Byla vydána nová verze 1.58 sady nástrojů pro správu síťových připojení NetworkManager. Novinkám se v příspěvku na blogu NetworkManageru věnuje Josephine Pfeiffer. Vypíchnout lze možnost nmtui zobrazit nastavení Wi-Fi jako QR kód nebo podporu CLAT (464XLAT) a tunelů GENEVE (Generic Network Virtualization Encapsulation).
Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
Po delší odmlce v seriálu o Qt4 jsme zpět. Doufám, že přestávka způsobená mou leností bude omluvena následujícími články, a zároveň doufám, že vážený čtenář snese dočasnou změnu autora.
Tento a příští článek seriálu bude poněkud jiný. Nebude obsahovat tolik kódu jako díly předchozí, ale přesto o oblíbený příklad nepřijdete.
Zároveň ale předpokládám, že tento článek bude pouze odrazovým můstkem ke studiu oficiální dokumentace, kde jsou popsány další metody, signály a závislosti.
V dávných dobách Qt3 se data do všelikých widgetů se seznamy, tabulkami a stromy plnila pomocí tzv. itemů. Qt4 sice takové plnění umožňuje také, ale jedná se pouze o obalené základní (a preferované) třídy view s vhodným modelem. Autoři Qt4 si od nového frameworku slibovali jednodušší práci a zásadní zrychlení interakce s datovými widgety. To druhé se podařilo beze zbytku, to první nechť si rozhodne každý sám dle osobních preferencí.
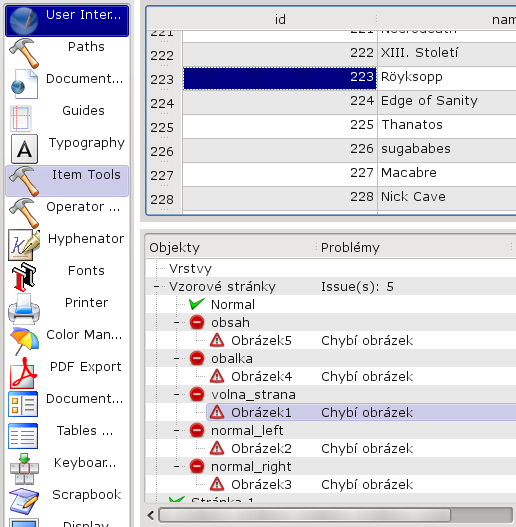
ukázka widgetů s modely: vlevo QListView, vpravo nahoře QTableView, dole QTreeView
Model-View-Controller (dále MVC) je klasický princip SW architektury. Je tak klasický, až prastarý, že budu dále předpokládat čtenářovu znalost, zkušenost anebo schopnost samostudia. Jen ve stručnosti:
Všechny tyto části by měly být nahraditelné jinými a zároveň na sobě nezávislé.
V terminologii Qt4 je všechno trošku zjednodušeno a roli Controlleru přebírá View, respektive se o práci dělí s objekty Delegate. Proto v Qt platí:
QStringModel * m = new QStringModel(); QStringList lst; lst << "foo" << "bar"; m->setStringList(lst); QListView * v = new QListView(); v->setModel(m); // oba view widgety budou zobrazovat stejna data QTableView * t = new QTableView(); t->setModel(m);
Všechny modely v Qt musí být potomkem třídy QAbstractItemModel. Data samotná nemusí být přímo agregována v instanci modelu, ale model je může na vyžádání načítat podle potřeby (např. modul QtSql).
Jakákoliv informace z modelu je z view odkazována přes QModelIndex, tj. dočasný odkaz na pozici v modelu. Tyto odkazy jsou platné pouze v aktuální okamžik a po změně hodnot dat (oznámeno signálem) se mohou změnit. QModelIndex určuje pozici dané položky svými atributy:
Všechny indexy daného modelu mají alespoň jednoho rodiče – tzv. Root Item. Parent indexu je zásadním údajem ve stromových strukturách, zatímco v jednoúrovňových seznamech není příliš podstatný. Řada a sloupec indexu je vždy uváděna relativně ke svému rodiči.
K přímému použití jsou už implementovány některé další třídy:
Subjektivní postřeh z praxe: QStandardItemModel jsem přestal používat poměrně brzy a začal si reimplementovat modely vlastní přímo z odpovídajících modelů abstratních. Přišlo mi, že spojovaly nevýhody MVC a Item Widgetů.
Každý prvek (item) modelu může obsahovat různá data, která se ve widgetech view zobrazují v různých rolích. View si pak sám přes metodu QAbstractItemModel::data() jednotlivé role načítá a zobrazuje je podle své implementace. Role definují, co bude pro daný index zobrazeno. Celou problematiku nejlépe osvětlí krátká ukázka kódu, popř. přiložený příklad (vytrženo z reálného programu):
QVariant CharTableModel::data(const QModelIndex &index, int role) const
{
if (!index.isValid())
return QVariant();
…
// ctecky pro nevidome, nebo se casto pouziva jako zdroj dat pri drag&drop
if (role == Qt::AccessibleTextRole && column == 0)
return m_characters[ix];
// tooltip
if (role == Qt::ToolTipRole)
{
QString tmp;
tmp.sprintf("%04X", currentChar);
return "Unicode:\n0x"+tmp;
}
// vygeneruj obrazek, ktery se zobrazi jako ikona
if (role == Qt::DecorationRole && column == 1)
{
… generuj obrazek…
return QVariant(QPixmap::fromImage(pix));
}
// jestlize je to cislo, pak zarovnej doprava jako v tabulkovem procesoru
if (role == Qt::TextAlignmentRole)
{
bool ok;
curr.toDouble(&ok);
if (ok)
return QVariant(Qt::AlignRight | Qt::AlignTop);
return QVariant(Qt::AlignTop);
}
…
V Qt se jako View označují widgety, které jsou schopné zobrazovat data, která jim předává asociovaný model. Přičemž jeden model může být napojen na několik view widgetů.
Všechny view widgety musí být potomkem třídy QAbstractItemView a implementovat alespoň minimální API. Zobrazení dat je plně v režii view widgetu, proto není problém data jednoho modelu jednou zobrazovat jako tabulku, zároveň jako graf anebo třeba stromovou strukturu.
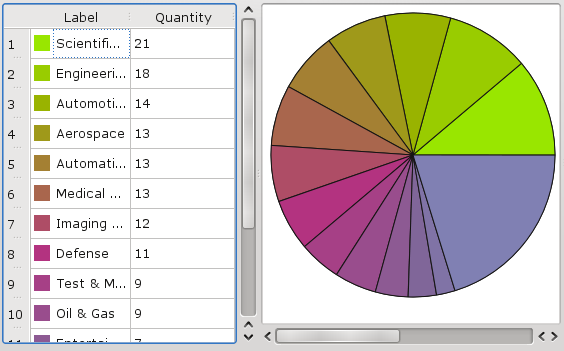
rozdílná vizualizace jednoho modelu: vlevo tabulka (všechna data modelu), vpravo
koláčový graf (pouze „Quantity“)
Jednotlivé prvky modelu, identifikované svým QModelIndexem, může view zobrazovat sám anebo může použít zobrazení pomocí delegáta tak, jak je použito v příkladu – vizte kapitolu „Popis příkladu“.
Další velmi podstatnou úlohou view widgetů je správa označených prvků modelu (selections). Abychom byli přesní, tak výběry nezpracovává přímo view, ale další specializovaný model QItemSelectionModel, který je ale přístupný pouze z dané instance view (QAbstractItemView::selectionModel()).
Standardní widgety, které lze rovnou použít bez jakéhokoliv zásahu:
View widgety se také starají o uživatelský vstup. Proto je v Qt zaveden pojem delegate/delegát. Delegát je widget, kterým view:
Pokud uživatel aktivuje (závisí na jeho platformě/operačním systému) prvek view widgetu (model musí být editovatelný, viz metoda flags()), view vytvoří potřebný delegát a naplní jej odpovídajícími daty z modelu. Pokud programátor nenastavil nově vytvořeného delagáta, view použije jeden z předdefinovaných implicitních delegátů v závislosti na typu editovaných dat – delegáta založeného na QLineEdit, QSpinBox apod.
Na jednoduché editace tyto implicitní editory často stačí, ale komplexnější data je většinou potřeba editovat jinak. Typickým příkladem mohou být multimediální data, struktury geografických systémů atd.
![]()
![]()
Vlevo implicitní delegát založený na QLineEditu.
Vpravo reimplementovaný delegát s rozsáhlejší
funkcionalitou (editace v databázi, tlačítka
„vlož NULL hodnotu“ a „otevři editor jako modální dialog“).
Implementace specializovaných delegátů musí vycházet z API třídy QAbstractItemDelegate, což bude vyžadovat více ruční práce, anebo použít QStyledItemDelegate či starší QItemDelegate.
Modely samy o sobě neumí zobrazovaná data řadit a filtrovat. Existuje ale specializovaná třída QSortFilterProxyModel, také potomek QAbstractItemModelu, která filtrování a řazení dat umí, aniž by se tato data fyzicky měnila ve zdrojovém modelu.
Modelová situace:
MyModel * model = new MyModel(); // predpokladejme, ze konstruktor nacte data
QTableView * view = new QTableView();
// view->setModel(model); nepouzijeme, protoze chceme filtrovat a tridit
QSortFilterProxyModel * proxyModel = new QSortFilterProxyModel();
// model se zdrojovymi daty podstrcime proxy modelu
proxyModel->setSourceModel(model)
// a proxy model nasatvime do view
view->setModel(proxyModel);
…
// uzivatel v nejakem widgetu nastavil filtr,
// ten se pres signal a slot prenese do naseho proxy modelu.
// Proxy model sam zablokuje nechtena data. Ta ale ve zdrojovem
// modelu stale zustavaji
proxyModel->setFilterWildcard("foo*");
Existující implementace QSortFilterProxyModel umí řadit pouze lexikograficky, tj. vše se pokusí převést na řetězce a ty pak porovná. Pokud chceme řadit data ve sloupci např. podle číselné hodnoty, anebo podle „ikonek“, musíme implementovat vlastní proxy model, který bude potomkem QSortFilterProxyModelu, a dokáže rozhodnout, které číslo nebo která QPixmapa je větší než druhá (metoda lessThan()).
Jedinou možností, jak plnit data do „seznamových“ widgetů v Qt3 a starších byly tzv. item widgety. V Qt4 je funkcionalita zachována, přičemž se jedná o specializované spojení modelu a odpovídajícího view widgetu.
Vezměme například jednoduchý seznam: Místo QListView a vlastnoručně implementovaného modelu je možné použít QListWidget a data plnit do instancí QListWidgetItem. Často používaný způsob práce je např.:
QListWidget * w = new QListWidget();
QString temp("%1");
for (int i = 0; i < 10; ++i)
w->addItem(new QListWidgetItem(QIcon("foo.png"), temp.arg(i));
Z ukázky je patrná zřejmě největší výhoda item widgetů: práce s nimi je, alespoň na první pohled, jednodušší. Není třeba implementovat vlastní modely, vkládání dat je „klasické“.
Na druhý pohled, anebo časem v reálném nasazení, se ale objeví některé zápory daného řešení:
Proto je, stejně jako v jakémkoli jiném případě, velmi vhodné používat mozek a dopředu si zanalyzovat, jaká, kolik a jak často měněná data budu v daném případě zobrazovat. Na seznam tří ikonek v konfiguračním dialogu se mi opravdu psát vlatní model nevyplatí.
V přiloženém balíčku je ukázkový spustitelný program, který ukazuje tak trochu nestandardní použití model-view-delegate. Hlavní funkčnost spočívá v jakési „lupě“, tedy zobrazení fotografie v tabulce, kde každá buňka tabulky patří právě jednomu pixelu obrázku. Při změně aktuální buňky tabulky se mění další informace o buňce v externích widgetech.
Zdrojové kódy příkladu (qmake; make).
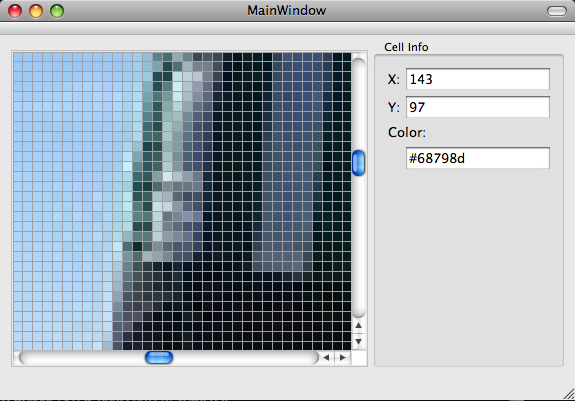
Příklad v akci.
Co mne vedlo zrovna k takovému příkladu? Rád bych, aby si čtenář hned zpočátku (pokud je Qt začátečník) uvědomil, že popisovaná doména může mít celu řadu použití, a že jako programátor ji nemusí využívat na prosté seznamy a strohé tabulky.
Implementaci jsem zvolil pomocí výše uvedené techniky „delegát zobrazuje data“, protože je v tomto případě subjektivně snazší kreslit do samostatného widgetu, delegáta, než generovat bitmapu a ošetřovat její korektní umístění do view přes model::data() – není nutné řešit otázku zarovnávání apod.
Klasické použití model-view-delegate si ukážeme v díle následujícím, přičemž celou problematiku okořeníme trochou SQL a databázemi obecně.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 Jestli to myslíte s programováním alespoň trochu vážně, tak se připravte na to, že hromada tísnivých, zdánlivě neuchopitelných, informací se na vás povalí s každým novým projektem. Technické záležitosti, jako MVC, je obvykle ta lehčí záležitost! Jsou k tomu manuály, tutoriály, poradny, články na ABC. Horší je to s věcnou problematikou. Naprogramujte si účetnictvý (workflow, procurement, metadata processing etc.) firmy, když některým vnitřním postupům, specifickým jen a jen pro tu firmu, rozumí jediný člověk ve firmě a ten to ještě neumí vysvětlit a dokumentace je neexistující nebo zastaralá. Podívejte se, jak tu na ABC ztěžka vzniká aplikace pro Datové Schránky. Zdá se vám to příliš abstraktní? Berte to jako drobný úvodní tréning.
Na Qt se mi líbí, že rozumě využívají existující patterny. Jakmile jednou pochopíte MVC, třeba právě na příkladu Qt, nebude vám dělat takový problém porozumět Javovskému Swingu, Springu, Jave EE, JSF, Struts, Eclipse RPC, tam všude se MVC používá, pravda trochu uzpůsoben specifikům platformy (desktop, web, ..) a jazyku (Java, C++).
Jestli to myslíte s programováním alespoň trochu vážně, tak se připravte na to, že hromada tísnivých, zdánlivě neuchopitelných, informací se na vás povalí s každým novým projektem. Technické záležitosti, jako MVC, je obvykle ta lehčí záležitost! Jsou k tomu manuály, tutoriály, poradny, články na ABC. Horší je to s věcnou problematikou. Naprogramujte si účetnictvý (workflow, procurement, metadata processing etc.) firmy, když některým vnitřním postupům, specifickým jen a jen pro tu firmu, rozumí jediný člověk ve firmě a ten to ještě neumí vysvětlit a dokumentace je neexistující nebo zastaralá. Podívejte se, jak tu na ABC ztěžka vzniká aplikace pro Datové Schránky. Zdá se vám to příliš abstraktní? Berte to jako drobný úvodní tréning.
Na Qt se mi líbí, že rozumě využívají existující patterny. Jakmile jednou pochopíte MVC, třeba právě na příkladu Qt, nebude vám dělat takový problém porozumět Javovskému Swingu, Springu, Jave EE, JSF, Struts, Eclipse RPC, tam všude se MVC používá, pravda trochu uzpůsoben specifikům platformy (desktop, web, ..) a jazyku (Java, C++).
 19.11.2009 10:53
Petr Bravenec | skóre: 43
| blog: Bravenec
19.11.2009 10:53
Petr Bravenec | skóre: 43
| blog: Bravenec
 19.11.2009 14:12
David Watzke | skóre: 74
| blog: Blog...
| Praha
19.11.2009 10:31
David Watzke | skóre: 74
| blog: Blog...
| Praha
19.11.2009 10:47
Petr Bravenec | skóre: 43
| blog: Bravenec
19.11.2009 14:12
David Watzke | skóre: 74
| blog: Blog...
| Praha
19.11.2009 10:31
David Watzke | skóre: 74
| blog: Blog...
| Praha
19.11.2009 10:47
Petr Bravenec | skóre: 43
| blog: Bravenec

 19.11.2009 17:32
Saljack | skóre: 28
| blog: Saljack
| Praha
19.11.2009 17:32
Saljack | skóre: 28
| blog: Saljack
| Praha
 21.11.2009 12:36
Martin Stiborský | skóre: 26
| blog: Stibiho bláboly
| Opava
21.11.2009 12:36
Martin Stiborský | skóre: 26
| blog: Stibiho bláboly
| Opava
Skvělé. Děkuji.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz