3D software Blender byl vydán ve verzi 5.2 s prodlouženou podporou. Videopředstavení na YouTube.
SketchForge 3D (GitHub, reddit) je open source 3D editor / CAD běžící ve webovém prohlížeči bez nutnosti účtu nebo cloudového úložiště. Inspirovaný byl Tinkercadem. Doporučena je lokální instalace.
Byla vydána nová verze 11.9 webového prohlížeče Midori (Wikipedie, GitHub). S novým centrem ovládání, pokročilejším blokováním reklam, optimalizací výkonu…
Na Crowd Supply běží kampaň na podporu open source čtečky elektronických knih Open Book Touch. Postavena je na ESP32-S3. Má 4,26palcový dotykový e-papírový displej s rozlišením 480×800 pixelů, podsvícení, slot na microSD kartu. Cena je 149 dolarů a poštovné 12 dolarů. Dodání je plánováno na duben 2027.
Na Humble Bundle běží akce Linux: All the Things by O'Reilly a Picos, HATs, and More by Raspberry Pi Press. Elektronické knihy lze koupit se slevou a současně podpořit organizace Code for America a Raspberry Pi Foundation.
FreeCAD (Wikipedie), tj. svobodný multiplatformní parametrický 3D CAD, má nový vtipný a současně užitečný doplněk Banana For Scale (GitHub). Aktuálně umožňuje do výkresu vložit banán nebo plechovku pro porovnání a určení měřítka.
Blender Studio nedávno oznámilo plán vytvořit svůj první otevřený (open source) celovečerní film. Film by se měl jmenovat Overgrown (YouTube). Film vznikne, pokud se zajistí financování. Prvním krokem je získat 7 000 předplatitelů Blender Studia. Cena je od 11,50 eur měsíčně. Aktuálně počet předplatitelů je 5 289. Předplatné pokryje 20 % nákladů. Zbytek, 80 % nákladů, má být financován externími producenty nebo distributory.
Byl vydán Debian 13.6, tj. šestá opravná verze Debianu 13 s kódovým názvem Trixie a Debian 12.15, tj. poslední patnáctá opravná verze Debianu 12 s kódovým názvem Bookworm, k dispozici je LTS. Řešeny jsou především bezpečnostní problémy, ale také několik vážných chyb. Instalační média Debianu 13 a Debianu 12 lze samozřejmě nadále k instalaci používat. Po instalaci stačí systém aktualizovat.
V jádře Linux byla nalezena a v upstreamu již byla opravena kritická zranitelnost GhostLock aneb CVE-2026-43499. Lokálnímu uživateli umožňuje získat práva roota a také obejít kontejnerovou izolaci. Zranitelnost existovala v Linuxu 15 let, tj. od roku 2011, od Linuxu verze 2.6.39.
Evropská komise předběžně shledala, že návykový design aplikací Instagram a Facebook od americké společnosti Meta porušuje unijní nařízení o digitálních službách (DSA). Návykový design zahrnuje například takzvané nekonečné posouvání, automatické přehrávání videí, tzv. push notifikace, kdy aplikace uživatele vybízí k návratu do jejího prostředí, či vysoce personalizovaný algoritmus, který rychle pozná, co uživatele baví a snaží
… více »Varování: tento článek není o Javě, přesto, že se někomu může zdát, že je v něm až příliš kódu v Javě. Klidně si za ni dosaďte třeba C++ a s malými odchylkami (rozhraní, reflexe) bude platit to stejné. Stejně tak není o Pythonu - ten jsem zvolil jako zástupce dynamických OOP jazyků. Přestože jsou pokročilejší jazyky (například Smalltalk), z Pythonu toho umím více.
