Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »Byla vydána nová verze 1.58 sady nástrojů pro správu síťových připojení NetworkManager. Novinkám se v příspěvku na blogu NetworkManageru věnuje Josephine Pfeiffer. Vypíchnout lze možnost nmtui zobrazit nastavení Wi-Fi jako QR kód nebo podporu CLAT (464XLAT) a tunelů GENEVE (Generic Network Virtualization Encapsulation).
Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Čipové sady řady AMD 700 jsou tu s námi již pár let a ač dostávaly průběžně nový svěží vítr, minimálně v podobě jižního můstku SB750, je zkrátka čas na inovaci. Tou bude mimo jiné čipset tvořený severním můstkem AMD 890GX (resp. jeho variace bez integrované grafiky 890FX) doprovázeným jižním SB850. Těšit se můžeme na již známé 6,0Gbps rozhraní SATA, resp. v řadě případů též USB 3.0 (implementované přídavným řadičem).



Například takový Asus M4A89GTD PRO přidává USB 3.0 známým řadičem NEC (asi jediné v nedávné minulosti dostupné řešení, již je pár týdnů na řadě desek hlavních výrobců). Sluší se ještě doplnit, že součástí tohoto čipsetu je integrovaný ATI Radeon HD 4290 se 128MB pamětí Sideport, což též v dnešní době již prakticky automaticky znamená vedle D-Sub i přítomnost výstupů DVI a HDMI (která deska s 890GX nebude mít aspoň jeden digitální výstup, ta je zjevně určena pro naprosté ignoranty :-).
Asustek přidává tlačítka pro Core Unlocker a Turbo Key II (něco napovídají v názvu, ale přesnou funkci prozradí až recenze), ale více jistě potěší i vyšší konektor přídavného napájení CPU (do těch standardně vysokých schovaných mezi mrakodrapy měděných heatpipe chladičů na MOSFETech se kabel opravdu blbě osazuje a ještě blběji vyndavá (a člověk pak vypadá, jakoby si ve svých 30 letech kousal nehty).












Gigabyte GA-890GPA-UD3H také přichází s 6,0Gbps SATA a USB 3.0 na bázi NECu. Když už jsme u toho SATA, oněch rychlých portů skrývá jižní můstek celkem šest. Dále nechybí dnes již obvyklá výbava, a sice gigabitová síťovka (stejně jako u Asusteku, viz fotografie záslepky), FireWire, 7.1 zvukovka, opět DVI. HDMI i D-sub (škoda, že se neprosazuje DisplayPort na základních deskách tolik jako na Radeonech poslední generace).
U Gigabytu si můžeme zmínit i konfiguraci PCI Express linek, kde oba velké x16 sloty mohou dostávat i kombinaci po osmi linkách (k provozu CrossFire, jakkoli je to pod Linuxem zhola nezajímavé), podpora paměti je sice převážně otázkou procesoru, ale Gigabyte ji udává až po DDR3-1866+ (což je overclockingová hodnota, standardně buď 1066 nebo 1333).
AMD 890G/FX se blíží velmi rychle a letošek bude na platformě AMD ve znamení těchto čipsetů. Připomenu, že v průběhu tohoto roku (poslední drby hovoří už o jaře) se mají objevit šestijádra do patice AM3 a samozřejmě po uvedení Radeonů HD 5800 se čeká i pozdější „refresh“, po vzoru HD 4890 zatím označovaný jako HD 5890.
Kalifornská Nvidia u příležitosti CES samozřejmě poodhalila pokličku dalšího hrnce tvořícího „vybraný sled chodů známý jako Fermi“. Tento hrnec nese informace o GPU Fermi jakožto grafické kartě. Většina prezentovaných informací tak je shodná s představením architektury Fermi na výpočetní konferenci, pouze s tím rozdílem, že byly prezentovány ty části GPU, které třeba karty Tesla ke své činnosti zas tak moc nepotřebují. Pojďme se na vše v krátkosti společně podívat.
Ve stručnosti zmíním hlavní body, které „vypíchla“ sama Nvidia. Nové GPU je převážně srovnáváno s předchozím GT200 (alias GeForce GTX). Oproti němu vzrůstá počet CUDA procesorů z 240 na až 512, největšími úpravami prošla geometrická pipeline, její výkon je až osminásobný, dále je zde nový režim vyhlazování hran 32×CSAA s podporou alpha-to-coverage a mnohé další.
Většina inovací, které nebyly zmíněny již dříve, souvisí s rozhraním DirectX 11, resp. jeho částí Direct3D. V něm byla kromě jiného specifikována tesselace, metoda známá v různých variantách již mnoho let a v desktopech prvně (z hlediska prosazení však neúspěšně) implementovaná firmou ATI v Radeonech 8500, resp. s ní svázaný displacement mapping. Schopnosti jsou demonstrovány na několika různých demech, ať již přímo od Nvidie, ATI, nebo nezávislých subjektů. Pro Linux bude směrodatné, jak rychle se podaří začlenit tyto věci do OpenGL (mnoho tam již je), případně implementovat ve Wine pro hraní her z Windows.
I GF100 jakožto „grafická varianta“ Fermi nese 768 kB L2 cache a systém rozdělené 64kB paměti konfigurovatelné buď jako L1 cache, nebo jako sdílená paměť. Paměti jsou typu GDDR5, což díky vysokým efektivním pracovním frekvencím umožnilo udržet šířku sběrnice na 384 bitech, aniž by tím trpělo GPU z hlediska dodávky dat v obou směrech.
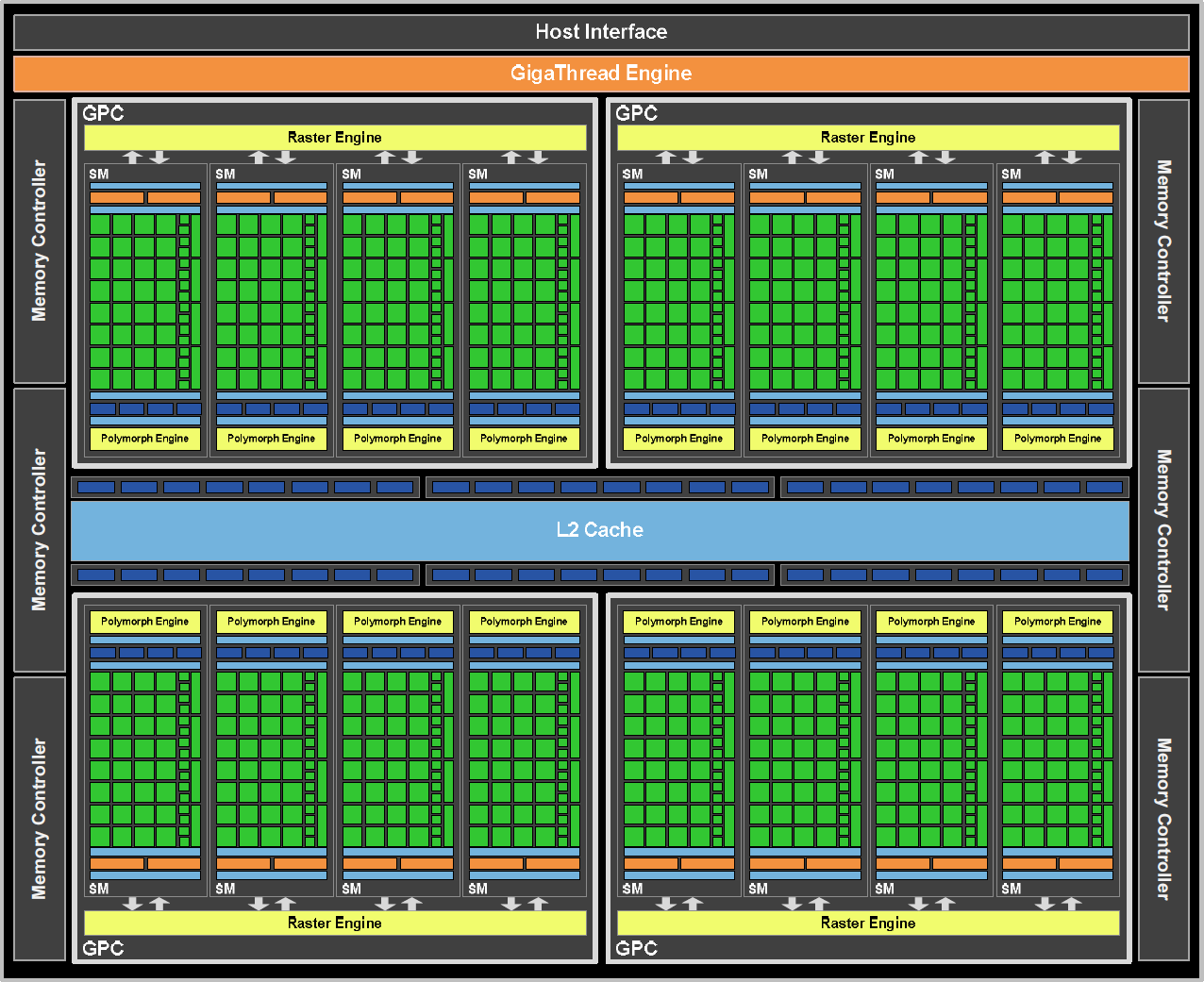
Grafická část GPU pochopitelně nese také škálovatelný rasterizační engine pro triangle setup, rasterizaci a z-cull, jako tomu bylo dosud (rasterizace se hned tak nezbavíme, prezentace raytracingu jsou z hlediska her stále jen jakési „laboratorní cvičení“, nic více). Druhou hlavní zajímavostí je PolyMorph engine určený právě pro tesselaci a vůbec práci s vertexy.
Dosavadní GPU Nvidia měly monolitické uspořádání prvků pro fetch/assemble/rasterizaci trojúhelníků, které bylo velmi neefektivní z geometrického hlediska. GPU mělo pro určité typy operací pevně přiřazené jednotky, které nemohly své využití variabilně měnit dle typu úloh. Nový polymorfní engine tak dává v této oblasti podobnou unifikaci, jakou přinesl přechod od pixel+vertex shaderů k unifikovaným. Každá šestnáctice „polymorfů“ má k dispozici vlastní vertex fetch a tesselační jednotku a tento blok provádí následující operace: Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup a Stream Output. Výstup jde do SM bloku, zde se provedou shadery a výsledek jde zpět do polymorfních enginů a tak stále dokola, než je hotova veškerá zadaná práce a výstup je k rasterizačním enginům na finální fázi.
![]()
Rasterizace se v GF100 provádí paralelně a jde o dva základní úkony: Výpočet pozic vertexů a výpočty pro triangle edge. Tak se zjistí, co ze scény bude skutečně vidět, a co nikoli – to se následně zahodí. Nejde o nic nového, tento způsob ulehčení práce je v principu znám již velmi dlouho a implementován byl již třeba v PowerVR Kyro 2 před více než 6 lety.
Rasterizer si poté vše převezme, spočítá pixel coverage, což opakuje několikrát, podle toho, je-li zapnut (a jaký konkrétně) antialiasing. Jednotka z-cull tak dostává již téměř hotový výsledek, ve kterém jen porovná Z souřadnici pixelů s tím, co momentálně visí ve framebufferu, a zahodí vše, co by bylo schováno. Tím opět ulehčí následnému zpracování v pixel shaderech.
Texturovací jednotky také odrážejí evoluční vývoj směrem k DirectX 11. Mimo jiné podporují nové formáty komprese textur BC6H a BC7 navržené mimo jiné ke snížení paměťové náročnosti pro HDR rendering.
Z hlediska 3D hraní má Nvidia na trhu vlastní systém 3D Vision spoléhající na 120Hz LCD a aktivní brýle s polarizací. Vedle toho jako konkurenci k ATI EyeFinity připravila upgrade zvaný 3D Vision Surround, který takto v 3D umí provozovat tři LCD o 1920×1080/120 Hz, včetně korekce pro nastavení tloušťky rámů LCD monitorů.
Tolik Fermi pro dnešek. Jak vidíte, opět šlo o vypuštění papírových informací, ale poslední indicie hovoří o tom, že karty tu budou „za pár týdnů“, a to v plné parádě mnoha a mnoha kusů. Ostatně o tom zčásti hovoří další část dnešního článku, já jen explicitně zmíním, že zatím stále neznáme konkrétní parametry žádné z karet. Je ale nad slunce jasné, že vedle „GeForce GTX 380“ napájené 6+8pin konektory PCI (tedy do 300 W TDP; uvidíme, jaká výrazně nižší bude reálná hodnota) tu budou i modely nižší. Víme o oněch kartách Tesla se 448 CUDA procesory, tytéž očekávám i mezi GeForce, stejně jako 256CUDA mainstram, 128CUDA lowend a kdo ví co postupem času i mezi nimi. Osobně si takto od stolu dovolím veškeré narážky na to, že „Fermi bude drahé a nedostupné a nenažrané“ odpálit tím, že na hi-end to možná vztáhnout půjde, ale mainstream bude o něčem jiném. Ostatně, kdo měl v ruce Radeon HD 5800 nebo rovnou 5970, ten může potvrdit, že v zátěži to nejsou ani tiché, ani úsporné karty, zatímco HD 5700 jsou o něčem zcela jiném.
Osobně doufám, že je toto poslední krátká zastávka u TSMC: Vicepresident firmy Mark Liu totiž prohlásil, že firemní 40nm výrobní technologie je konečně na úrovni 65nm a tudíž je dostatečně výtěžná, aby přestaly snad definitivně drhnout dodávky čipů partnerům.
Tím pochopitelně myslel zejména dodávky AMD a Nvidii, které obě na svá GPU poslední generace nervózně čekají již dlouhé měsíce, přičemž doufají, že objemy porostou a zmetkovost spadne ke dnu. Tak by to nyní mělo být, tudíž bych pomalu začal vyhlížet nasycení trhu Radeony HD 5800, stejně jako připravenost Nvidie na uvedení GeForce „GF100“ stylem okamžité dostupnosti v obchodech. No, že to ale trvalo.
Jinak se Mark nechal slyšet i o nových továrnách, ve třetím čtvrtletí chtějí rozjet výrobu 28nm procesem a v přípravě je již i továrna pro 22nm proces. Nicméně po tom, jak poslední roky TSMC své partnery mezi výrobci GPU pravidelně trápí s nekvalitou výroby, bych toto nechal bez komentáře a k tématu se vrátil až zase za zhruba rok (s novou generací GPU).
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 29.1.2010 14:13
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
29.1.2010 14:13
Ruža Becelin | skóre: 40
| blog: RuzaBecelinBlog
 29.1.2010 16:08
Ravensun | skóre: 11
| blog: Ravensun's blog
| Praha
29.1.2010 16:08
Ravensun | skóre: 11
| blog: Ravensun's blog
| Praha
 31.1.2010 13:27
Limoto | skóre: 32
| blog: Limotův blog
31.1.2010 13:27
Limoto | skóre: 32
| blog: Limotův blog

Tak nějak nechápu směřování AMD. V době největší slávy K8 měli k dispozici jednochipové nForce, od integrace řadiče paměti do procesoru nebyl NB prostě potřeba. Procesor přiojili rychlým Hypertransportem.
Procesor <=HT=> nForce SB
Pouze high-end pro mnoho grafik vyžadoval 2 chipové řešení chipsetu, a nVidia jako člen Hypertransport konsorcia používala rychlý hypertransport:
Procesor <=HT=> nForce NB <=HT=> nForce SB
Všechny PCIe linky, SATA, USB a PCI periferie tedy komunikovaly s procesorem a mezi sebou rychlou HT sběrnicí.
Pak AMD koupilo ATI, které mělo o poznání horší a zastaralé řešení, neboť používalo klasický koncept severního a jižního můstku spojených 4 PCIe linkami, které ATI nazývala A-Link:
Procesor <=HT=> ATI NB <=PCIe4x=> ATI SB
Nejen, že neexistovalo elegantní jednochipové řešení, ale komunikace mezi severním a jižním můstkem byla řádově pomalejší. Prakticky totožné řešení nabízel i Intel, neboť spojení mezi NB a SB zvané DMI je rychlostně totožné s PCIe4x. Zajímavé je, že AMD dodneška nepřišlo se zajímavým jednochipovým řešením typu nForce 550, 570SLI, nForce 630, nForce7050, nForce8200/8300 či nForce 750 ani se spojením NB a SB pomocí Hypertransportu, jako to má nVidia u high-endových modelů. Je evidentně mnohem efektivnější jednoduchý chip s IGP, než zbytečná kombinace dvou kusů, které vždy více žerou a nepochybně prodražují i návrh desky. Je nepochybné, že připojení SB pomocí A-link (PCIe 4x) je s příchodem SATA 6Gb a USB 3.0 úzkým hrdlem, a i když se rychlosti s novými verzemi PCIe vždy zdvojnásobují, jen těžko se to vyrovná efektivitě Hypertransportu. Ať už má na konkrétní chipsety nForce každý názor jakýkoli, jejich systém zapojení pomocí HT linků byl geniální a je s podivem, že AMD nejen že nereflektovalo tuto svou technologickou výhodu a místo toho pokračuje v horším konceptu ATI, ale dokonce se snaží nVidii ze své platformy vyštípat. Je to skutečně zvláštní, protože první co v Intelu udělali po integraci paměťového řadiče bylo, že vyvinuuli jednochipový chipset řady 55, a PCIe linky strčili rovnou na procesor. Hign-endové řešení X58 sice odpovídá aktuálním AMD/ATI chipsetům:
Procesor <=QPI=> Intel NB <=PCIe4x=> Intel SB
Ale v roadmapě produktů Intel budou budoucí high-endová řešení na socketu 2011 už také pouze jednochipová, a PCIe linky přijdou přímo na procesor. AMD tak evidentně postupuje plnou parou vzad. O což se evientně snaží už polední pár let.
30.1.2010 11:34
Limoto | skóre: 32
| blog: Limotův blog
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz