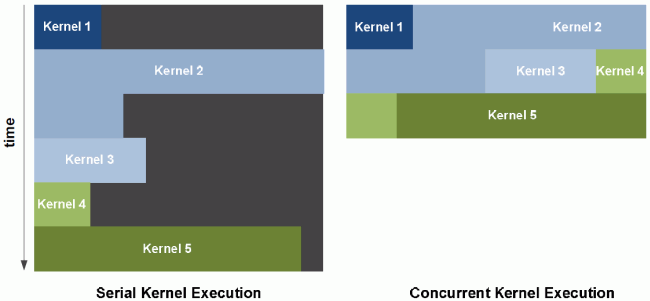
Fermi umí v jednom daném okamžiku počítat více kernelů současně. Padá tedy vlastnost předchozích generací, kdy byla nemalá část výkonu nevyužita, nyní se vše smrskává pouze na omezení, že dané úlohy musí být shodného obsahu. Rozdílné je nadále možné vykonávat pouze „po sobě“, ale aspoň mohou těžit z již zmíněného rychlejšího přepínání.
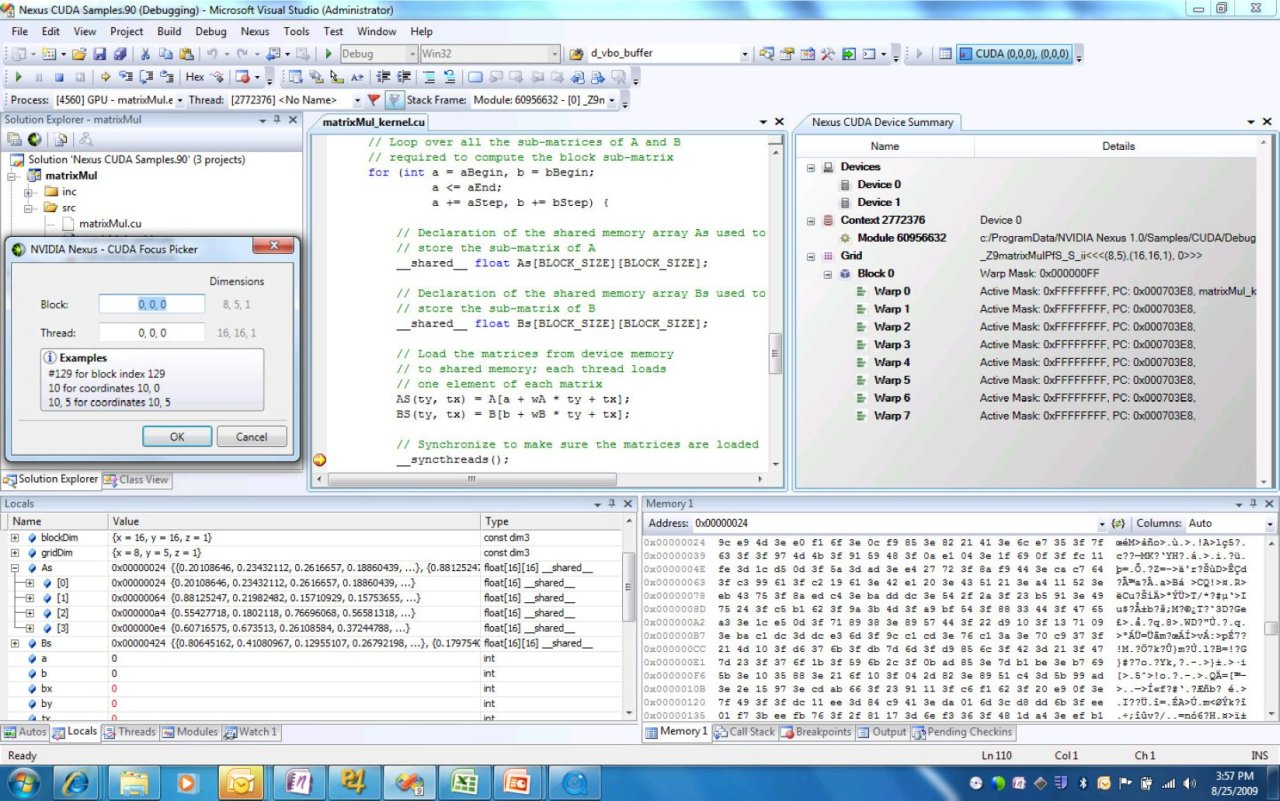
Krátce na závěr doplním, že NVIDIA připravila pro Fermi nástavbu Microsoft Visual Studia, vlastní vývojové prostředí Nexus. V něm je možné psát, ladit, debuggovat a tak vůbec všechny aplikace, ať již jsou psány v CUDA C, OpenCL či třeba DirectCompute. Nechybí ani podpora pro výkonnostní analýzu, možnost zaměřit se při debuggingu na jediný threadový výstup z tisíců paralelně běžících či možnost vizualizovat výsledky počítané všemi paralelními thready. O podpoře pro *nixová IDE se zpráva nezmiňuje.
Nyní je čas odhlédnout od faktů a podívat se na NVIDIA Fermi trochu subjektivně. Jistě jste si při bedlivém čtení všimli, že nezaznělo byť jediné slovo o reálném výkonu GPU, jeho chování ve hrách, ani slovo o tom, zdali bude na kartě DisplayPort, ani slovo o ničem v souvislosti s hrami, multimédii, spotřebou a tak vůbec. Ano, dnes NVIDIA provedla pouze papírové představení parametrů architektury, na které postaví budoucí generace svých GPU.
Jasně v tom cítím směřování nikoli ke hrám, ale k výpočtům. Ve hrách už se pomalu blížíme k pomyslnému stropu. Stále je sice možno nabídnout řadu skvělých technologií, mnoho takových v čele s tesselací nabízejí Radeony HD 5870, ale rasterizace jako taková možná dle pohledu NVIDIE mele z posledního (vzpomeňme, že její vůbec první grafický čip nepodporoval rasterizaci, nýbrž pracoval hardwarově s vektory) a NVIDIA tak hledá jiné cesty, z nichž jedna může být shodná s intelovským Larrabee: raytracing. Ten se pochopitelně počítá, a to je věc, která Fermi, i s ohledem na firemní zkušenosti a softwarovou podporu, půjde výborně.
Na jakákoli reální měření si však ještě nějakou dobu počkáme. Jak dlouho to bude, toť otázka, minimálně z hlediska herních karet GeForce opravdu netuším. Za jedno ale jistě mohu dát ruku do ohně: Fermi bude mít směrem k Linuxu náruč otevřenou daleko víc, než ji má Radeon HD 5870. A to se na tomto serveru rozhodně počítá.
Mimochodem, Jen-Hsun také oznámil, že Oak Ridge National Laboratory postaví s pomocí GPU NVIDIA nejrychlejší superpočítač na světě, který bude 10× výkonnější než dosavadní držitel rekordu.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
HW podpora raytracingu i pro mainstream, tj. x86? Pěkně, konečně budou hry vypadat realisticky a nebudou omezeny zaostalým DX 11, na tomto hardware si budou vývojáři moci naprogramovat cokoliv. Nvidia ihned dodá nástroje k tvorbě, na nic se nebude muset čekat.
raytracing za behu hry, to se nedivim, ze se snazi o co nejvykonnejsi GPU.
 1.10.2009 10:48
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
1.10.2009 10:48
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
Intel už představil první demonstrační video herní scény (Quake Wars). Sice to pořád nejede na dedikovaném HW, ale je to počítáno přes hezkou řádku xeonových jader (24), ovšem dalo by se to hrát.
http://www.youtube.com/watch?v=G-FKBMct21g
http://n-joy.cz/video/n-joy/xsj7e9jlssj2th5n
Raytracing je algoritmus jako dělaný na mutlithreading (jestli půjdou GK směrem univerzálních procesorů - zatím jsou dělané hlavně pro rasterizaci - tak se za 4-5 let můžeme dočkat prvních her a o pár let pozdějí i tříáčkových titulů a tradiční výrobci GK to stihnou rychleji než Intel), v podstatě lze každý paprsek trasovat na jednom jádře. Problémem je paměťová propustnost, kterou v návrhu Fermi mají také vyřešenou.
 3.10.2009 14:18
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.10.2009 14:18
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
To jako, že už konečně bude ve hrách možno potkávat něco jako toto, ale jen v reálném čase?
Pozn. pod čarou: rok výroby, léta páně 97-98.
 3.10.2009 21:36
cezz | skóre: 24
| blog: dm6
3.10.2009 21:36
cezz | skóre: 24
| blog: dm6
No myslim, ze zhruba takto vyzeraju hry momentalne :)
3.10.2009 21:46
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
3.10.2009 21:52
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
HryJako třeba to demonstrační video z QuakeWars?
3.10.2009 22:15
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
3.10.2009 22:22
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
3.10.2009 22:40
Heron | skóre: 53
| blog: root_at_heron
| Olomouc
 . Tam někde bych hledal to tvoje video. Kompletně spálený Far Cry 2 by se tomu hodně blížil zjevem krajiny.
Koridorové 3D střílečky vypadají pořád jako Quake Arena, protože jsou to prostě koridorové střílečky. Nevím, jakou odpověď očekáváš. Dneska jsem si zahrál Batman Arkham Asylum se softwarovým PhysX. Ano, ta hra vypadá úchvatně, ale bez efektní fyziky je to prostě jen jiný Bioshock nebo UT3. A pokud si to koupím, tak to bude jen k vůli zpracování hlavní postavy, stejně jako STALKER mám jen kvůli Černobylu. Jinak má u mě Batman 60% (tuctovka na starém engine) a STALKER 35% (bugovatost).
4.10.2009 21:40
cezz | skóre: 24
| blog: dm6
. Tam někde bych hledal to tvoje video. Kompletně spálený Far Cry 2 by se tomu hodně blížil zjevem krajiny.
Koridorové 3D střílečky vypadají pořád jako Quake Arena, protože jsou to prostě koridorové střílečky. Nevím, jakou odpověď očekáváš. Dneska jsem si zahrál Batman Arkham Asylum se softwarovým PhysX. Ano, ta hra vypadá úchvatně, ale bez efektní fyziky je to prostě jen jiný Bioshock nebo UT3. A pokud si to koupím, tak to bude jen k vůli zpracování hlavní postavy, stejně jako STALKER mám jen kvůli Černobylu. Jinak má u mě Batman 60% (tuctovka na starém engine) a STALKER 35% (bugovatost).
4.10.2009 21:40
cezz | skóre: 24
| blog: dm6
Já se furt nemůžu zbavit pocitu, že už tak posledních 10 let hraju furt nějak obměňovaný Quake 3 Arena.
Presne ten isty pocit som mal, nez som kupil PS3.. Ako uz pisal niekto vyssie, uz narazis aj na hry, ktore to tvoje video tromfnu. (Napriklad Mirrors Edge, Motorstorm, Pripadne niektoru z Brothers in Arms serie - teda spon tie som hral/hram)
 1.10.2009 07:45
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
1.10.2009 07:45
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
To už vyzerá tak že k tomu dorobia pár USB konektorov, vlastný zdroj a je tu ďaľšia rodinka počítačov NVIDIA.

Článek dobrej. jen by měl zajímal názor autora jakej že vlastně je pomyslnej strop ve hrách, nějak to nechápu ?
"Ve hrách už se pomalu blížíme k pomyslnému stropu."
1.10.2009 12:02
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Tak že hry sa už podobajú realite a realita je strop
2.10.2009 06:38
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Proc me napadlo uplne to same :o))))
Realičnost her už je fakt dobrá a jsem rád, že se tímto dál zvýší, k reálnosti to má ale pořád propastně daleko ... lámané hrany předmětů, ostré hrany stínů, atd. ... ale odrazy v zrcadlech a ve vodě už hezké ...
...a jsem rád, že se tímto dál zvýší...
Fuj!
IMHO to nie je o grafike, skor o pristupe k zabave. Viz napriklad LBP a podobne. Je sice pravda, ze taky MUD vyzaduje predstavivost trosku inej kategorie, ale to uz je trochu ina zalezitost.
opravte si :
ISA = Instruction Set Architecture, http://en.wikipedia.org/wiki/Instruction_set_architecture
 1.10.2009 14:31
David Ježek | skóre: 83
| blog: Mostly_IMDB
1.10.2009 14:31
David Ježek | skóre: 83
| blog: Mostly_IMDB
 1.10.2009 15:20
GandY | skóre: 3
| blog: Zo života
| Bratislava
1.10.2009 15:20
GandY | skóre: 3
| blog: Zo života
| Bratislava
a čo spotreba?
1.10.2009 15:39
David Ježek | skóre: 83
| blog: Mostly_IMDB
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 4.10.2009 00:11
4.10.2009 00:11

 1.10.2009 17:09
1.10.2009 17:09