Překladač je program, který (velice zjednodušeně řečeno) postupně prochází kód v nějakém programovacím jazyce a z něj generuje spustitelný soubor (nebo bytecode). Samotný překlad se sestává z několika fází a třetí je:
Ovšem jak lexikální, tak ani syntaktická analýza není vše. Následující kód je z hlediska scanneru, tak i parseru naprosto v pořádku:
" program ve Smalltalku " n := 10. s := 'Hello, world!'. [n = 10] if: [ Transcript show: n, s; cr. ]No, nejen z hlediska scanneru, ale i z hlediska většiny lidí, kteří ve Smalltalku neprogramují (tímto děkuji Pavlu Křivánkovi za to, že mě donutil si nainstalovat Squeak a ten příklad si taky spustit a opravit :-)). Řekněme to takhle: syntaxe je správně, ovšem program stejně nejde spustit. Při pokusu o jeho spuštění ve Squeaku nám virtuální stroj nabídne řešení problému, že selektor zprávy
#if není znám.
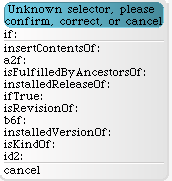
Po opravení všech tří chyb, které jsem napáchal, získáme zdrojový kód, který je platný nejen po syntaktické, ale i sémantické stránce.
" program ve Smalltalku " n := 10. s := 'Hello, world!'. (n = 10) ifTrue: [ Transcript show: s; cr. ]
Formálně rozlišujeme tři druhy sémantik:
Zanecháme teoretické informatiky a formálních definic a přejdeme na příklad. Následující operace mají (v podstatě) stejnou sémantiku a to, že provedou konkatenaci řetězců a a b, přičemž výsledek uloží do proměnné c — concat.tar.gz.
/*C*/ strcat(c, a); strcat(c, b); //C++ std::string c = a + b; okno + "titulek"; #shell c=$a$b #PHP, Perl $c = $a . $b; --Oracle PL/SQL c := a || b; #Python c = a + b "Smalltalk" c := a, b. ;Common Lisp (setq c (concatenate 'string a b))
Jak vidíme, tak jazyky se docela dost liší v syntaxi zápisu operace, která má nakonec (prakticky) stejný výsledek. V C nejsou řetězce, a tak se problém řeší dvojitým voláním funkce strcat(). V shellu stačí napsat dvě proměnné vedle sebe a jejich obsah se pouze expanduje. V PHP, Perl a PL/SQL mají pro konkatenaci speciální operátor, což je pravděpodobně nejlepší způsob. V Pythonu a C++ se používá operátor +. V obou jazycích se jedná o volání speciální metody, které provádí vlastní sčítání. Tento způsob ovšem nezachovává komutativnost operátoru +. Protože pro řetězce neplatí vztah a + b = b + a, který platí pro čísla (zanedbáme omezení vyjádření čísel v počítačích), takže z matematického hlediska je lepší používat jiný znak. Smalltalk se také vydal cestou speciálního operátoru (znalci vědí, že , není operátor, ale selektor zprávy a podobně jako v Pythonu se nakonec jedná o volání příslušné metody). A nakonec implementace v Lispu se podobá jazyku C, kdy se pro konkatenaci volá funkce (pro větší podobnost by stačilo definovat funkci char* concatenate(const char* ch1, const char* ch2)).
Mezi příklady se nám objevil jeden, který má sémantiku odlišnou. Je to proslavený přetížený operátor +, který nastavuje titulek okna v jednom nejmenovaném toolkitu, což je častý argument odpůrců přetěžování operátorů. Tato konstrukce má odlišnou sémantiku a takové použití operátorů není správné. Překladače obvykle nemají možnost rozpoznat a odmítnout uživatelsky definovaný operátor se špatnou sémantikou (výjimkou je třeba Prolog), proto je důležité, aby programátoři svoje nadšení pro operátory krotili a používali je pouze na vhodných místech. Nicméně ani to nepovažuji za argument proti přetěžování operátorů, protože pokud by dotyčný programátor zvolil pro nastavení titulku metodu add(), byl by to potom argument proti metodám? Anebo spíš ukázka špatně zvoleného jména.
Pojem typ proměnné je v každém programovacím jazyce velice důležitý. Když jsem se učil programovat v Basicu, proměnné a funkce se znakem $ na konci byly řetězce (moje oblíbená funkce INPUT$) a ostatní byly čísla. V některých implementacích (třeba Atari Basicu) nebylo více konstrukcí - jako procedury, které nahrazoval příkaz GOSUB (a GOTO pro skutečné programátory). Když jsem potom přišel k Pascalu, musel jsem se naučit deklarovat typy tímto způsobem:
var i, j, k : integer; errMsg : string[20];
Což způsobovalo mojí oblíbenou chybovou hlášku tajp mišmaš
(type mismatch). V té době jsem nerozuměl, proč Pascal nedokáže přiřadit integer z typu real a proč to prostě neořízne, jako to fungovalo v Basicu. Ovšem záhy jsem poznal, že různé jazyky řeší problematiku typů různými způsoby.
Statické typování velice dobře známe z jazyků jako je Pascal, C, C++, Java nebo třeba Haskell. Při programování v těchto jazycích musíte explicitně deklarovat typy proměnných. Příkladem je
//staticke typovani v jazyce Java NejakaTrida foo = new NejakaTrida();
Deklarujeme proměnnou typu NejakaTrida, kterou ihned inicializujeme konstruktorem patřičné třídy. V těchto jazycích je tedy typová informace explicitní a nezávislá na proměnné. Při deklaracích hlaviček funkcí/metod je tedy nutné uvádět typy, který musí parametry splňovat. Tohoto faktu velice silně využívá C++ při tzv. přetěžování funkcí, kdy má jedna funkce několik implementací, které se vybírají na základě datových typů parametrů. C++ přineslo celou řádku nových datových typů, které mají usnadnit právě psaní přetěžovaných funkcí.
void spam(unsigned int i); void spam(signed int i);
Při překladu statického jazyka dojde ke kontrole sémantiky (a s tím související typové kontrole) jazyka, což znamená, že jsou typy do programu (až na některé výjimky) zadrátovány
natvrdo. Na druhou stranu mnoho jazyků nabízí prostředky k obcházení typového systému, protože jsou situace, kdy je statické typování omezující. Jazyk C nabízí ukazatel void*, C++ má navíc šablony. V Javě pro tento účel používáme typ Object a od verze 1.5 také šablony.
Ovšem ani statické typování není všemocné a existuje mnoho věcí, které v době kompilace vůbec ošetřit nejde. Oblíbené přetečení zásobníku v C je jenom hezkým důkazem toho, že bez runtime kontrol nejde zabezpečit přístup do paměti. Ostatně oblíbené výjimky jazyka Java (a jiných) nejsou nic jiného, než běhové kontroly.
Dynamické typování je odlišným způsobem. Přestože bude mnoho programátorů, kteří používají staticky typované jazyky, tvrdit opak, dynamické typování neznamená slabé, nebo dokonce žádné typování. Naopak, mnoho dynamicky typovaných jazyků je silně typovaných. Odlišnosti oproti statickému jsou dvě.
Pokud nevěříte, tak následuje ukázka:
// Java Integer i = new Integer(15); |
# Python i = 15 type(i) <type int> |
; Common Lisp (type-of 15/2) RATIO |
Takže zatímco ve staticky typovaných jazycích je nutné proměnné deklarovat a typovost uvádět explicitně (a třeba v Javě dokonce dvakrát), u dynamických tomu tak není. Proměnné jsou reference na interní reprezentaci objektu a její nedílnou součástí je i typ proměnné. To znamená, že z hlediska jednoznačnosti typových informací jsou na tom jak statické, tak dynamické jazyky naprosto stejně (vynecháme problematiku slabě typovaných jazyků jako třeba shellu). Hlavním rozdílem je tedy místo uložení typové informace, zda je v runtime, nebo ve zdrojovém kódu.
Jenom poukáži na častou výhradu, která se v této souvislosti objevuje. Následující kód
Object x = (Object) new Foo();
nedává u dynamických jazyků vůbec smysl. Prostě se vytvoří instance třídy Foo a pokud podporuje potřebné metody (rozumí daným zprávám), není žádný důvod přemýšlet nad něčím takovým, jako je přetypování. Ostatně, dynamické jazyky operátory přetypování nenabízejí. Tedy pokud za ně nepovažujeme konverzní funkce, třeba pro převod z čísla na řetězec.
Jedná se o velice podstatné změny programátorova myšlení, a i proto jsou dynamicky typované jazyky často odmítány. Při překladu dynamického jazyka prakticky nedochází k sémantické kontrole, ta se dělá až za běhu programu. Tedy v té době, kdy se vyhodnocují typy. Hezký příklad jednoho ze základních principů používaných v dynamických (OOP) jazycích nabízí Java (ano, opravdu Java) — viz její definice metody System.out.println:
public void println(Object x)
Tato metoda dokáže vytisknout libovolný objekt. Nevěříte?
public class PrintableHW {
public PrintableHW() {}
public String toString() {
return "Hello, world!";
}
};
....
//uplne jina class a jina metoda  System.out.println(new PrintableHW());
System.out.println(new PrintableHW());
A výstupem je Hello, world!. Toto je klasický případ situace, kdy nás absolutně nezajímá typ daného objektu. Zajímá nás, zda podporuje metodu toString(), kterou zavoláme.
Co se to tu vlastně stalo? Za prvé jsme trochu ošidili typový systém Javy (protože je PrintableHW potomkem třídy Object, obešla se akce bez explicitního přetypování) a díky reimplementaci metody toString() třídy Object se zavolala naše metoda a ne ta implicitní. Kód potenciálně složité metody toString se nám potom rozpadá na něco jako
public void println(Object x) {
"vytiskni_retezec"(x.toString());
"vytiskni_retezec"(EOL);
}
Ovšem, jak jsem už napsal. Java není dynamicky typovaný jazyk (přestože obsahuje některé jejich rysy) a podobné vlastnosti nabízí pouze při přetěžování metod třídy Object. V okamžiku, kdy si řekneme, že by se nám podobná vymoženost hodila i u jiných metod, musíme začít dědit, anebo vytvořit nějaké rozhraní, které musí implementovat všechny třídy, které chceme podobným způsobem používat.
Takže hlavním rozdílem mezi staticky a dynamicky typovanými jazyky je okamžik, kdy se zjišťuje, zda daný objekt podporuje danou metodu. Ve staticky typovaných jazycích kontrola probíhá ve fázi překladu, v dynamicky typovaných v době běhu. Dynamický styl programování bývá také nazýván jako duck typing, kde se k objektům přistupuje pomocí kachního testu:
If it walks like a duck and quacks like a duck, it must be a duck.
Pokud to chodí jako kachna a kváká jako kachna, potom to musí být kacha.
Což přesně vystihuje rozdíl. Staticky typovaný jazyk se zeptá — je daný objekt typu kachna? Pokud ano, zavolej metodu quack(). Dynamický jazyk funguje odlišně — má daný objekt metodu quack()? Pokud ano, zavolej ji. Je zřejmé, že není žádný problém podstrčit dynamickému jazyku například syntetizátor, který shodou okolností obsahuje metodu quack() :-). Podobná granularita až na úrovni jednotlivých metod je sice možná i ve staticky typovaných jazycích, ale nárůst počtu abstraktních tříd či rozhraní bude enormní.
Příště si provedeme podrobnější porovnání statických a dynamických jazyků, protože se jedná o téma, které je velice zajímavé. Dojde i na šablony, přičemž zjistíme, že jde pouze o další import dynamičnosti do statických jazyků. V tomto díle nám zbývá jenom ukázat slíbený obrázek prvních tří fází překladu:
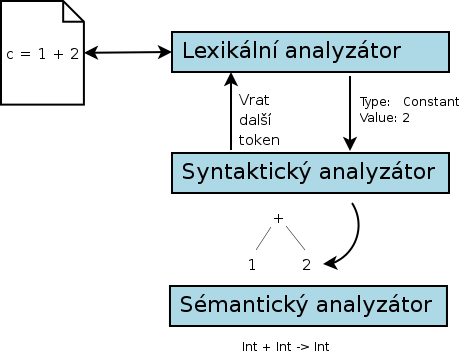
Na závěr bych chtěl poděkovat Pavlu Křivánkovi za článek Statická vs. dynamická typová kontrola, který mě inspiroval k sepsání tohoto (dvoj)dílu o statických a dynamických typových systémech.
Nástroje: Tisk bez diskuse
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 11.10.2006 00:16
freshmouse | skóre: 42
| blog: Bruno Banány
).
11.10.2006 14:03
freshmouse | skóre: 42
| blog: Bruno Banány
Ale je z toho vidět, že tomu rozumí alespoň autor (nebo nerozumí, ale umí to podat tak, aby to vypadalo, že tomu rozumí). A kromě toho je to psáno hezkým slohem + je to zajímavé téma. Víc takových článků.
11.10.2006 14:51
freshmouse | skóre: 42
| blog: Bruno Banány
11.10.2006 00:16
freshmouse | skóre: 42
| blog: Bruno Banány
).
11.10.2006 14:03
freshmouse | skóre: 42
| blog: Bruno Banány
Ale je z toho vidět, že tomu rozumí alespoň autor (nebo nerozumí, ale umí to podat tak, aby to vypadalo, že tomu rozumí). A kromě toho je to psáno hezkým slohem + je to zajímavé téma. Víc takových článků.
11.10.2006 14:51
freshmouse | skóre: 42
| blog: Bruno Banány
 15.10.2006 11:43
Josef Kufner | skóre: 70
15.10.2006 11:43
Josef Kufner | skóre: 70
 11.10.2006 06:07
David Watzke | skóre: 74
| blog: Blog...
| Praha
11.10.2006 06:07
David Watzke | skóre: 74
| blog: Blog...
| Praha
/*C*/ strcat(c, a); strcat(c, b);tohle:
/*C*/ strcpy(c, a); strcat(c, b);? Sice to funguje stejně, ale k čemu by pak bylo
strcpy, kdyby to ani nebylo zapotřebí?
. Ale díky za upozornění.
*c == '\0'v opacnom pripade sa a prilepi za prvu '\0' v c, co by mohol byt celkom problem (pretecenie).
strcpy kopiruje vzdy na zadanu adresu ako prvy parameter (to len na doplnenie).
1. V tom je ovšem mezi strcpy() a strcat() obrovský rozdíl, že? :-)
2. To, co jste napsal, dělá úplně něco jiného, než jste chtěl.
3. Kdybyste použil strlen() místo sizeof() (což jste patrně měl na mysli), bude vaše konstrukce dělat přesně totéž co strcpy(c,a)
strcpy implementovali nějak takto
while (*a++ = *b++);
while( *b++ != '\0' )
{
*a++ = *b++;
}
je to jenom pro ilustraci bude to napsane urcite lepe
Ale skončil, je to zcela korektní implementace strcpy(), na rozdíl od té vaší, která kopíruje jen každý druhý znak a i když se náhodou trefí do koncové značky, stejně ji nezkopíruje.
Měl byste si nastudovat aspoň základy, všechno, co jste sem zatím napsal, bylo úplně špatně. Idiom
while (*s++ = *t++);
je už v Kernighanovi a Ritchiem…
Ostatně, dynamické jazyky operátory přetypování nenabízejí. Tedy pokud za ně nepovažujeme konverzní funkce, třeba pro převod z čísla na řetězec.Obecně mi není jasné, proč by přetypování nemělo mít u dynamických jazyků smysl (když se podle typu řídí např. výběr metody). Pokud by na přetypování někdo trval, tak change-class v CL existuje, ale je fakt, že to může být chápáno jako na pomezí konverze a přetypování.


 11.10.2006 12:54
ava | skóre: 10
11.10.2006 12:54
ava | skóre: 10

 11.2.2010 19:51
Mintaka | skóre: 13
11.2.2010 19:51
Mintaka | skóre: 13
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz