Jack Dorsey představil (𝕏) open source týmovou komunikační platformu Buzz (GitHub) s cílem snížit závislost na Slacku a GitHubu.
Poštovní klient Thunderbird byl vydán v nové verzi 153 s kódovým názvem Meadow. Jedná se o ESR (Extended Support Release) vydání. Přehled novinek v poznámkách k vydání. Vylepšuje OAuth. Thundermail lze používat bez instalace doplňku.
AI tento rok naplno vtrhla do vývoje softwaru a výrazně ovlivňuje také open source projekty. Jiří Eischmann v příspěvku Jak mění AI open source na svém blogu rozebírá několik trendů, které v open source v poslední době v souvislosti s AI pozoruje, a jak tyto trendy svět otevřeného softwaru mění (Inflace projektů, Zahlcení kontroly, Klesající motivace zveřejňovat kód).
Evropská komise (EK) vyměřila americké internetové společnosti Google pokutu 890 milionů eur (21,5 miliardy Kč) za porušení unijního nařízení o digitálních trzích (DMA). Firma se podle unijní exekutivy provinila tím, že ve vyhledávači Google Search upřednostňovala vlastní služby a že podnikům ukládala omezení, která jim bránila nasměrovat spotřebitele k alternativním, často levnějším nákupním kanálům na platformě Google Play.
… více »Samsung na akci Galaxy Unpacked July 2026 (YouTube) představil své nové telefony Galaxy Z Fold8 Ultra, Fold8 a Flip8, hodinky Galaxy Watch Ultra2 a Watch9 a chytré brýle ve spolupráci s Gentle Monster a Warby Parker.
Po pěti letech vývoje vyšla česká počítačová hra Scarlet Deer Inn (ProtonDB). Scarlet Deer Inn je vyšívaná temná středověká pohádka. Zatímco život ve zdánlivě obyčejné vesnici se točí kolem běžných povinností a sousedských drbů, v podzemí se skrývají zlověstná tajemství.
Představen byl Raspberry Pi Touch Display 2 s uhlopříčkou 10 palců a rozlišením 1200 × 1920 pixelů. Cena je 80 dolarů.
RPCS3 (Wikipedie), tj. open source emulátor Sony PlayStation 3, snížil minimální požadavky. Nově jsou podporovány starší grafické karty ATI Radeon řady HD 2000, 3000 a 4000 z let 2007 až 2009. Na PC běží už 75 % všech her pro PlayStation 3. V budoucnu bude RPCS3 fungovat bez firmwaru z PS3. V RPCS3 byl implementován systémový modul cellSysmodule (𝕏).
Vyšel open-source nástroj winetop (MIT) — nativní CLI/TUI pro sledování a ukončování Wine, Proton, Lutris, Heroic a Bottles sezení. Seskupuje procesy podle WINEPREFIX / Steam AppId, umí bezpečně zabít jen hru (včetně Steam reaperu) a nabízí i skriptovatelné příkazy (list, kill, orphans, …). Balíčky jsou mimo jiné na crates.io, Copru (dnf copr enable kovariadam/winetop), PPA ppa:kovariadam/winetop a AUR (winetop-bin).
Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.

Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Diskuse byla administrátory uzamčena
 Navíc se můžeš chytnout nějakého redakčního systému, třeba Drupalu, a stavět na něm. Napsat nějaké malé rozšíření je snažší, než stavět celou aplikaci na zelené louce. A hlavně to bude už od začátku něco dělat.
Navíc se můžeš chytnout nějakého redakčního systému, třeba Drupalu, a stavět na něm. Napsat nějaké malé rozšíření je snažší, než stavět celou aplikaci na zelené louce. A hlavně to bude už od začátku něco dělat.
Webu a PHP se drž. Je to jednodušší, je poptávka a lidi jsou zvyklí na nízkou kvalitu kóduSpíš než PHP bych mu doporučil node.js a react. Není toho zas tak moc, co se musí naučit a lidi mu utrhají ruce (už asi čtvrt roku hledáme JS programátora a prostě nejsou).
Spíš než PHP bych mu doporučil node.js a react.Uhh. Prostředí Node.js je imho dost nepřívětivé. Callback hell a tak. Třeba Python + Flask mi přijde mnohonásobně příjemnější...
Python a flask ale neni web scale.Z čeho tak usuzuješ? Ne, že bych nevěřil, ale stejně by mě zajímaly nějaký podklady... Třeba s PyPy/gevent bych čekal, že by to jít mohlo... Když vezmu v úvahu, co dokázal fujsbuk vymlátit z přiblblého PHP...
Uhh. Prostředí Node.js je imho dost nepřívětivé. Callback hell a tak. Třeba Python + Flask mi přijde mnohonásobně příjemnější...Souhlasím. Co se mě týče, tak to vnímám stejně (až na ten flask, preferuji bottle). Šéf má ale docela pochopitelné námitky, co se týče jednotnosti backendu webu a frontendu (=stačí ti jeden programátor co zná dobře JS). Pak taky ty různé vymoženosti, jako třeba automatické validace dat na obou stranách jedním kódem, živý transport dat z backendu na frontend a různé další vymoženosti. V pátek u nás byl „školit“ člověk, co stojí za este a měl docela dobré pointy proč použít JS na obou stranách.
docela dobré pointy proč použít JS na obou stranách
Čo konkrétne?
O tej validácii som to čítal veľa krát. Pekne sa to počúva, ale v praxi najčastejšie potrebujem validovať:
Z toho na čo som si spomenul by som zdieľal kód len v jednom prípade.
Ja som na túto dvojitú validáciu rezignoval ;) V posledných projektoch všade kopírujem svoju dirty implementáciu ktorá počas vypĺňania formulára posiela serializovaný formulár na server a dostáva naspäť výsledok validácie, takže na klientovi mám minimum kódu. Aktuálne sa to snažím izolovať, učesať a zverejniť na githube ako django app.
Mluvíš o Bean Validation nebo o Vaadinu?Vaadin, příp. GWT...
Zrovna i ten Raphael tam někdo napojil – JustGage.To je jen nějaká komponenta napsaná pomocí Raphel... Můj případ byla SPA aplikace pracující s Cytoscape (různě do něj sype data, mění, atd.), což zahrnovalo také rozšíření do Cytoscape - renderer používající Raphael a vlastní layout engine. Aplikace od serveru požadovala pouze vhodné REST API. Uvádim to jako příklad, kdy použití jedné technologie na serveru i klientu nepomůže, resp. není vlastně ani možné.
IMHO by to měl management pojmout tak, že potřeba dalšího jazyka není pro nové zaměstnance nevýhoda, ale naopak výhoda - "Naučíme tě Python, to je pro tebe dobré".Tak teoreticky. V praxi není nikdo na python, ani na javascript, ani s ochotou se učit nový jazyk. Už jsme zkoušeli lovit na vysokých školách, s tím že ten člověk nemusí umět skoro nic, jen naprosté základy a zbytek se/ho nějak doučí(me) a stejně nic. Spíš bych řekl, že když lidi slyší, že se budou muset naučit něco nového, tak nejsou nadšení. Za dva měsíce se nám ozvali tři lidi. Jeden byl vyhořelý učitel programování, který měl na githubu ukázky kódu, ze kterých bylo jasné, že vůbec nechápe, o co jde a sám si sjíždí základní tutoriály. Kdyby nebyl z druhé strany republiky, nebo se chtěl přestěhovat, tak by ale stejně dostal šanci*. Druhý poslal kód zjevně slepený z stackoverflow, kde jsou namíchané anglické a české názvy a v 120 řádkách to má podle linteru 180 chyb a ještě k tomu nejde spustit (doslova nejhorší kód, co jsem kdy viděl). Třetího studenta ze Slovenska jsme vzali na poloviční úvazek (to chtěl on, jde studovat v Praze VŠ). Já z toho mám tak nějak zmixované pocity. Na jednu stranu jsem docela rád, protože to zvyšuje mojí cenu na trhu práce, na druhou stranu mi přijde dost zvláštní to takhle vidět. Výhoda asi je, že v příští práci si budu moct víc diktovat a taky budu brát jen větší libůstky a nepřijde mi, že na to nemám, když jsem teď viděl situaci na vlastní oči. *Kdyby uměl programovat, tak by asi nebyl ani problém pracovat z domova, ale učit někoho na dálku základy, to fakt ne.
Už tě vykopli, jo?Ne, časem se to stalo moc lehké a rutinní a už mě to nebavilo.
Nechci ti kazit radost, ale co umis tak exkluzivniho, ze si tak veris? Python, ok, a dal?Celá moje pointa byla, že na současném trhu práce je tak masivní poptávka, že si můžu říct o víc, i když mám pocit, že třeba nic víc neumím. Zkušenosti mi totiž ukázaly, že zatím všichni, koho jsem potkal jsou na tom podstatně hůř a říkají si o víc.

až na ten flask, preferuji bottleZe zvědavosti: V čem je bottle lepší? (bottle neznám)
Šéf má ale docela pochopitelné námitky, co se týče jednotnosti backendu webu a frontendu (=stačí ti jeden programátor co zná dobře JS).To muze byt vyhoda u velmi jednoduchych aplikaci, ale tim to tak konci. Nejvic me fascinuje myslenkovy pochod "budeme mit JS na backendu, takze nam backend budou moct psat i frontendisti". Frontend/backend jsou uplne jine skillsety, ktere zasahuji daleko dal nez jen vcelku jednoduse naucitelny programovaci jazyk.
To pravé peklo ale teprve začíná: interakce s uživatelem. Až dosud si člověk vystačil jen s logikou, občas trochou matematiky a pěknou dávkou inženýrského citu. Jakmile se do toho začne motat uživatel, je potřeba psychologie. Obory jako je UX v podstatě nejsou nic jiného než aplikovaná psychologie. Pak je potřeba nějakých těch soft-skills, aby jeden z uživatele zjistil nejen co chce, ale hlavně to, co opravdu potřebuje.+1, skvěle napsáno
To pravé peklo ale teprve začíná: interakce s uživatelem. Až dosud si člověk vystačil jen s logikou, občas trochou matematiky a pěknou dávkou inženýrského citu.Já mám teda problém už o level níž, prostě jak navrhnout architekturu toho programu (a vůbec to nesouvisí s uživatelem, může to být něco, co běží samo nebo komunikuje přes CLI rozhraní s nerdy, kteří UX neřeší).
Být Jendou nedělám si s tím hlavu a jdu na to intuitivněNj, jenže pak vznikají zprasky jako kukuruku-gui, což je zjevně blbě, ale nevím, jak se to dělá správně.
Jasně, že to pak člověk často používá, aniž by věděl, jak přesně se to jmenuje, ale důležité, že někde v podvědomí to má a při řešení problému ho vhodný vzor napadne.No jo, ale jak víš, který vzor je vhodný? To je právě ono. To je něco, co víš pouze díky zkušenosti programátora.
 Na jednu stranu to všechny jazyky už 40 let umí přirozeně, na druhou stranu mi výrok "já volání subrutiny nikdy nepotřebuju použít" přijde takový...
Na jednu stranu to všechny jazyky už 40 let umí přirozeně, na druhou stranu mi výrok "já volání subrutiny nikdy nepotřebuju použít" přijde takový...
Však ono to taky okolo Javy vzniklo a v ostatních jazycích spousta z toho není vůbec potřeba, protože to prostě jazyk zvládne tak nějak přirozeně.Priklad?
design pattern predani funkce parametrem?Předání funkce parametrem se běžně používá při implementaci několika různých patternů, především pak callback (ten je myslím nortoricky známý, nebo snad někdo opravdu prohlásí že "v mém jazyce callback nemáme"?), visitor (ten už je docela kontroverzní, existuje spousta variant), ale například i lazy-loading/cache (abych jmenoval něco neobvyklého).
Callback je pattern? Lazy-loading a cache jsou patterny? ROFL! Existuje něco, co není pattern?Pokud je to pojem který lidé potřebují nějak mentálně zpracovat a sdělit jiným lidem...
Je hezké mít potvrzeno, že "design pattern" je slovní vata prosta jakéhokoli významu...Pojem "callback" pro tebe nemá význam? Ani "lazy-loading" nemá význam? Zamyslel zes nad tím než jsi to napsal? Samozřejmě, naprostá většina lidské komunikace se dá označit jako "slovní vata". Bohužel, stále ještě se nepodařilo tyto výtvory miliónu let náhodné evoluce odstranit...
Pojem "callback" pro tebe nemá význam? Ani "lazy-loading" nemá význam?Mají pro mě význam, pochopitelně. Co IMHO postrádá význam je označit je za "design pattern". To je asi jako kdybys všechno, co děláš, označil za "life pattern". Přátelům bys pak neřekl "Heleďte, co kdybychom šli do kina?", nýbrž "Heleďte, co kdybychom použili life pattern visitor na objek kino?".
Kdyz chci reagovat treba na udalosti v GUI, muzu pouzit listenery, nebo nekde ve smycce pollovat udalosti. A pak se daji vymyslet desitky dalsich variant, ktere jsou ale v principu stejne (treba volat konkretni funkce/metody, ktere si uzivatel pripadne predefinuje - to je v podstate ale jen jiny zpusob registrace listeneru).Design pattern vnimam jako standardizovane reseni neceho. Kdyz chces nekomu rict, jak ma udelat obsluhu v GUI, muzes pouzit vyraz "event-driven programming", popr. "pouzit listenery", nebo tak neco. A nebo se vyjadris vice slovy: "pro kazdou udalost si zaregistrujes funkci, ktera se pak zavola". Pattern prece znamena jen vzor. Vzor je neco, co se repetitivne objevuje. Tady je jeste privlastek navrhovy, coz znamena, ze to ovlivnuje strukturu/rozvrzeni aplikace - alespon u tech ryze programatorskych design patternu, coz tyhle jsou. Oznacuje to veci, nad kterymi by zacinajici programator potencialne mohl delsi dobu premyslet a zvazovat, jak je vyresit, zatimco s trochou zkusenosti to automaticky udelas spravne bez dlouheho vahani. Je celkem jedno, jestli si to precetl v nejake knizce, videl to v kodu zkusenejsiho kolegy, nebo na to sam prisel casem. Podstatne je, ze je to v principu stejne reseni. Stejne tak prece existujou anti-patterny. Jak bys to oznacil jinak nez jako strukturalni chyby v kodu, kterych se lidi casto dopousti? Napr. masove pouzivani globalnich promennych lze oznacit za anti-pattern. Je celkem jedno, v cem je to psane. Pak muzes mit anti-patterny, ktere lze povazovat za anti-patterny jen v ramci konkretniho paradigmatu (naduzivani statickych metod v OOP) apod. Neprijde mi dulezite prit se o presnou definici konkretnich design patternu, protoze ta by vzdy byla velmi sporna. Dulezite je mit o nich poneti a umet si nejake bezne pouzivane jmeno asociovat s vyslednou strukturou toho kodu. Vedet, ze existuji ruzne pristupy, a zvolit ten spravny. Jestli to pojmenujes tak, ci onak, a prit se o to, ktere slovo pouzijes, je oblibene mozna tak na strednich skolach, ale v praxi je to jen bullshitareni.
interface ChangeListener {
void onChange(long t);
}
static void process(ChangeListener changeListener) {
// ...
changeListener.onChange(System.currentTimeMillis());
}
process(System.out::println);
Pokud budes potrebovat zapsat slozitejsi logiku a zapis pomoci jedne metody (at uz lambdy, nebo reference na metodu) prestane stacit, vzdy to muzes presunout do samostatne tridy (a mit v ni libovolne mnozstvi pomocnych metod apod.). Klidne muzes mit tridu, ktera implementuje vic ruznych rozhrani, a pouzivat jednu jeji instanci ve vice ruznych pripadech (coz v oduvodnenych pripadech muze davat smysl).
V Jave zpravidla nelze psat takovym tim "hackerskym" zpusobem - velmi strucny kod, ktery je radost zkoumat. Slovo zkoumat zduraznuji, protoze informace, ktere mohou byt v Jave zcela zjevne, v jinych jazycich byt zjevne nemusi. Mam-li se rozhodovat mezi jazykem, ktery ti umozni cast podstatnych informaci zamlcet (ale presto se vetsina dobrych vyvojaru shoduje, ze je lepsi, aby byly v kodu explicitne uvedene), nebo jazykem, ktery to striktne vyzaduje, volim tu druhou variantu (s vyjimkou drobnych projektu, kde z vice duvodu zpravidla preferuji Python).
.PROCESS:
; ...
call eax
ret
.PRINT:
; ...
ret
mov eax, .PRINT
call .PROCESS
... a je to porad stejny design pattern.
... a je to porad stejny design pattern.Function pointer mi teda rozhodně nepřipadá jako to samé, jako interface v Javě. V jazycích jako C++, D, Rust apod. bude těch možností ještě víc, např. jestli to udělat přes static nebo dynamic dispatch, jakým způsobem, atd. V Pythonu a JS zase budou jiné možnosti (v JS by to třeba mohl být nějaký event, to je tam oblíbené). Ano, je to sice stále "to samé", ale pouze ze zcela obecného hlediska. To pak má ten design pattern natolik vágní definici, že je otázka, k čemu vlastně je. Co to vlastně má být za pattern?
String, protože obsahuje i nuly na začátku případně pomlčky, kdežto ID je Long).int odečti(int a, int b);Poznáš z předpisu funkce zda vrátí
a - b, nebo b - a ? (Samozřejmě je to modelový triviální příklad a obvykle dost pomůžou slušné názvy, ale …)
Však taky o tom generování z komentářů píšu. Nikde netvrdím, že se má udržovat nějak bokem, naopak.V tom případě OK. Význam napíšu do komentáře (panř.
@param a bla bla bla). Taky bych do komentáře mohl psát, zda je to číslo, text, datum… ale proč bych to dělal, když to můžu vyjádřit strojově čitelnou formou, které rozumí IDE, kompilátor a další nástroje a kterou každý programátor snadno přečte?
V čem je výhoda nedeklarovat typ? Nějaký příklad by najít šel, ale budou to okrajové případy – daleko častěji to podle mého vede k chybám a zmatkům. Viz třeba ty spousty SQL injection v PHP aplikacích – kolikrát si už jen programátor řekl: „$id je přece číslo, to můžu bezpečně připojit k SELECTu“? A pak mu tam ale nepřišlo číslo, ale třeba "0 OR 1=1". Kdyby to byl datový typ int, tak i kdyby udělal tu prasárnu s lepením SELECTu, tak je to bezpečné. Nebo ta záměna čísla účtu za ID účtu… to jsou reálné příklady.
Poznáš z předpisu funkce zda vrátí a - b, nebo b - a ?Udělal bych metodu
int sečti(int a, int b) a nebylo by potřeba to komentovat
Nebo spíš int sečti(int... hodnoty).
Význam napíšu do komentáře (panř. @param a bla bla bla).No a jsme u té dokumentace.
Taky bych do komentáře mohl psát, zda je to číslo, text, datum… ale proč bych to dělal, když to můžu vyjádřit strojově čitelnou formou, které rozumí IDE, kompilátor a další nástroje a kterou každý programátor snadno přečte?Však to také ten generátor dokumentace použije.
V čem je výhoda nedeklarovat typ? ...O tom vůbec nemluvím.
Zrovna v tom Javascriptu to bude vypadat dosti odlišně než jak jsi to napsal v Jave výše. Žádný listener se v JS totiž vůbec neřeší a prostě se předá funkce (callback), který se má v očekávaný okamžik zavolat. Tedy namísto komplikovaného UML diagramu a několika tříd a interfaců design patternu tam je jeden parametr funkce. Netvrdím, že to pak není ten samý návrhový vzor – tvrdím, že se díky výřečnosti jazyka ten vzor smrskne na trivialitu.To mi právě triviální nepřijde, protože v té Javě díky rozhraní posluchače víš, co bude na vstupu, IDE ti napoví, jak např. zjistíš, kterým tlačítkem uživatel kliknul nebo jakou klávesu stiskl. A v Javě 8 předáš taky jen tu funkci, odpadne ten zbytečný kód, ale typovost a dokumentace zůstává zachována (v pozadí jsou pořád ta rozhraní a jasně daným popisem metod, parametrů, návratových hodnot). „Zjednodušit“ něco vynecháním podstatné informace je jen zdánlivé zjednodušení.
protože v té Javě díky rozhraní posluchače víš, co bude na vstupuFWIW tohle platí pro jakýkoli staticky typovaný jazyk.
„Zjednodušit“ něco vynecháním podstatné informace je jen zdánlivé zjednodušení.Není to lepší/horší jednodušší/složitější, prostě je to jiný přístup. Jednodušší je to v tom, že můžeš snadno prototypovat, snadno měnit kód. Ve chvíli, kdy se ti změní trochu ten callback (třeba přibude parametr), nemusíš všade měnit signatury té lambdy/funkce/interfacu/whatever. Složitější je to v tom, že si musíš dát větší pozor, aby tam přišla správná věc. Prostě každý ten přístup má své pro/proti a každý je vhodný na něco jiného.
FWIW tohle platí pro jakýkoli staticky typovaný jazyk.Presne tak. Proto jsem uz ostatne v teto diskuzi zminoval, at se nebavime vyhradne o Jave, ale obecne o staticky typovanych jazycich. Boilerplate kod v Jave se v dusledku urcite neohrabanosti obcas skutecne objevuje, ale moc to nesouvisi s typovanim. Mluvim ted zejmena o JavaBeans a nutnosti psat settery/gettery, hashCode, equals apod. Lze to generovat v IDE, ale obcas je neprijemne to cist - equals ani hashCode nejsou na prvni pohled zcela trivialni (jako settery a gettery) a neni tedy zrejme, zda se v nich neukryva nejaka zrada. Resenim muze byt pouziti nejakeho frameworku, ktery to dela na pozadi a pouze dava uzivateli moznost ty metody v pripade potreby pretizit, ale osobni zkusenost s tim nemam (a trochu bych se bal toho, ze to cloveku podrazi nohy ve chvili, kdy to nejmene ceka). Dale obcas zlobi vyjimky. Checked vyjimky je potreba pouzivat s rozumem. C# to vyresil jejich uplnym zrusenim, na coz jsem v prvni chvili reagoval negativne, ale postupem casu o tomto nazoru zacinam pochybovat. Na druhou stranu se s checked vyjimkami setkavam prakticky jen u I/O a reflexe. Dale obcas vznika hnusny kod pri obalovani vyjimek. Klasicky pattern:
void foo() {
try {
// ...
} catch (FooException e) {
throw new BarException(e);
}
}
Kdysi jsem zvazoval, ze by mohl byt hezci nejaky syntakticky cukr jako:
void foo() rethrows FooException:BarException {
// ...
}
Tezko rict, co je lepsi. Druhy pristup by zase vedl k problemum s formatovanim u metod s delsi signaturou. Druha vec je, jak casto je potreba neco takoveho vubec delat.
Prostě každý ten přístup má své pro/proti a každý je vhodný na něco jiného.Souhlasim.
Resenim muze byt pouziti nejakeho frameworku, ktery to dela na pozadi a pouze dava uzivateli moznost ty metody v pripade potreby pretizit, ale osobni zkusenost s tim nemam (a trochu bych se bal toho, ze to cloveku podrazi nohy ve chvili, kdy to nejmene ceka).Mám zkušenost s Lombokem. Je to trochu hack, ale funguje to dobře a ušetří to spoustu řádků, zpřehlední to kód. Šel jsem do toho s tím, že v případě problémů jde z projektu Lombok snadno vykopat a mít zase jen klasickou Javu. Po cca roce, co to na projektu používáme, můžu říct, že se Lombok osvědčil a nebyl důvod se ho zbavovat.
Proč? Nikdy jsem netvrdil, že Java je dokonalá. Jedna z věcí, co by šly vylepšit jsou třeba ty vlastnosti tříd (property), které by nahradily jmennou konvenci (gettery a settery).To mi přijde jako celkem detail, IMHO limitace/negativa Javy jsou v podstatě hlavně limitace JVM. Jako např. výše zmíněné primitivní typy, žravé objekty, atd... Lombok vypadá jako fajn věc, nicméně nabízí se otázka, proč už pak rovnou nepoužít jiný jazyk kompatibilní s Javou/JVM...
@Data nebo @Getter a @Setter pochopí každý hned. A i kdyby to nepochopil a psal to klasicky, tak to ničemu nevadí. A kód, který tyhle třídy používá ani neví, že tam nějaký Lombok je (vidí ty gettery a settery, stejně jako je vidí programátor v IDE).
Taky je užitečná anotace @Log.
Kdysi jsem zvazoval, ze by mohl byt hezci nejaky syntakticky cukr jako:To jsem si taky říkal, ale pak jsem došel k tomu, že by bylo lepší mít v jazyce obecný systém (hygienických) maker, které umožní komukoli dělat cokoli – ne jen pár předem daných případů syntaktického cukru, které napadly autory jazyka. Akorát by ten jazyk pak měl trochu jinou cílovou skupinu než Java, protože už by byl náročnější na disciplínu a schopnosti.
Dale obcas zlobi vyjimky. Checked vyjimky je potreba pouzivat s rozumem.Že volání metody může selhat a jakým způsobem může selhat, to je pro mne stejně důležitá informace jako ta, jaký datový typ vrací (výjimka je vlastně alternativou k návratové hodnotě) nebo jaké má parametry. Nechci o takovou informaci přijít – nechci ji luštit někde z nestrukturované dokumentace, nebo z kódu uvnitř, nebo dokonce postupovat metodou pokus-omyl a řešit ty běhové výjimky, na které jsem při vývoji narazil (a doufat, že při produkčním nasazení tam nevyletí nějaká další nekontrolovaná výjimka).
Že volání metody může selhat a jakým způsobem může selhat, to je pro mne stejně důležitá informace jako ta, jaký datový typ vrací (výjimka je vlastně alternativou k návratové hodnotě) nebo jaké má parametry.Presne tak jsem nad tim take vzdy uvazoval a samozrejme s tim souhlasim. Tu vyjimku pak ale musis nekde osetrit a ted je otazka, kde to budes delat. Proto jsem psal, ze je potreba uzivat je s rozumem. Klasickym prikladem je pokus o otevreni neexistujiciho souboru. Vcelku dava smysl, ze je ta vyjimka checked. Pokusim se otevrit soubor a to se bud zdari (a ja muzu pokracovat), nebo nezdari. ale ja na to musim umet zareagovat. Zakladni princip by IMHO mel byt ten, ze se snazis chybu osetrit az ve skutecnem miste vzniku, abys udrzel strukturu aplikace rozumnou a rozpoznal skutecnou pricinu. Tzn. ze vyjimku predavas dal az do mista, kde ke chybe zrejme doslo. V pripade CLI aplikace, kde uzivatel zada jmeno souboru, ze ktereho se ma neco cist, by to znamenalo, ze vyjimku predavas az nekam do mainu, kde uzivateli vypises srozumitelnejsi chybovou hlasku. Potud OK. Druha strana mince jsou technicke chyby. Kdysi jsem cetl clanek o checked vs. unchecked vyjimkach (tusim, ze primo od lidi, co za tim v Jave stoji, ale to si ted nejsem jisty), kde bylo receno, ze checked vyjimky se maji pouzivat pro ocekavatelne chyby, ze kterych se program muze zotavit. U CLI aplikace je tohle jedno, ale u GUI aplikace uz ne - rozhodne by nemela spadnout cela jen kvuli tomu, ze se nekdo nekde uklepl. To porad dava smysl. Ted mas ale reflexi, kterou v drtive vetsine pripadu ridi programator, nikoliv uzivatel. Presto te jazyk nuti osetrovat treba pripad, kdy se pokusis vytvorit novou instanci, kdyz neni k dispozici patricny konstruktor apod. Jmenovite u reflexe je tech vyjimek opravdu hodne, ale na zadnou z nich nelze rozumne reagovat - pokud program potrebuje provest nejakou reflexivni akci, aby mohl spravne fungovat, tak jakakoliv takova vyjimka okamzite znamena pad aplikace. V praxi tedy vetsinu takovych chyb osetris zabalenim do RuntimeException a dalsim propagovanim jako unchecked vyjimky, protoze nedava smysl v cele hierarchii volani uvadet low-level technicke chyby, ale ani neexistuje zpusob, jak na tu chybu lepe reagovat ihned. Pokud by existoval zpusob, jak prehazovani vyjimek provadet snadno a citelne, byl bych pro checked vyjimky vsemi deseti. Za soucasneho stavu o tom ale nadale mam urcite pochybnosti (napr. kvuli uvedenemu failu v API u reflexe).
Nechci o takovou informaci přijít – nechci ji luštit někde z nestrukturované dokumentace, nebo z kódu uvnitř, nebo dokonce postupovat metodou pokus-omylOd kolegy jsem odkoukal uvadeni unchecked vyjimek do throws klauzule v signature metody. Jazyk to umoznuje a slouzi to pak vyhradne k dokumentacnim ucelum, ale je to zaroven snadno strojove zpracovatelne a docela prehledne. Mozna by nebylo spatne, kdyby neosetreni checked vyjimky nekoncilo chybou pri kompilaci, ale warningem, ktery lze pomoci neceho jako
@SurpressWarning potlacit. Bud by ses tedy rozhodl, ze vyjimku predas dal - a preneses zodpovednost na volajiciho - nebo se rozhodnes, ze takovou vyjimku odmitas dal resit a vynutis jeji potlaceni.
Že volání metody může selhat a jakým způsobem může selhat, to je pro mne stejně důležitá informace jako ta, jaký datový typ vrací (výjimka je vlastně alternativou k návratové hodnotě) nebo jaké má parametry.Checked exceptions skutečně dělají z výjimek spíš takovou alternativní návratovou hodnotu, protože se nedají v praxi probublat o moc víš. Celá pointa výjimek ale spočívá v tom, že ti může probublávat víceméně kamkoli, takže ty checked exceptions v podstatě jdou proti smyslu výjimek, což se nelíbí lidem od C++, C# apod, ale IMHO to není nutně špatně, třeba Rust se na výjimky vykašlal a řeší error handling přes vracení enumů (sum type / tagged union), což sice pod kaptou funguje jinak než výjimky, ale používá se to v podstatě dost stejně jako Javovské checked exceptions a to silné typování tam funguje v podstatě stejně (viz třeba otevření souboru). Osobně jsem přestal mít silný názor na způsoby error handlingu, vyzkoušel jsem všechny hlavní a IMHO každý má svoje problémy...
To jsem si taky říkal, ale pak jsem došel k tomu, že by bylo lepší mít v jazyce obecný systém (hygienických) maker, které umožní komukoli dělat cokoli – ne jen pár předem daných případů syntaktického cukru, které napadly autory jazyka.Další důvod zkusit Rust... (ačkoli ta makra nejsou až tak silná jako třeba v D nebo nedej bože v Lispu).
Nechci o takovou informaci přijít – nechci ji luštit někde z nestrukturované dokumentace, nebo z kódu uvnitř, nebo dokonce postupovat metodou pokus-omyl a řešit ty běhové výjimky, na které jsem při vývoji narazil (a doufat, že při produkčním nasazení tam nevyletí nějaká další nekontrolovaná výjimka).IMHO do té dokumentace musíš většinou stejně jít, protože potřebuješ vědět, za jakých okolností se výjimky (ne)vyvolají, s tím se nedá celkem nic dělat...
IMHO do té dokumentace musíš většinou stejně jít, protože potřebuješ vědět, za jakých okolností se výjimky (ne)vyvolají, s tím se nedá celkem nic dělat...Tady jde spíš dokumentace za tebou než že bys ty chodil za dokumentací – kontrolované výjimky tě IDE/kompilátor donutí ošetřit a když už ten
catch(… e){…}, tak si přečteš i ten JavaDoc nebo si to domyslíš i bez něj (víš, která metoda danou výjimku vyvolala, tzn. co selhalo a podle toho zobrazíš příslušnou chybovou hlášku, zaloguješ, obalíš a vyhodíš výš atd.). Prostě nejde na to zapomenout. Naopak u nekontrolovaných výjimek musíš ty aktivně pátrat potom, která metoda co vyhazuje a sám si dávat pozor, abys na něco nezapomněl.
java.net.URI, konstruktor je celkem jednoduchej: public URI(String str) throws URISyntaxException . Je hezké, že z toho poznáš, že ta funkce může vyhodit tenhle exception, blbý je, že pouze z této informace nemáš šajn, jaký URL akceptuje nebo ne, musíš se mrknout do dokumentace, která říká:
This constructor parses the given string exactly as specified by the grammar in RFC 2396, Appendix A, except for the following deviations:a následují nějaké komentáře. (FWIW, stejně jsem to musel nakonec doplnit o trochu vlastního parsování...). A ta RFC jsou mizerná...
Na ostatní věci příkazovou řádku - sestavování, VCS, atd. Co se debuggingu týče - gdb. Příkazová řádka je v tomhle IMHO dost nepřekonatelná. Případně používám nějaké lehkotonážní programy určené pro jednu konkrétní věc - třeba gitk apod. Zkoušel jsem DDD, ale nesedí mi. Je pravda, že třeba Qt Creator má velmi dobrý frontend pro GDB, ale zapínat kvůli tomu celý Qt Creator se mi nechce. Koukám teď, že v Gnome vytvořili progra Nemiver, to vypadá docela dobře, možná vyzkoušim.
Nicméně konzole je prostě konzole.
GUI debugger pouzivam tam, kde ma smyslTaky používám GUI debugger tam, kde to má pro mě smysl. Tedy momentálně nikde. :)
Že má něco, GUI ještě neznamená, že je to hloupé…Nepsal jsem o něčem, psal jsem o GUI. Tedy že GUI má GUI to je něco jako když děti mají děti? I když pardon, to se stává až moc často.
Ale spíš mi přijde zvláštní: to jsou obě strany toho síťového spojení tak neznámé a nezdokumentované, že nemůžeš jednu z nich simulovat a tu druhou v klidu krokovat?Vzhledem k tomu, že se mi dostávají do rukou libovolně obskurní bugy, není zajímavé se bavit o těch z nich, které jsou triviálně řešitelné. Navíc na to kolikrát nemám tolik času, abych nejdříve věnoval několik měsíců vývoji chybějících nástrojů na simulaci všech možných chyb. I když se zabývám i takovými věcmi, tady konkrétně se vyjadřuju k tomu, kdy je potřeba řešit chybu, která je teď a tady a mým cílem není vytvořit ideální testovací prostředí, ale maximálně do několika dní urvat takovou analýzu chyby, která vede k co nejlepší možnosti vyřešení a otestování. Odkaz na takový skript teď po ruce nemám. Ale pokud jde o gdb skripty, ty bývají velice jednoduché, maximálně na několik málo řádků. Na částečnou automatizaci se hodí i jednořádkový nebo párřádkový skript, kdy klidně stačí pomocí sekvence několika příkazů advance doskákat na místo, které chci analyzovat. Další automatizaci mi většinou zajišťuje shellovský skript o desítkách řádků, výjimečně pythoní skript. Jinak v klidu krokovat je blbost. Já potřebuju analyzovat každou verzi balíku, se kterou se potkám, každou změnu v kódu, to vše konzistentním a opakovatelným způsobem. Potřebuju postupně odstranit chyby v testování a potřebuju to být schopný zopakovat i v případě, že se mezitím třeba den věnuju něčemu úplně jinému. Jasně, můžu si někde bokem psát přesný postup a všechno opakovat třeba i stokrát ručně podle návodu. Ale proč bych to dělal, když ten návod můžu napsat pro shell a gdb a nechat celý proces proběhnout automatizovaně v několika vteřinách a ještě to poskytnout dalším k ověření mých výsledků a k návazným aktivitám jako je testování.
Jinak v klidu krokovat je blbost. Já potřebuju analyzovat každou verzi balíku, se kterou se potkám, každou změnu v kódu, to vše konzistentním a opakovatelným způsobem. Potřebuju postupně odstranit chyby v testování a potřebuju to být schopný zopakovat i v případě, že se mezitím třeba den věnuju něčemu úplně jinému.To je ten use-case, na ktery jsem se ptal. Automatizace je v tomto pripade dobra volba.
) používám na nativní jazyky (C/C++/Rust). Na Javu jdb, ale popravdě už jsem ho dlouho nepoužil, poslední věci v Javě jsem dělal hlavně pro Android v aplikaci, která hodně používala logging.
Ty vlastnosti ale davaji prostor existenci tech IDE a dalsich nastroju, diky cemuz se vyplati v Jave vyvijet.Z mého pohledu - nevyplatí. Ano, IDE poskytuje určité pohodlí a všelijaké užitečné nástroje, ale zároveň se tím člověk stává tak trochu otrokem toho daného IDE - je zásivlý na tom, aby mu IDE vytvořilo/nastavilo strukturu projektu, vygenerovalo konfiguraci build systému, dohledávalo věci v kódu, staralo se o VCS atd. atd. a lidi pak ani neví, jak fungují build systémy, neumí pracovat s VCS, apod. Pro Javu jsou IDE v tomhle ohledu extra nebezpečná, protože Java už tak je dosti uzavřený svět a Java-only vývojáři pak vůbec nemají šajn o světě mimo Javu. Přitom IDE typicky oproti dedikovaným nástrojům neposkytuje dohromady žádnou funkcionalitu navíc, koneckonců IDE často přímo používají tyto nástroje (build systémy, VCS, debuggery,...) jako backend, případně jejich funkcionalitu viceméně duplikují. Např. na ten debugging mi přijdou IDE dost nezajímavá, protože oproti nástrojům jako gdb dohromady nenabízejí nic navíc, pouze jiné rozhraní, jehož znalost je mnohem méně přenositelná než znalost gdb. Četl jsem, že gdb se dá připojit do IDA - to už je něco, co zní zajímavě, protože IDA, coby dedikovaný debugger, je oproti IDE schopno poskytnout věci navíc. Dělá jednu věc a dělá ji dobře (UNIXová filosofie), narozdíl od IDE. To je samozřejmě pouze můj pohled. YMMV.
je zásivlý na tom, aby mu IDE vytvořilo/nastavilo strukturu projektu, vygenerovalo konfiguraci build systému, dohledávalo věci v kódu, staralo se o VCS atd. atd. a lidi pak ani neví, jak fungují build systémy, neumí pracovat s VCS, apod.Projekt si muzes zalozit jakymkoliv zpusobem, napr. jej vygenerovat v konzoli z Maven archetypu a doladit rucne. Pote jej naimportujes do IDE, cimz se zalozi patricne pomocne soubory (ktere lze pripadne vygenerovat kdykoliv znovu, zadny specialni vyznam nemaji a nemusi byt ani commitnute, tj. mohou byt v
.gitignore).
VCS s IDE vubec nesouvisi a lze jej spravovat rucne ve vsech 3 hlavnich Java IDE, tzn. Eclipse, NetBeans i IntelliJ. IDE ti dava moznost prohlizet historii v prostredi, na ktere jsi zvykly, ale neni to nutne. Osobne pouzivam primarne terminal, gitk a git-cola. Je to stejne prirozene jako pri pouzivani bezneho editoru, tj. zadne hacky to nevyzaduje.
Přitom IDE typicky oproti dedikovaným nástrojům neposkytuje dohromady žádnou funkcionalitu navíc, koneckonců IDE často přímo používají tyto nástroje (build systémy, VCS, debuggery,...) jako backend, případně jejich funkcionalitu viceméně duplikují.IDE ti naseptava pri psani kodu, umoznuje ti snadno delat refactoringy (vc. treba doplneni argumentu metody a automaticke pouziti vychozi hodnoty u vsech volani), organizovat importy, upozornovat na nepouzite metody ci fieldy, vyhledavat pouziti, zobrazovat hierarchii trid i spoustet program, nebo konkretni testy.
Např. na ten debugging mi přijdou IDE dost nezajímavá, protože oproti nástrojům jako gdb dohromady nenabízejí nic navíc, pouze jiné rozhraní, jehož znalost je mnohem méně přenositelná než znalost gdb.Muzu spustit kod, krokovat ho, rucne vyhodnocovat snippety kodu (ktere se zkompiluji a vyhodnoti) apod. Pak existuje tzv. hot swapping, ktery umoznuje modifikovat kod bezici aplikace a promitat do ni zmeny. Pri tom vsem pozorujes kod v editoru a pouzivas tedy stale stejne rozhrani. Delat cokoliv z toho rucne nemuze byt rychlejsi nez zmacknout klavesovou zkratku v IDE.
Projekt si muzes zalozit jakymkoliv zpusobem, napr. jej vygenerovat v konzoli ...
VCS s IDE vubec nesouvisi a lze jej spravovat rucne ve vsech 3 hlavnich Java IDE, tzn. Eclipse, NetBeans i IntelliJ. IDE ti dava moznost prohlizet historii v prostredi, na ktere jsi zvykly, ale neni to nutne. Osobne pouzivam primarne terminal, gitk a git-cola.Přesně takhle nějak probíhal můj přechod IDE → editor, čím dál víc věcí jsem přesunul do konzole až zbyl z IDE jen ten editor...
IDE ti naseptava pri psani kodu, umoznuje ti snadno delat refactoringy (vc. treba doplneni argumentu metody a automaticke pouziti vychozi hodnoty u vsech volani), organizovat importy, upozornovat na nepouzite metody ci fieldy, vyhledavat pouziti, zobrazovat hierarchii trid i spoustet program, nebo konkretni testy.Vím o tom, také jsem IDE dřív používal. Lidé mají pocit, že nemůžou žít bez našeptávání kódu, že to je nepostradatelná fíčura. Není to pravda. Používám skoro na všechno Sublime, který kódu nerozumí, ale je schopen napovídat opakující se výrazy, což pokryje nějakých 85% use cases. Refactoring dělám pomocí vyhledávání a vícenásobných kurzorů, ve většině případů to je stejně silné jako IDE, které rozumí jazyku, v mnoha případech i silnější, zejména třeba na formátování kódu. Otevírání souborů a přepínání projektů zvládá Sublime rychleji než IDE, protože se nemusí zbývat všemi těmi kravinami, které řeší IDE. Přepnout projekt i se všemi otevřenými soubory je v Sublime v podsatě okamžité. VIM a Emacs jsou v tomhle podobně silné svými mechanismy. Doplňování argumentů metod mě absolutně netankuje, ditto importy, u kterých se mi mimochodem stávalo, že je IDE zmršilo. Upozorňování na nepoužité proměnné, funkce, struktury/třídy atd. zvládá mnohem lépe kompilátor - tohle je jedna z věcí, která mě u IDE vysírala - upozorňuje na tyhle chyby v kódu, který teprve píšu. Je z toho pak šum. Na vyhledávání v kódu používám grep, cscope, případně třeba v práci na to máme externí tooly bežící na serveru k tomu určeném - je na něm k dispozici veškerý kód, kterého je hodně - jsou tam i veškeré závislosti vč 3rd party. Výhoda tohoto řešení je, že člověk může snadno posílat odkazy ostatním. A to přitom já jsem ještě na tohle dost pohodlnej, znám lidi, který používají v podstatě holý ViM jen s nějakou základní konfigurací a zcela bez napovídání a čeho všeho a jsou to velice schopní a produktivní programátoři. Navíc ty stále celou dobu mluvíš pouze o Javě - dost z toho, co popisuješ, funguje rozumně jen do té doby, dokud se držíš striktně pouze Javy, třeba ten hot swapping a podobně.
Delat cokoliv z toho rucne nemuze byt rychlejsi nez zmacknout klavesovou zkratku v IDE.Jak se liší klávesová zkratka v IDE od klávesové zkratky nebo příkazu v debuggeru? gdb při stisku enteru opakuje předchozí příkaz, takže když třeba stepuju, stačí mačkat enter. V konzoli člověk může mít taky klávesové zkratky, mám třeba klávesovou zkratku na gitk (Ctrl+G).
není zdaleka tak jednoznačné, že tyhle fíčury IDE, které popisuješ, vyváží nevýhody IDE (z mého osobního pohledu ne)Jako spotřeba RAM? Ano, taky mi to přijde dost (i když dneska pitomý WWW prohlížeč žere často víc), ale když uvážím, kolik stojí RAM a kolik stojí můj čas – IDE, které rozumí kódu, je jasná volba.
Pokud říkáš, že kdo nepoužívá IDE nemůže efektivně programovat v Javě, tak s tím silně nesouhlasim.Asi dvakrát jsem narazil na kolegy, kteří se snažili dělat ve VIMu – teoreticky jim v tom nic nebránilo a nikdo je nenutil používat IDE, překládat to šlo z příkazové řádky Antem nebo Mavenem úplně bez problému. Nikoho nezajímalo, v čem to píšeš, ale co odevzdáš do SVN/Gitu. Ale práce jim moc od ruky nešla a často jim unikal kontext – to, co i průměrný programátor s IDE vidí na první pohled, oni neviděli, protože byli zahrabaní v nějakém jednom souboru. Nakonec se na to vykašlali a přešli na Netbeans nebo Eclipse. Neříkám, že efektivní programátor v Javě bez IDE nemůže existovat, ale zatím jsem takového neviděl – až na něj narazíš, tak bych ho rád poznal a chvíli pozoroval při práci.
Neříkám, že efektivní programátor v Javě bez IDE nemůže existovat, ale zatím jsem takového neviděl – až na něj narazíš, tak bych ho rád poznal a chvíli pozoroval při práci.Hm, v našem týmu v práci afaik nikdo IDE nepoužívá, tam se to dělí na ViMisty a Emacsisty a já jsem tam ta černá ovce se Sublime
Ale té Javy tam není až tak moc, tak nevim, jak moc je to relevantní...
Hlavně mi to ale není jasné principielně: V C, C++ a dalších jazycích se nad prací v editoru + příkazové řádce nidko nepozastavuje, je to celkem běžné. V Javě to najednou nejde efektivně. Dávalo by to smysl, kdyby programování/debugování v Javě bylo nějak výraznně těžší než třeba C++, ale ono je to přesně naopak.
Hlavně mi to ale není jasné principielně: V C, C++ a dalších jazycích se nad prací v editoru + příkazové řádce nidko nepozastavuje, je to celkem běžné.Jako clovek, ktery aktivne pouziva oba dva svety, dovolim si pridat sve dva centy do teto nekonecne diskuze. V pripade C, assembleru nebo Pythonu, je ViM + prikazova radka jasna volba. Je to dane hlavne tim, ze IDE nemohou az na dren vyuzit analyzu kodu a vcelku zabehnute konvence pro psani kodu, organizaci projektu, atd. jako je to v pripade Javy.
V Javě to najednou nejde efektivně.Obcas jsem nucen neco v Jave programovat ve ViMu a ten komfort prace je uplne jinde. Ne, ze by to neslo, ale ta prace jde strasne pomalu. Jsou to desitky drobnosti, ktere te zdrzuji: nutnost prepinat do jineho okna kvuli dokumentaci, nemoznost prokliknout se na implementaci metody, absence refaktorizace, napoveda metod pouze podle toho, co jsi uz pouzil nebo i treba nutnost vytukovat nazev metody kompletne na klavesnici. V IDE obvykle staci jen par znaku. Pouzivat ViM na Javu je asi takovy pocit, jako kdyz mas pet let stary pocitac a bez problemu ho pouzivas a pak si poridis novy a za nejakou dobu se vratis k tomu puvodnimu a zjistis, ze s takovym pocitacem se neda skoro pracovat. Podobne to mam treba i pri programovani ve Scale, kde sice mam IDE, na ktere jsem zvykly, ale na tech nastrojich jde videt, ze jeste nejsou doladene jak pro Javu a stale mi nekde nejaka vlastnost, na kterou jsem zvykly, chybi a to zdrzuje.
V UNIXu se preferuje klasicky toolchain s gcc/g++, ld, make, gdb apod. a zrejme nic moc lepsiho neexistuje.Existuje: Qt Creator. Lepší IDE pro C/C++ IMHO neexistuje, i na Windows je lepší než MSVC. A je přitom stále relativně lehkotonážní. Eclipse je hrozný na cokoli. (IMHO.) Jinak ale zpět k Java IDE (a je to i reakce na děda.jabko): Samozřejmě chápu, proč Java IDE může dělat věci, které C/C++/Whatever IDE dělat nemůže. Nicméně tím pádem ale z vašich komentářů v podstatě plyne, že efektivně programovat lze pouze v Javě.
Existuje: Qt Creator.Znam, ale zkusenost nemam (asi krome nejakeho Hello worldu).
Eclipse je hrozný na cokoli. (IMHO.)Eclipse jsem mel rad a delsi dobu pouzival na vicero veci (Java, Python, LaTeX). Krome relativne vzacnych padu/zaseku to bylo v pohode. Pak jsem to zacal pouzivat v praci na vetsim Maven projektu slozenem z vice modulu a nadaval jsem minimalne 2x denne. Prechod na IntelliJ to vyresil.
Nicméně tím pádem ale z vašich komentářů v podstatě plyne, že efektivně programovat lze pouze v Javě.Sam bych to lepe nerekl. Jen tedy zalezi na tom, co pises, zda jsou v dane oblasti k dispozici kvalitni knihovny/frameworky, a fakt, ze musis startovat IDE, zakladat projekt, pridavat do nej zavislosti a popr. vysledek exportovat do JARu, nezpusobuje tak velke zdrzeni, ze bys za tu dobu v nejakem vice lehkotonaznim setupu jiz nemel napsany kompletni zdrojovy kod. To je zasadni prekazka treba u prototypovani a rychle automatizace a napr. Python je v techto pripadech IMHO o nekolik magnitud lepsi varianta.
Sam bych to lepe nerekl.ROFL. Bylo by fajn, kdyby se lidé, kterým stoupla Java* do hlavy, nějak snadno poznali, aby člověk věděl, že nemá ztrácet čas pokusy o rozumnou diskusi... *) příp. obecně jakýkoli jazyk - nicméně přijde mi, že Java a LISP jsou fanatickými vyznavači a sektářstvím postiženy nejvíce...
Tak ono to bude u vetsiny jazyku podobne, akorat ze Javistu je spousta tak je to asi vic videt. No a u LISPu tam to bude tim ze jsou to opravdu fanatici :)
Nicméně tím pádem ale z vašich komentářů v podstatě plyne, že efektivně programovat lze pouze v Javě.Nic takoveho netvrdim. Reaguji na tvrzeni:
Pokud říkáš, že kdo nepoužívá IDE nemůže efektivně programovat v Javě, tak s tím silně nesouhlasim.Protoze moc dobre vim, jaky je rozdil v efektivite pri pouziti obou nastroju. VELKY!
Tak ono existuje CLion a to je IMHO super IDE pro C++ jak na linux tak windows, popravde skoro pro vetsinu jazyku si myslim ze ma IDE hlavne vyhody. Jen je potreba mit kvalitni IDE.
V C, C++ a dalších jazycích se nad prací v editoru + příkazové řádce nidko nepozastavuje, je to celkem běžné. V Javě to najednou nejde efektivně.Možná pro ty jiné jazyky nejsou tak dobrá IDE, takže lidi nemají srovnání a nechybí jim to. Ale když u té javy víš, jak dobře a efektivně se pracuje v IDE a kolik času ti to ušetří, tak se ti v tom editoru nebude chtít dělat. Ono takový Bash nebo Perl taky píšu v obyčejném editoru, který maximálně tak zvýrazňuje syntaxi, a nic mi nechybí, protože jsem pro tyhle jazyky IDE nikdy nepoužíval. Totéž PHP – kdysi jsem v něm psal a taky jen v editoru, nic mi nechybělo, byl jsem zvyklý na ten styl práce – hledat v dokumentaci v jiném okně a pozorně přepisovat příkazy a dávat pozor, abych někde neudělal překlep. Dneska už IDE pro PHP existují, tak bych možná nějaké použil.
Možná pro ty jiné jazyky nejsou tak dobrá IDE, takže lidi nemají srovnání a nechybí jim to.To je nějaká psychologie vývojáře nebo co? Trochu mi to připomíná náboženstvím, tam se taky argumentuje tím, že nechybí jen tomu, kdo ho nepoznal, přitom to není tak úplně pravda. :)
Možná pro ty jiné jazyky nejsou tak dobrá IDE, takže lidi nemají srovnání a nechybí jim to. Ale když u té javy víš, jak dobře a efektivně se pracuje v IDE a kolik času ti to ušetří, tak se ti v tom editoru nebude chtít dělat.Ale já tu zkušenost z Javy i z C++ mám koneckonců taky. Eclipse jsem vyřadil velice rychle, protože prostě nefungovalo dobře (dnes je to možná lepší, nevím), ale poměrně dlouho jsem používal QtC pro C++ a NetBeans a IntelliJ pro Javu, nicméně časem jsem je opustil. Ono by se takhle dalo argumentovat i obráceně - dalo by se tvrdit, že kdo není zvyklý na efktivní editor a neumí dobře používat nástroje jako debuggery, build systémy, VCS, atd. z příkazové řádky / editoru, neví, že IDE nepotřebuje
IMHO obecně ale záleží hlavně na zvycích a způsobem, jakým je konkrétní projekt nastavený. Když má někdo projekt + workflow optimalizovaný pro IDE, zejména konkrétní IDE a jeho konkrétní fíčury, je celkem jasné, že to nejefektivnější na tom projektu pracovat v tomto IDE. Je ale fajn vědět o tom, že IDE (a už vůbec konkrétní IDE) není nutně jediná cesta k efektivitě (ačkoli někteří mi to nevěří).
dalo by se tvrdit, že kdo není zvyklý na efktivní editor a neumí dobře používat nástroje jako debuggery, build systémy, VCS, atd. z příkazové řádky / editoru, neví, že IDE nepotřebujeOno, abychom se netocili porad v kruhu, je dobre si pripomenout, ze IDE je zkratka z integrated development environment. Z toho celkem vyplyva, jake by to melo mit vlastnosti (tj. je to integrovane, konzistentni). Co konkretne za hlavni vyhody (realne existujicich) IDE povazuju ja, jsem zde uz zminoval. Znovu pripomenu, ze mluvim o obrovske pomoci pri editovani (naseptavani, validace, refactoringy, formatovani), o integraci s build systemem, ktera umoznuje snadno spoustet konkretni test-cases, konkretni main apod. a o grafickem debuggeru, pricemz to vse je zaintegrovane a spojene dohromady. Jsem primo v editoru, tam nastavim breakpoint/watch - nemusim se prepinat do jine aplikace a rucne to v ni zadavat (cimz jeste vznika riziko preklepu). Kdyz pri debugovani chci vyhodnotit snippet kodu, ktery treba nejak profiltruje kolekci ulozenou v promenne, abych se v ni lepe vyznal, tak stisknu jedinou klavesovou zkratku a kod zadam do policka, ktere se chova stejne jako kdybych editoval soubor (tj. ma syntax highlighting, naseptavani apod. - ale pritom je to v podstate REPL). To jsou ty podstatne vyhody IDE. Pokud si v systemu poradne nastavis klavesove zkratky, napises si skripty, poladis si WM, aby ruzna okna oteviral v tech a tech castech obrazovky apod., a celkove to nejak zaintegrujes dohromady (i.e. budes mit v textovem editoru nabindovano, ze na stisk CTRL+SHIFT+B se spusti makro, ktere precte jmeno souboru a cislo aktualniho radku a nasledne ho zapise/odebere ze souboru se seznamem breakpointu, ktere se automaticky nastavi pri spusteni konzoloveho debuggeru apod.), tak sice dosahnes tehoz, ale moment... Oh yeah, vytvoril sis vlastni IDE.
Oh yeah, vytvoril sis vlastni IDE.Tento postup má svoje výhody. Pokud ti nevyhovuje existující IDE, ale vyhovují ti dílčí nástroje, můžeš si z nich udělat celkem jednoduše buď vlastní IDE (o což osobně nemám zájem) nebo takový subset IDE, který ti bohatě stačí a zbytek ovládat přímo. Já osobně nemám žádnou dobrou motivaci používat IDE, ale mám dobrou motivaci používat standardní náštroje. Hlavní motivace je, že je stejně budu používat a stejně je potřebuju umět ovládat. Osobně preferuju používat na všechno za všech okolností jediný textový editor (vim), všechny kličky a automatizaci se učit v něm a případně si ho podle potřeb dokonfigurovat. Oproti tomu o klávesovou zkratku, která mi rozběhne debugger na aktuální řádce, momentálně ani nemá zájem. Vždycky je to něco za něco a u mě z různých důvodů vyhrála volba existující IDE ignorovat.
Tento postup má svoje výhody.Urcite. Jedinym parametrem je potom cas, ale pokud si nekdo svoje vyvojarske prostredi skutecne vypipla presne podle svych predstav, tak se mu ten investovany cas snad i muze vratit. Porad si stojim za tim, ze ty zminovane funkce maji obrovsky prinos, ale jestli toho clovek docili instalaci jednoho molocha, nebo vic mensich toolu, to souhlasim, ze uz je uplne nepodstatne.
Znovu pripomenu, ze mluvim o obrovske pomoci pri editovani (naseptavani, validace, refactoringy, formatovani)Tohle mi přijde jako nejméně atraktivní. Našeptávání funguje spolehlivě pouze v Javě, ale i tam mi ten přínos přijde sporný. Vzpomínám si, že IDE typicky našeptávalo moc, třeba jsem měl třeba zájem o jeden konkrétní overload a IDE mi jich cpalo X dalších aniž bych o ně měl zájem. Píšu kód a neustále na mě vyskakuje okénko s milionem nesouvisejících funkcí a překrývá kód, na který chci vidět, ukazuje dokumentaci, kterou buď už mám přečtenou nebo o ní vůbec nemám zájem, protože patří k nějaké jiné funkci, apod. Validace kódu mi přijde úplně na hlavu - kód chci typicky validovat až když ho kompiluju, tj. až když je hotový, ne když ho teprve píšu. V důsledku validace kódu v Java IDE na mě v minimálně 80% vyhazuje false positives/negatives, prostě protože neví, co chci udělat. Celkově mi přijde, že našeptávání v Java IDE a IDE obecně má poměrně velice špatné signal-to-noise ratio. Refactoring a formátování zvládají editory IMHO +/- stejně dobře. Alespoň taková je moje zkušenost.
integraci s build systememOpět, z mojí zkušenosti tohle není přínos. Integrace s build systémem funguje dobře, pokud člověk dělá přesně to, co po něm IDE chce (to je to o tom otroctví, co jsem zmiňoval výše). Jakmile si nastavíš build systém nějak maličko jinak, než jak IDE předpokládá, nebo chceš použít jiný build systém nebo prostě mít to trochu pod kontrolou - například si chceš udělat trochu jinak adresářovou strukturu., IDE tvé konfiguraci nebude rozumět a možná ti taky tvoje věci přepíše nebo ti to nějak zvoře. I to se mi stávalo.
o grafickem debuggeru, pricemz to vse je zaintegrovane a spojene dohromady. Jsem primo v editoru, tam nastavim breakpoint/watch - nemusim se prepinat do jine aplikace a rucne to v ni zadavatTohle beru. Integrace s debuggerem mi připadá z těch vlastností nejsmysluplnější a umím si představit, že to pomáhá. Na druhou stranu ale mi přiadá, že IDE se dost často snaží optimalizovat něco, co není bottleneck - nastavování breakpointu do řádky kódu není něco, co potřebuju udělat každých 30 sekund.
Našeptávání funguje spolehlivě pouze v JavěVsak uz jsme nekolikrat rekli, ze se bavime o Jave, protoze tam je situace o dost lepsi nez v jinych jazycich. Nema smysl srovnavat pouziti stejneho druhu nastroju na zcela rozdilne jazyky a projekty, kdyz to tam treba ani neni k dispozici.
Vzpomínám si, že IDE typicky našeptávalo mocAutomaticke naseptavani lze samozrejme vypnout a vyvolat rucne jen v pripade potreby (typicky pomoci CTRL+Space).
Validace kódu mi přijde úplně na hlavu - kód chci typicky validovat až když ho kompiluju, tj. až když je hotový, ne když ho teprve píšu.Nestava se mi, ze by pulka kodu svitila cervene. Kod chci validovat hned, abych pripadne problemy odhalil co nejdriv. Rucne se kompilace spousti typicky pro cely projekt najednou.
Refactoring a formátování zvládají editory IMHO +/- stejně dobře.Mas nasledujici metodu:
void foo(int a, int b, boolean c) {
Jednou klavesovou zkratku (CTRL+ALT+H) si zobrazim vsechna pouziti. Vidim, ze argument c je vzdy true a rozhodnu se, ze ho odstranim. Dalsi klavesovou zkratkou (SHIFT+ALT+C) zmenim signaturu metody a argument odeberu, coz se promitne do vsech mist, kde se metoda vola.
Ted chci slyset presny postup, jak to delas ty. At se bavime konkretne. Pouzivas grep, nebo vyhledavani v Sublime? Jak ten hledany vyraz upresnis tak, aby podchytil pouze volani metody nad danym typem, nikoliv jinymi, kde se vyskytuje stejne nazvana metoda? A co kdyz nekdo tu metodu zavola nad potomkem? A jak potom odstranujes ten prebytecny argument? Regularnim vyrazem?
Rikam - bavme se konkretne.
Jakmile si nastavíš build systém nějak maličko jinak, než jak IDE předpokládá, nebo chceš použít jiný build systém nebo prostě mít to trochu pod kontrolou - například si chceš udělat trochu jinak adresářovou strukturu., IDE tvé konfiguraci nebude rozumět a možná ti taky tvoje věci přepíše nebo ti to nějak zvoře.Projekt je popsany sadou Maven/Gradle souboru a do IDE jej pote jednoduse naimportujes. Nevim, o jake jine konfiguraci mluvis, ale vlastne je to jedno. Neni vina IDE, ze nekdo zacne znasilnovat build system a vyrazne se odchylovat od zavedene praxe, pokud je rec o tomhle.
Na druhou stranu ale mi přiadá, že IDE se dost často snaží optimalizovat něco, co není bottleneck - nastavování breakpointu do řádky kódu není něco, co potřebuju udělat každých 30 sekund.Pri tom debuggovani asi i jo.
Vsak uz jsme nekolikrat rekli, ze se bavime o Jave, protoze tam je situace o dost lepsi nez v jinych jazycich.No je pak otázka, jak moc má pro mě diskuse význam, protože pouze v Javě nedělám žádný projekt už docela dlouho (od té doby, co poslední čistě Java projekt, do kterého jsem přispíval, přešel na Kotlin). Udržovat si IDE pouze pro jeden jazyk určitě nebudu, resp. nechci s částí projektu pracovat s IDE a s ostatními nějak jinak (ditto building).
Ted chci slyset presny postup, jak to delas ty. At se bavime konkretne. Pouzivas grep, nebo vyhledavani v Sublime?To záleží. Pro Javu aktuálně píšu pouze v práci, kde je minoritní součástí projektu napsaného hlavně v C a Pythonu, takže uvažuju tento projekt. Záleželo by, jestli to je funkce "veřejná" nebo interní pro projekt. Pokud "veřejná" (tj. taková, kterou mohou používat ostatní projekty ve firmě) musel bych nejprve zjistit, jestli ji vůbec můžu upravit (tj. jaká je deklarovaná zpětná kompatibilita daného API), a pokud ano, musel bych zjistit, kde všade se používá, na což máme server podobný Woboqu nebo OpenGroku. Pokud by to byla pouze interní funkce, ktekrá by nebyla součástí API, použil bych grep nebo cscope (který je součástí našeho build systému). Místa, kde se metoda volá, bych pak prošel ručně pomocí navigace v editoru, chtěl bych vidět, jak se určuje hodnota argumentu a jestli s tím není potřeba něco udělat.
Neni vina IDE, ze nekdo zacne znasilnovat build system a vyrazne se odchylovat od zavedene praxe, pokud je rec o tomhle.Njn, není vina IDE, že se někdo chce zprotivit vůli IDE
U nás by tohle nešlo, protože jsou použity build systémy jako makefiles, cmake apod. S tím souvisí další věc: Co když na jednom projektu chtějí pracovat lidi s různými preferencemi ohledně IDE? Třeba jeden má rád NetBeans, druhej IntelliJ a třetí Eclipse - funguje to?
Pri tom debuggovani asi i jo.Můžeš si příště udělat poznámku, kolik jsi použil breakpointů... Dejme tomu, že ti bude trvat sekundu nastavit breakpoint, zatímco já budu 10× pomaleji, tj. 10 sekund, a budem potřebovat 20 breakpointů. Výsledkem je, že budu o 3 minuty pomalejší. To mi přijde dosti zanedbatelné, navíc IMHO ta čísla jsou spíš přemrštěná...
Udržovat si IDE pouze pro jeden jazyk určitě nebudu, resp. nechci s částí projektu pracovat s IDE a s ostatními nějak jinak (ditto building).To je tvuj problem.
Pokud by to byla pouze interní funkce, ktekrá by nebyla součástí API, použil bych grep nebo cscope (který je součástí našeho build systému). Místa, kde se metoda volá, bych pak prošel ručně pomocí navigace v editoru, chtěl bych vidět, jak se určuje hodnota argumentu a jestli s tím není potřeba něco udělat.... a rucne to upravil, super.
Pro Javu aktuálně píšu pouze v práci, kde je minoritní součástí projektu napsaného hlavně v C a Pythonu, takže uvažuju tento projekt. [...] U nás by tohle nešlo, protože jsou použity build systémy jako makefiles, cmake apod.Ten vas projekt zni jako spanelska vesnice. Proc to neni rozsekane do vic projektu, ktere jsou vic oddelene? Proc
make a cmake jakkoliv, byt vzdalene, zasahuje do Java projektu? I v pripade, ze pouzivate JNI, by snad nebyl problem drzet zdrojaky v C zcela oddelene a odkazovat se pouze na vyslednou *.so/*.dll knihovnu.
Co když na jednom projektu chtějí pracovat lidi s různými preferencemi ohledně IDE? Třeba jeden má rád NetBeans, druhej IntelliJ a třetí Eclipse - funguje to?Presne takovou situaci (se tremi tebou jmenovanymi IDE) v praci mame. Nevim, proc by to nemelo fungovat.
Můžeš si příště udělat poznámku, kolik jsi použil breakpointů... Dejme tomu, že ti bude trvat sekundu nastavit breakpoint, zatímco já budu 10× pomaleji, tj. 10 sekund, a budem potřebovat 20 breakpointů. Výsledkem je, že budu o 3 minuty pomalejší. To mi přijde dosti zanedbatelné, navíc IMHO ta čísla jsou spíš přemrštěná...Kdyz neco muzes udelat na jeden stisk klavesove zkratky, tak budes mnohem ochotnejsi to udelat, nez kdyz to vyzaduje vic manualni prace. Kdyz srovnam vsechny argumenty, jasne z toho vychazi, ze pouzivani dobreho IDE (v Jave) je vyrazne efektivnejsi. Ty se tomu branis, protoze nejsi dostatecne flexibilni na to, abys prechazel mezi ruznymi IDE/editory, nebo zastiras, ze nemas k dispozici zadne automaticke nastroje na refactoringy (a rozhodne ne tak pohodlne), nebo se snazis navodit dojem, ze vlastne nevadi, kdyz je neco pomalejsi, protoze to nedelas tak casto. To je jako prohlasit, ze tedy v IDE to udelas rychlejs, ale tobe je to vlastne stejne jedno, protoze stejne moc neprogramujes (coz jsi ostatne v podstate sam rekl: "Pro Javu aktuálně píšu pouze v práci, kde je minoritní součástí projektu napsaného hlavně v C a Pythonu"). Takze kdyz to nejak ukoncim, tak co do argumentu ohledne efektivity vyvoje jednoznacne zvitezilo IDE a zbytek jsou tvoje (pro kontext zdejsi diskuze) irelevantni subjektivni postoje a nezkusenost/neznalost.
To je tvuj problem.Co bys dělal na mém místě? Používal jedno IDE pro C kód, druhé IDE pro Python kód a třetí pro Javu?
... a rucne to upravil, super.Jistě. Ty jsi vytvořil případ, který je specifický a pro refactoring pomocí IDE ideální - parametry funkce byly pouze literáry (jestli jsem to správně pochopil). Pokud by to literáry nebyly (což je IMHO mnohem typičtější), je IMHO lepší nebo dokonce nutné se ručně podívat na call site. Nepamatuju se, že bych takovýhle případ řešil v poslední době, natož pak často, není mi tedy úplně jasné, proč ho optimalizovat.
Ten vas projekt zni jako spanelska vesnice. Proc to neni rozsekane do vic projektu, ktere jsou vic oddelene?Rozsekané a oddělené to je. JNI použito není, je tam nějaký java kód, který je generovaný.
Proc make a cmake jakkoliv, byt vzdalene, zasahuje do Java projektu?Javovská část je sestavovaná cmake/make stejně jako zbytek, abychom nemuseli řešit nějaký další build systém.
Kdyz srovnam vsechny argumenty, jasne z toho vychazi, ze pouzivani dobreho IDE (v Jave) je vyrazne efektivnejsi.Vskutku? Mně připadá, že tvoje argumenty byly zatím celkem klasickou ukázkou mikro-optimalizace - to, co prohlašuješ za zvýšení efektivity mi připadá jako získání IMHO relativně zanedbatelného množství času na něčem, o čem ses ani nezamýšlel (natožpak nějak zjišťoval), jestli je vůbec bottleneck.
nebo zastiras, ze nemas k dispozici zadne automaticke nastroje na refactoringyK cscope jsem se přiznal bez mučení.
Takze kdyz to nejak ukoncim, tak co do argumentu ohledne efektivity vyvoje jednoznacne zvitezilo IDE a zbytek jsou tvoje (pro kontext zdejsi diskuze) irelevantni subjektivni postoje a nezkusenost/neznalost.
Ok. Úplně jsi mě prokoukl.
Co bys dělal na mém místě? Používal jedno IDE pro C kód, druhé IDE pro Python kód a třetí pro Javu?Ano. Na C mam ViM, na Javu Eclipse, v cem je problem? Nebo taky jis rizek lzici, protoze kdyz jsi s ni jedl polevku, bylo to docela efektivni?
Javovská část je sestavovaná cmake/make stejně jako zbytek, abychom nemuseli řešit nějaký další build systém.Aha...
Ano. Na C mam ViM, na Javu Eclipse, v cem je problem?Ok, to máme dva jazyky, dále používám C++ (to asi bude stejný případ jako C), Rust, Python, JS, shell skripty a možná nějaké další (Kotlin,...). AFAIK pro každý tento jazyk exituje IDE, které tvrdí, že je mnohem efektivnější než zbytek světa.
Dále člověk edituje spoustu věcí, které nejsou programový kód. Text, různé textové markup formáty, textové konfigurační formáty, textové datové formáty.Občas i tohle edituji v Netbeans, protože spolupracují s verzovacím systémem a podbarvují mi změněné řádky + stačí jediné kliknutí a vidím, jaká tam byla předchozí verze (tzn. co je v Mercurialu/Gitu/SVN). Nemáš tip na jednoduchý editor, který by tohle uměl? (je mi relativně jedno, jestli GUI nebo pro konsoli)
Co bys dělal na mém místě? Používal jedno IDE pro C kód, druhé IDE pro Python kód a třetí pro Javu?Nevim. V kazdem pripade bych se nesnazil tvrdit, ze IDE oproti editoru nic neprinasi a je to stejne efektivni, kdyby to nebylo podlozene tvrdymi fakty.
Jistě. Ty jsi vytvořil případ, který je specifický a pro refactoring pomocí IDE ideální - parametry funkce byly pouze literáry (jestli jsem to správně pochopil). Pokud by to literáry nebyly (což je IMHO mnohem typičtější), je IMHO lepší nebo dokonce nutné se ručně podívat na call site.Prohlednuti vsech mist, odkud se metoda vola, jsem jasne uvedl a jeste jsem se te ptal, jak to budes s prostym vyhledavanim v editoru resit, kdyz metoda muze byt zavolana nad potomkem (tj. jinym typem).
Javovská část je sestavovaná cmake/make stejně jako zbytek, abychom nemuseli řešit nějaký další build systém.V tom pracne hledam jakoukoliv logiku, ale dejme tomu.
Mně připadá, že tvoje argumenty byly zatím celkem klasickou ukázkou mikro-optimalizace - to, co prohlašuješ za zvýšení efektivity mi připadá jako získání IMHO relativně zanedbatelného množství času na něčem, o čem ses ani nezamýšlel (natožpak nějak zjišťoval), jestli je vůbec bottleneck.Jak ti to pripada je mi uplne jedno. Tohle jsou vsechno veci, ktere developer dela dnes a denne.
K cscope jsem se přiznal bez mučení.... a taktne nezodpovedel druhou cast otazky, kde jsem se psal, jak to odstraneni argumentu potom provedes. Regularnim vyrazem, nebo dokonce rucne?
A ne snad? Kdo se tady divil, jestli je mozne pouzivat vic ruznych IDE na stejnem projektu? Kdo si tady stezoval, ze naseptavani v IDE je prilis otravne, protoze nedokazal vlezt do nastaveni a vypnout to? Prijde ti tohle jako zcela objektivni zkusenost a opravdu relevantni srovnani, nebo spis jako subjektivni prskani na neco, co se ti nelibi?
Prohlednuti vsech mist, odkud se metoda vola, jsem jasne uvedl a jeste jsem se te ptal, jak to budes s prostym vyhledavanim v editoru resit, kdyz metoda muze byt zavolana nad potomkem (tj. jinym typem). (...) ... a taktne nezodpovedel druhou cast otazky, kde jsem se psal, jak to odstraneni argumentu potom provedes. Regularnim vyrazem, nebo dokonce rucne?Nejprve předesílám, že jsem nic taktně nezamlčoval. Nejsem šéfem spyknutí na asasinaci IDE. Snažil jsem se odpovědět co nejlépe. Když se vyhledávání provede grepem, není důvod předpokládat, že to nenajde použití v potomcích - false negatives tam nebudou, spíš false positives by mohly být problém (osobně ale celkem nemám problém je odignorovat). Ditto vyhledání přes cscope. Co také případně dělám, je, že zmením danou věc (funkci, proměnnou) v místě definice a nechám kompilátor, aby mi vyházel chyby, a tudíž našel místa, kde je potřeba to změnit. Sublime umí z výstupu kompilátoru otvírat soubory, ale to dělám jen tehdy, když je jich hodně, jinak neřešim. Nahrazení provádím nejčastěji fíčurami Sublime nebo regulárími výrazy.
Jak ti to pripada je mi uplne jedno. Tohle jsou vsechno veci, ktere developer dela dnes a denne.Ok, tak v tom případě je asi skvělé, když ušetříš 30 sekund dnes a denně. To zní jako citelný benefit... Já jsem popravdě zatím neznamenal v tvých komentářích o efektivitě vůbec nic, natož pak nějaká "tvrdá fakta". Už jenom tahle diskuse je časově o několik řádů náročnější než grepování zdrojáku.
Kdo se tady divil, jestli je mozne pouzivat vic ruznych IDE na stejnem projektu?Já, protože celkem často se stává, že někdo nasdílí projekt z IDE XY, který lze sestavit pouze IDE XY. Do jiného IDE případně jde "naimportovat přes wizard" a podobné kraviny... Že tohle není případ u vás je fajn.
Kdo si tady stezoval, ze naseptavani v IDE je prilis otravne, protoze nedokazal vlezt do nastaveni a vypnout to?Ale tak jasně, že jsem dokázal vlézt do nastavení a vypnout to. Následně jsem vypnul integraci s VCS a povypínal pár dalších věci a pak netrvalo dlouho a vypnul jsem IDE úplně a pustil editor. Mluvil jsem o výchozím nastavení, vídám lidi to tak používat.
Vsak uz jsme nekolikrat rekli, ze se bavime o Jave, protoze tam je situace o dost lepsi nez v jinych jazycich. Nema smysl srovnavat pouziti stejneho druhu nastroju na zcela rozdilne jazyky a projekty, kdyz to tam treba ani neni k dispozici.Jestli ono to nebude nahodou naopak ze ;) Java je skrz na srkz tak silene overengineered, ze bez IDE pouzivat nejde. Na vse krome Javy ne vyhovuje vim (s jedi pro python apod.), ale Java bez poradneho IDE (=IntelliJ) pouzivat nejde - vzdyt se staci podivat na to jakou Java vyzaduje adresarovou strukturu a naming convention!
Java sama o sobe je proste jen ukecany a striktni jazyk, ktery navic misty obsahuje nejake historicke chyby. Ty vlastnosti ale davaji prostor existenci tech IDE a dalsich nastroju, diky cemuz se vyplati v Jave vyvijet. Pouzivat v Jave spartansky pristup jako v C mi prijde sebevrazedna kombinace.
top, uplne stejna situace plati i u Pythonu - ono se to tak nejak asi holt tyka vsech interpretovanych jazyku (opet viz priloha).
Protoze se java programum vetsinou predava classpath o tisicich znacich
v top zmackni 'c' a hned uvidis co to je za ten program v pythonu (narozdil od javy)
Našeptávání funguje spolehlivě pouze v Javě, ale i tam mi ten přínos přijde sporný.V C# nebo Delphi to funguje taky dobre.
Vzpomínám si, že IDE typicky našeptávalo moc, třeba jsem měl třeba zájem o jeden konkrétní overload a IDE mi jich cpalo X dalších aniž bych o ně měl zájem.
Validace kódu mi přijde úplně na hlavu - kód chci typicky validovat až když ho kompiluju, tj. až když je hotový, ne když ho teprve píšu.Muzes byt konkretni a rict, o kterem IDE mluvis? Toto treba obcas dela Visual Studio, u Eclipse nebo Netbeans sem na tento problem nenarazil.
Refactoring a formátování zvládají editory IMHO +/- stejně dobřeKdyz mas hodne velkou toleranci na to +/-, tak to pak ano. Mas tridy Foo a Bar a obe maji metodu baz(). Jak v editoru elegantne a rychle a bezpecne prejmenujes metodu Bar.baz() na Bar.qux(), pricemz volani Foo.baz() zustanou nedotcena?
Jakmile si nastavíš build systém nějak maličko jinak, než jak IDE předpokládá, nebo chceš použít jiný build systém nebo prostě mít to trochu pod kontrolou - například si chceš udělat trochu jinak adresářovou strukturu., IDE tvé konfiguraci nebude rozumět a možná ti taky tvoje věci přepíše nebo ti to nějak zvoře. I to se mi stávalo.Tak si musis upravit i nastaveni prekladace v IDE. V pripade Javy jenom reknes, jaky Ant script se ma pouzit a kompilujes stejne jako z prikazove radky. I v tom blbem a neohebnem Visual Studiu si muzes nastavit, ktery program se ma pouzit v jake fazi a s jakymi parametry.
Na druhou stranu ale mi přiadá, že IDE se dost často snaží optimalizovat něco, co není bottleneck - nastavování breakpointu do řádky kódu není něco, co potřebuju udělat každých 30 sekund.Cokoliv, co muzes udelat rychleji setri tvuj cas a nervy. Zajimalo by me, co podle tebe je ten opravdovy bottleneck?
Muzes byt konkretni a rict, o kterem IDE mluvis? Toto treba obcas dela Visual Studio, u Eclipse nebo Netbeans sem na tento problem nenarazil.Buď NB nebo IntelliJ.
Cokoliv, co muzes udelat rychleji setri tvuj cas a nervy.Tak to se ale pak zcela vylučuje s IDE, které teda moje nervy rozhodně nešetří.
Zajimalo by me, co podle tebe je ten opravdovy bottleneck?Vymslet, na co by se měla funkce přejmenovat, jaké by měla mít parametry, jak by se ty parametry měly používat atd. atd. atd. - to je IMHO práce programátora. S lidmi, kteří prosě jen chrlí kód (v čemž jim IDE pomáhá), jsem už měl tu čest pracovat...
Tak to se ale pak zcela vylučuje s IDE, které teda moje nervy rozhodně nešetří.Myslim, ze problem bude nekde uplne jinde nez v IDE. Pripominas mi decka, ktera na Linuxu nadavaji na to, jak je ViM/Emacs nepouzitelny, neprakticky a pomaly editor a radeji pouzivaji Nano, nez aby se naucily pouzivat poradny editor(tm) a vyuzily poradne jeho schopnosti.
Vymslet, na co by se měla funkce přejmenovat, jaké by měla mít parametry, jak by se ty parametry měly používat atd. atd. atd. - to je IMHO práce programátora.A s tim ti bezny textovy editor pomuze jak? Nemusis odpovidat, je to jen recnicka otazka.
S lidmi, kteří prosě jen chrlí kód (v čemž jim IDE pomáhá), jsem už měl tu čest pracovat...Takze radsi stravis vic casu datlovanim samotneho kodu misto, aby ses venoval vymysleni toho kodu. Good job!
Takze radsi stravis vic casu datlovanim samotneho kodu misto, aby ses venoval vymysleni toho kodu. Good job!Dobrý straw man.
Pripominas mi decka, ktera na Linuxu nadavaji na to, jak je ViM/Emacs nepouzitelny, neprakticky a pomaly editor a radeji pouzivaji Nano, nez aby se naucily pouzivat poradny editor(tm) a vyuzily poradne jeho schopnosti.A co je na tom špatně? Pokud někomu vyhovuje psát v nějakém editoru, ať si ho pro mě za mě používá. Taky jsem různě měnil preference, začínal jsem na různých IDE, postupem času jsem přešel na relativně jednoduché editory jako Kate a mcedit a v jednu chvíli jsem měl důvod začít používat vim a ponechávám si možnost preference opět změnit. Tohle není ani tak o děckách jako spíše o výběru nástrojů, které mi v danou chvíli vyhovují a pomáhají.
Takze radsi stravis vic casu datlovanim samotneho kodu misto, aby ses venoval vymysleni toho kodu. Good job!Zábavná představa, ale nic víc.
Pokud někomu vyhovuje psát v nějakém editoru, ať si ho pro mě za mě používáMne je to jedno, at si kazdy programuje v cem chce. Mne vadi to kralykova snaha presvedcovat ostatni (ale asi hlavne sebe), ze IDE jsou vlastne k nicemu.
IDE je zkratka z integrated development environment.Tak ono za IDE se dá považovat i editor + pluginy + bash + screen nebo správce oken + debugger + verzovací systém + vlastní sada skriptů… jen si to každý programátor integruje sám, místo aby použil hotové řešení. A teď otázky:
Tak ono za IDE se dá považovat i editor + pluginy + bash + screen nebo správce oken + debugger + verzovací systém + vlastní sada skriptů…Každý v diskuzi ví, co to znamená skládat nástroje dohromady a používat jako základ terminál s bashem, z něj volat všechny potřebné nástroje a psát si kolem toho skripty. Každý v diskuzi ví, co to znamená IDE, tedy že už je hotové integrované, když ho člověk stahuje a spouští. Nejsou to vlastní skripty ani žádné jiné věci, které si člověk vytváří sám a může si je na míru upravovat. Relativizace není argument.
Nejde o to, že by to IDE neumělo, že by v něm něco chybělo, ale některé věci je z principu lepší dělat na příkazové řádce.Pokud IDE neposkytuje mimojiné příkazovou řádku, pak neumí to, co příkazová řádka. Pokud ano, tak to není tak úplně zásluha toho IDE. :)
Hádat se na téma editory vs. IDE mi přijde celkem zbytečné, protože v podstatě každé prostředí, ve kterém někdo programuje, lze s trochou snahy považovat za IDE (byť ručně vyrobené, což je trochu práce navíc), takže bych diskusi omezil jen na ty nástroje/funkce – to jsem vážně jediný, kdo by je chtěl i pro jiné jazyky než Javu? Nejde to pro ty jazyky napsat?Ok, připadá mi, že diskuse se dostala příliš daleko a zabředla přísliš hluboko (např. do osobní roviny), takže se pokusím o trochu "big picture": Nástroje na analýzu / refaktoring / debuggin atd. jsou fajn. V některých jazycích je o hodně jednodušší je vytvořit tak, aby spolehlivě fungovaly, než v jiných, ale jsou fajn v každém případě. Mně na IDE nevadí to "DE" (tj. ty nástroje), mně na nich vadí to "I". To, že ty nástroje jsou takhle integrované dohromady, znamená (typicky), že: 1) IDE je moloch, zabírá hodně RAM, žere CPU, neefektivně využívá plochu obrazovky, v Javě má vysokou latenci UI (to mi jde hrozně na nervy). 2) Ty nástroje jsou obvykle specifické pouze pro dané IDE. Jakmile dané IDE přestane z jakéhokoli důvodu vyhovovat - tj. např. je potřeba programovat v jazyce, které dané IDE nepodporuje (tak dobře), je potřeba použít build systém, který IDE nepodporuje (tak dobře) atd. atd., zkrátka, jakmile člověk potřebuje přepnout někam jinam, je mu najednou celý ten dosavadní setup s veškerým nastavením i se získanými znalostmi naprosto k ničemu, může to celé zahodit. Dedikované nástroje díky tomu, že nejsou součástí (Integrated™) do jednoho GUI od jedné Firmy Inc. jsou mnohem flexibilnější, šířeji použitelné. Lidi v mém okolí, kteří používají ViM/Emacs Hodně mi to připomíná diskuse, kde si lidi od Windows stěžují na administraci Linuxu - že nemají GUI jako Ovládací panely, MMC a tak dále a že člověk na Linuxu musí psát dlouhé složité příkazy na klávesnici - což, ano, je pravda, ale ta flexibilita, znovupoužitelnost a "hackovatelnost" těch příkazů a dedikovaných programů je ve výsledku mnohem cennější komoditou. Až bude existovat IDE, které bude 1) jazykově agnostické, 2) lehkotonážní a 3) dobře integrované s příkazovou řádkou a existujícími non-IDE-specifickými nástroji, dejte mi vědět. Připadá mi, že Sublime, ViM nebo Emacs jsou tomu zatím nejblíže, ačkoli to samozřejmě není ideální...
Dedikované nástroje díky tomu, že nejsou součástí (Integrated™) do jednoho GUI od jedné Firmy Inc. jsou mnohem flexibilnější,To je jedna strana mince. Druha strana mince je, ze nektere veci proste dedikovanymi nastroji udelat nejdou, protoze nejsou soucasti toho integrovaneho celku.
zkrátka, jakmile člověk potřebuje přepnout někam jinam, je mu najednou celý ten dosavadní setup s veškerým nastavením i se získanými znalostmi naprosto k ničemu, může to celé zahoditTo se da rict o cemkoliv. Takze je podle tebe blbost ucit se pouzivat ViM, protoze kdyz se clovek octne na nejakem stroji, kde je jen Vi (jednou az dvakrat do mesice se mi to prihodi), muze vsechny sve znalosti zahodit?
1) jazykově agnostické, 2) lehkotonážní...aneb hledame mlade zamestnance s dlouholetymi zkusenostmi.
Na stroji pouze s vi budeš pravděpodobně o dost víc v pohodě díky znalosti vim než někdo, kdo nezná ani jeden z nich.Schvalne si to vyzkousej. Stejne tam funguje snad jenom :wq. Navic je to mnohem horsi, protoze se snazis zadavat prikazy, ktere proste neprojdou nebo udelaji neco jineho.
Další věc je, že vim nainstaluješ nejspíše o dost snáz než NetBeans...Nevim jak NetBeans, ale v pripade Eclipse staci dat unzip.
Schvalne si to vyzkousej.Však mně se to taky stává, obvykle mam problém, že nefungujou šipky, ale jinak to IIRC celkem jde...
Však mně se to taky stává, obvykle mam problém, že nefungujou šipky, ale jinak to IIRC celkem jde...Z hlavy... chybi visual mode, undo jeden krok zpet, redo neexistujici, prikazy typu gg chybi, atd. atd. takze opravdu nevim, jak ten ViM pouzivas, kdyz ti to vcelku jde.
Další věc je, že vim nainstaluješ nejspíše o dost snáz než NetBeans...To souvisi jak? Ty jsi zminoval, ze pouzivas Sublime, ktery je na serveru bez X uplne stejne k nicemu. Potrebujes dva editory tak jako tak.
K čemu to, když máme SSHFS? Přes něj si můžu otevřít zdrojáky v čemkoli od vi po Netbeans.Když potřebuju rychle zeditovat nějakej soubor, nechce se mi chtít mountovat sshfs. Ale jinak samozřejmě sshfs používám na projekt, se stabilitou nebo pomalostí na lokální síti určitě problém nemám. Přes nějaké vzdálenější připojení, zejména když je člověk někde na nějaké šitské wifi, už je to horší, to už je pak spíš na vcs nebo rsync...
...aneb hledame mlade zamestnance s dlouholetymi zkusenostmi.Ano, tak trochu
IDE je moloch, zabírá hodně RAM, žere CPUAno, je potreba mit dobry pocitac. (To ale mnohdy nejen kvuli IDE.)
neefektivně využívá plochu obrazovkyVidim editor, nekdy dalsi okynka, kdyz je potrebuju. Oproti beznemu editoru zde jedna jednoradkova lista pod klasickym File/Edit/... menu a jeden jednoradkovy status bar. To je podle tebe neefektivni vyuzivani plochy obrazovky?
v Javě má vysokou latenci UI (to mi jde hrozně na nervy)Eclipse je napsany v Jave, ale pouziva SWT, takze timto neduhem netrpi. IntelliJ a NetBeans trochu ano.
zkrátka, jakmile člověk potřebuje přepnout někam jinam, je mu najednou celý ten dosavadní setup s veškerým nastavením i se získanými znalostmi naprosto k ničemu, může to celé zahoditCoz neni argument proti (udajne) neefektivite IDE, ale spis snaha obhajit vlastni neflexibilitu.
Hodně mi to připomíná diskuse, kde si lidi od Windows stěžují na administraci Linuxu - že nemají GUI jako Ovládací panely, MMC a tak dále a že člověk na Linuxu musí psát dlouhé složité příkazy na klávesnici - což, ano, je pravda, ale ta flexibilita, znovupoužitelnost a "hackovatelnost" těch příkazů a dedikovaných programů je ve výsledku mnohem cennější komoditou.Mne to spis pripada jako bys obhajoval pouzivani nejakeho konzoloveho grafickeho editoru namisto treba GIMPu. Prece vetsinu casu stravis vymyslenim obrazku, to je ten skutecny bottleneck, a neni zadny problem pak rucne zadat koordinaty plochy, kterou chces oznacit, nebo pouzit misto aplikovani filtru kliknutim volit CLI dedikovane programy, kazdy s uplne jinymi argumenty a chovanim.
Coz neni argument proti (udajne) neefektivite IDE, ale spis snaha obhajit vlastni neflexibilitu.Nemyslím si, že IDE jsou neefektivní, mají potenciál efektivitu zvyšovat, zejména v dílčích věcech (jako to vyhledání symbolu et al.), šlo mi spíš o ten široce automaticky a celkem bez většího kritického zamyšlení akceptovaný axiom že IDE = vyšší efektivita / lepší kód / víc Adidas / apod. 1) IDE mají nevýhody a ten tradeoff IMHO nemusí být až tak skvělý, jak všichni tvrdí, a 2) efektivita nějakých dílčích kroků nemusí nutně zvyšovat celkovou efektivitu. Kdokoli, kdo se někdy snažil optimalizovat netriviální program, ví, o čem je řeč. Problém je v tom, že celkovou efektivitu je dost těžké nějak definovat, natož měřit, navíc osobní preference a vlastnosti a specifika projektu/projektů hrajou hodně velkou roli. Jasně, může to být vnímáno jako nedostatek flexibility na mé straně, nebo to může být vnímáno jako něco, co flexibilitu naopak zvyšuje (ie. možnost pracovat ve víceméně jakémkoli jazyku, aniž by k tomu člověk potřeboval instalaci IDE XY), to už nechám na čtenářích a je mi to celkem jedno, klidně mě můžete považovat za neflexibilního...
Mne to spis pripada jako bys obhajoval pouzivani nejakeho konzoloveho grafickeho editoru namisto treba GIMPu. Prece vetsinu casu stravis vymyslenim obrazku, to je ten skutecny bottleneck, a neni zadny problem pak rucne zadat koordinaty plochy, kterou chces oznacit, nebo pouzit misto aplikovani filtru kliknutim volit CLI dedikovane programy, kazdy s uplne jinymi argumenty a chovanim.No je pravda, že když potřebuju změnit velikost obrázku nebo konvertovat formát, občas se ani nenamáhám startovat GIMP a použiju mogrify/convert
Jinak editace grafiky vyžaduje pixely a myš/pero/etc, čili to mi přijde specifické...
Nemyslím si, že IDE jsou neefektivní, mají potenciál efektivitu zvyšovat, zejména v dílčích věcech (jako to vyhledání symbolu et al.), šlo mi spíš o ten široce automaticky a celkem bez většího kritického zamyšlení akceptovaný axiom že IDE = vyšší efektivita / lepší kód / víc Adidas / apod. 1) IDE mají nevýhody a ten tradeoff IMHO nemusí být až tak skvělý, jak všichni tvrdí, a 2) efektivita nějakých dílčích kroků nemusí nutně zvyšovat celkovou efektivitu. Kdokoli, kdo se někdy snažil optimalizovat netriviální program, ví, o čem je řeč.Cela tahle diskuze se tocila kolem tvrzeni, ze obycejne editory zastanou stejnou praci. Mluvis zde o nejakych predcasnych optimalizacich. Tvuj mozek sice podava stejny vykon bez ohledu na to, zda pracujes v editoru nebo IDE, ale trochu z toho vypoustis fakt, ze mozku prvne musis poskytnout vjemy, a dale mnou drive zminovanou psychiku ("to se mi nechce delat, je to pracne a mohl bych neco rozbit"). Abys dokazal udelat nejakou upravu, potrebujes si nejprve umet zobrazit zdrojove kody. V Jave to typicky znamena otevrit si zdrojove kody nejake tridy. IDE ti typicky dokaze nazev tridy naseptat a otevrit konkretni soubor. Bezny editor to takto rozhodne neumi v pripade, ze se takova trida nachazi uvnitr jine tridy - uz potrebujes statickou analyzu. Pri prohlizeni zdrojovych kodu se potrebujes umet dobre navigovat. Vlezt do metody pod kurzorem, ackoliv je nadefinovana uvnitr 3rd party knihovny (a treba k ni nemas zdrojove kody), zobrazit si hierarchii typu (tj. napr. nalezt implementaci konkretniho rozhrani), zobrazit si mista, odkud se metoda vola, nalezt pouziti dane promenne ci fieldu, zobrazit si Javadoc apod. Vsechny tyto funkce IDE poskytuje na stisk jedine klavesove zkratky. IntelliJ napr. umi dekompilovat tridu, ke ktere nema zdrojove kody, zpet do Javy. Pokud zdrojove kody k dispozici jsou, automaticky se pouziji. Nemusim se o to nijak starat (snad krome toho, ze vyvolam nad projektem kontextove menu a kliknu na Download sources). Jen ve fazi samotneho ziskavani informaci tedy IDE dokaze udelat treba trojnasobne zrychleni (a to verim, ze svuj odhad podhodnocuji). A ano, je rozdil, zda do kodu koukas 15 minut, nebo 5 minut, a to zvlast v pripade, ze jsi placeny za vysledky, ne za odsezeny cas. Pri psani kodu se to opakuje obdobne.
Problém je v tom, že celkovou efektivitu je dost těžké nějak definovat, natož měřit, navíc osobní preference a vlastnosti a specifika projektu/projektů hrajou hodně velkou roli.On by to takovy problem nebyl, ale ty v ramci sebeobrany stejne reknes, ze ty dane ukoly jsou usite na miru pro IDE. Ono je pak otazka, jestli clovek spravuje rozsahlejsi codebase, kterou neni mozne celou udrzet v pameti, nebo zda edituje nejake slozitejsi Hello, worldy, kde prinos IDE skutecne tolik nevynikne.
možnost pracovat ve víceméně jakémkoli jazyku, aniž by k tomu člověk potřeboval instalaci IDE XYJa take muzu nastartovat nejaky editor, otevrit konzoli s grepem a pracovat. Pouze jsem si vedom toho, ze budu pracovat vyrazne pomaleji a mene komfortne.
Jinak editace grafiky vyžaduje pixely a myš/pero/etc, čili to mi přijde specifické...Umisteni breakpointu vyzaduje znalost konkretniho souboru a konkretniho radku, takze mi to naopak prijde velmi podobne. Jeden pri pohledu do zdrojoveho kodu rovnou vi, ze sem chce umistit breakpoint, tak zmackne CTRL+SHIFT+B, druhy se prepne do jine aplikace a udaje tam nadatluje rucne, a tak by bylo mozne pokracovat.
Abys dokazal udelat nejakou upravu, potrebujes si nejprve umet zobrazit zdrojove kody. V Jave to typicky znamena otevrit si zdrojove kody nejake tridy. IDE ti typicky dokaze nazev tridy naseptat a otevrit konkretni soubor. Bezny editor to takto rozhodne neumi v pripade, ze se takova trida nachazi uvnitr jine tridy - uz potrebujes statickou analyzu.Přijde mi, že sis našel specielní případ, ale budiž, na tohle bude potřeba nějaká statická analýza, nicméně myslím, že cscope to dá.
Pri prohlizeni zdrojovych kodu se potrebujes umet dobre navigovat. Vlezt do metody pod kurzorem, ackoliv je nadefinovana uvnitr 3rd party knihovny (a treba k ni nemas zdrojove kody), zobrazit si hierarchii typu (tj. napr. nalezt implementaci konkretniho rozhrani), zobrazit si mista, odkud se metoda vola, nalezt pouziti dane promenne ci fieldu, zobrazit si Javadoc apod. Vsechny tyto funkce IDE poskytuje na stisk jedine klavesove zkratky.Když řeknu, že ViM/Emacs/Sublime + cscope nebo podobné nástroje to umí taky, tak mi předpokládám řekneš, že jsou z nich tím pádem IDE... (Což je asi i do jisté míry pravda.)
Jen ve fazi samotneho ziskavani informaci tedy IDE dokaze udelat treba trojnasobne zrychleni (a to verim, ze svuj odhad podhodnocuji). A ano, je rozdil, zda do kodu koukas 15 minut, nebo 5 minut, a to zvlast v pripade, ze jsi placeny za vysledky, ne za odsezeny cas.Moje zkušenost je, alespoň zatím, taková, že doba čtení zdrojáku/coredumpu/apod. závisí především na zkusnošti/schopnosti programátora spíš než rychlosti IDE. Znám lidi, kteří používají skoro holý Vim nebo holý debugger, ale vyčtou potřebnou věc rychleji než já z full-blown IDE. Vím o lidech, kteří jsou lepší programátoři než já, ale nepoužívají syntax highlighting (což třeba já osobně taky moc nechápu, ale jim to zřejmě funguje). Zkrátka: YMMV.
Ono je pak otazka, jestli clovek spravuje rozsahlejsi codebase, kterou neni mozne celou udrzet v pameti, nebo zda edituje nejake slozitejsi Hello, worldy, kde prinos IDE skutecne tolik nevynikne.Nemyslím si, že pracuju na 'složitějším Hello, world'. Projekt, na kterém pracuji, není nijak extra velký, ale je subprojektem většího projektu, jehož repo je velké přes 1GB, je tak velké protože obsahuje i kód hodně 3rd party závislostí, právě kvůli snadnosti dohledávání. Tohle všechno a nějaká další repa indexuje Woboq-like server. Když nad celým tímhle nad-repem spustím Sublime, trvá mu 4 minuty to indexovat a zabere pár set MB RAM (na mém laptopu), a to AFAIK indexuje jen adresářovou strukturu. Mam určité pochybnosti, že by tohle třeba NetBeans nebo podobné IDE rozumně zpracovalo... Hezké je, že buildovací stroje umí vyplivnout celkový cscope file, někteří kolegové to používají. Mně obvykle stačí můj lokální cscope + ten indexovací server s browser UI.
Ja take muzu nastartovat nejaky editor, otevrit konzoli s grepem a pracovat. Pouze jsem si vedom toho, ze budu pracovat vyrazne pomaleji a mene komfortne.Také jsem si toho dříve byl vědom. Už si toho vědom nejsem.
Umisteni breakpointu vyzaduje znalost konkretniho souboru a konkretniho radku, takze mi to naopak prijde velmi podobne. Jeden pri pohledu do zdrojoveho kodu rovnou vi, ze sem chce umistit breakpoint, tak zmackne CTRL+SHIFT+B, druhy se prepne do jine aplikace a udaje tam nadatluje rucne, a tak by bylo mozne pokracovat.GDB umí zobrazovat zdroják a nastavit breakpoint na řádku. Ale jinak ano, u toho debuggeru celkem beru, že se může hodit GUI. Kdyby se ale případně dal z nějakého IDE používat pouze front-end k debuggeru, bral bych to. Až na to budu mít chvilku, vyzkoušim ten Nemiver. Další věc je post-mortem analýza - tam mi IDE integrace dává ještě menší smysl, to je spíš opět na specializované nástroje jako CLI debugger nebo IDA (GUI). Ale to už jsem zase mimo svět Javy, pardon.
Přijde mi, že sis našel specielní případ, ale budiž, na tohle bude potřeba nějaká statická analýza, nicméně myslím, že cscope to dá.Tak trochu. Setkavam se s tim docela casto a nevim, jak bych to jinak (jednoduse) resil. Osobne prilis velkym zastancem vnitrnich trid nejsem, nicmene je to v Jave bezna praxe.
Když řeknu, že ViM/Emacs/Sublime + cscope nebo podobné nástroje to umí taky, tak mi předpokládám řekneš, že jsou z nich tím pádem IDE... (Což je asi i do jisté míry pravda.)Nemam s tim zadnou zkusenost, jen jsem se ted podival na nejake screenshoty. Zkusim si to nekdy rozchodit, abych mel porovnani. Blizsi popis jsi k tomu neuvedl a nemam tedy zadnou informaci, jak se to realne v praxi pouziva.
Moje zkušenost je, alespoň zatím, taková, že doba čtení zdrojáku/coredumpu/apod. závisí především na zkusnošti/schopnosti programátora spíš než rychlosti IDE. Znám lidi, kteří používají skoro holý Vim nebo holý debugger, ale vyčtou potřebnou věc rychleji než já z full-blown IDE. Vím o lidech, kteří jsou lepší programátoři než já, ale nepoužívají syntax highlighting (což třeba já osobně taky moc nechápu, ale jim to zřejmě funguje).Jinak receno - lepsi programator programuje lepe. To jsi chtel rict? :) Nijak to ale nepopira, ze s IDE by takovi programatori mozna pracovali jeste rychleji. Velmi schopny/zkuseny programator s neefektivnimi nastroji muze stale pracovat mnohem lepe/rychleji nez mene schopny/zkuseny kolega s dobrymi nastroji.
Projekt, na kterém pracuji, není nijak extra velký, ale je subprojektem většího projektu, jehož repo je velké přes 1GB, je tak velké protože obsahuje i kód hodně 3rd party závislostí, právě kvůli snadnosti dohledávání.Uz jsem mel urcite vyhrady vuci strukture toho projektu. Importovat to cele, vc. projektu v C a Pythonu, do Java IDE, povazuji za nesmysl.
Ale jinak ano, u toho debuggeru celkem beru, že se může hodit GUI. Kdyby se ale případně dal z nějakého IDE používat pouze front-end k debuggeru, bral bych to.Muzes si projekt naimportovat a IDE pouzivat pouze pri debugovani. Problem ale mozna bude uz samotny import projektu (viz predchozi diskuze o make/cmake).
a je mi to celkem jedno, klidně mě můžete považovat za neflexibilního...FYI, ja nikde nerekl, ze bys mel pouzivat IDE, nakolik detailne neznam tvoji praci. Co ja vim, jestli pises v Jave denne, nebo zasahujes do maleho projektu parkrat za mesic? Pak proste nejsi plnohodnotny developer v Jave. Mozna firme dava vetsi smysl platit si jednoho cloveka, ktery zastane vsechno, nez specialistu na kazdou technologoii (treba proto, ze by pro ne nebylo dost prace na plny uvazek). Znovu ale opakuji, ze je pak nesmysl se tu hadat o tom, ze IDE neprinasi vyssi efektivitu vyvoje, protoze ve vsech diskutovanych pripadech vysel najevo opak. Ty se hadas, ze ten vyznam je nepatrny, ale opak tvrdim ja i dalsi dva lidi zde (a vsichni tri, podle kontextu, vyvojem casu v Jave travime mnohem vic casu nez ty; ja budu vzhledem k veku zcela jiste nejvic juniorni, to jen pro uplnost). Ono kdyz neco prinese rozdil 50 %, ale pouzivas to tu a tam hodinu, tak ten absolutni prinos je velmi maly (a navic zhorseny o nutnost startovat IDE, coz si klidne par minut muze vyzadat, pokud to neco indexuje apod.). Kdyz to ale jsou desitky hodin tydne, tak uz je to znat sakra hodne. Proto jsem uz nekolikrat upozornil, ze tvoje zkusenosti jsou zde velmi malo relevantni (coz tys zrejme pochopil jako osobni utok). Predmetem diskuze porad je ta efektivita IDE, kterou ty popiras, nebo zlehcujes (na zacatku vic, postupne trochu min). Netvrdim, ze tvuj setup je nutne spatny, protoze pokud v Jave vyvijis jen velmi malo, tak je pro tebe skutecne rychlejsi to udelat v editoru, ktery mas perfektne ovladnuty, nez se prepinat do zcela jine aplikace, kde bys musel pracovat uplne jinak. Z toho ale nelze vyvozovat, ze kdyz je to neefektivni pro tebe, tak je to neefektivni pro vsechny ostatni. Tu osobni rovinu je proste nutne eliminovat a ma smysl srovnavat nekoho, kdo N casojednotek vyviji v Jave v editoru (+ separatnich nastrojich) s nekym, kdo N casojednotek vyviji v Jave v IDE.
Znovu ale opakuji, ze je pak nesmysl se tu hadat o tom, ze IDE neprinasi vyssi efektivitu vyvoje, protoze ve vsech diskutovanych pripadech vysel najevo opak.Wait, what? Měl jsem dojem, že u toho příkladu s odebráním argumentu jsme se shodli, že je potřeba editovat call site. Úplně mi pak není jasný, kde tam je to masivní zrychlení pomocí IDE. Nevím, jestli mi v rámci porovnání byl povolen cscope, nebo ne, pokud ano, tak mi přijde, že tam rozdíl není, pokud ne, bude tam jisté zdržení s grepem, to je pravda, ale vzhledem k tomu, že bude následovat ruční editace, mi to nepřišlo tak důležité. IMHO bys mohl mnohem víc oproti editoru získat třeba na přejmenování member funkce nebo tak něčeho, což Java IDE může skutečně udělat automaticky v mnoha souborech.
Proto jsem uz nekolikrat upozornil, ze tvoje zkusenosti jsou zde velmi malo relevantni (coz tys zrejme pochopil jako osobni utok). Predmetem diskuze porad je ta efektivita IDE, kterou ty popiras, nebo zlehcujes (na zacatku vic, postupne trochu min).Je pravda, že v Javě dělám teď dost málo, takže máš pravdu, že tvoje zkušenost bude mít větší relevanci, na druhou stranu ale IMHO můžu trochu extrapolovat ze zkušenosti s přechodem Qt Creator → editor, kdy jsem si myslel, že bez napovídání budu jako bez ruky (QtC má poměrně velice dobré napovídání pro C/C++), ale ukázalo se, že ne. Nejde o to, že bych chtěl zlehčovat efektivitu IDE, jsem prostě v tomhle ohledu hodně skeptik. Je to jednak z důvodu mojí vlastní zkušenosti s odchodem od IDE a jednak z toho, jak vidím lidi programovat ve svém okolí. Přínosu IDE budu věřit až když budou skutečně k dispozici data, která to potvrdí - tzn. něco jako programátor potřebuje průměrně za den udělat tolik a tolik úkonů, které je IDE schopno urychlit tak a tak. U sebe osobně cítím, že obvykle to jsou programátorské (ne)schopnosti, co mě limituje mnohem víc než absence napovídání IDE a podobné věci.
Měl jsem dojem, že u toho příkladu s odebráním argumentu jsme se shodli, že je potřeba editovat call site.Uvadel jsem priklad s nejakym flagem, ktery je vzdy true. Rikal jsem, ze je potreba projit seznam volani(*), ale kdyz uz vis, ze ten flag je vzdy stejny, muzes jeho odstraneni zautomatizovat, tj. odstrani se i ze vsech volani dane metody. * Ackoliv si ted vybavuji, ze IDE me snad nekdy informovalo i o tom, ze nejaky argument ma vzdy stejnou hodnotu... Nicmene podle zbezneho hledani se mozna pletu.
IMHO bys mohl mnohem víc oproti editoru získat třeba na přejmenování member funkce nebo tak něčeho, což Java IDE může skutečně udělat automaticky v mnoha souborech.Nechtel jsem volit ten zcela nejproflaklejsi priklad, ktery je vseobecne dobre znamy. Odebrani argumentu je mene trivialni a za (skoro) zadnych okolnosti, to nejde udelat pomoci prosteho nahrazeni. U toho prejmenovani ano za predpokladu, ze se ten nazev vyskytuje jen u dane konkretni metody (popr. lze snadno odfiltrovat nezadouci soubory).
z toho, jak vidím lidi programovat ve svém okolíTo nutne neznamena, ze to delaji nejlepsim moznym zpusobem. Schopni byt muzou, produktivni taky, ale nelze vyloucit, ze s IDE by se jejich vykonnost jeste zvysila (za predpokladu, ze by je IDE psychicky nedeprimovalo).
Přínosu IDE budu věřit až když budou skutečně k dispozici data, která to potvrdí - tzn. něco jako programátor potřebuje průměrně za den udělat tolik a tolik úkonů, které je IDE schopno urychlit tak a tak.Takova data k dispozici nikdy nebudou. Programator uzivajici IDE k reseni problemu bude pristupovat jinak nez programator bez nej. Jeden hned zapne debugger, druhy bude trochu dele koukat do kodu. Jeden zmrsenou metodu s redundantnimi argumenty zrefactoruje, druhy ji pretizi a stavajici mista ponecha bez zmeny. Jeden bude preferovat par delsich souboru, druhy vice mensich (v cemz by se tomu prvnimu hur orientovalo, protoze nedokaze tak snadno prepinat). Relevantni diskuze na Redditu.
Uvadel jsem priklad s nejakym flagem, ktery je vzdy true. Rikal jsem, ze je potreba projit seznam volani(*), ale kdyz uz vis, ze ten flag je vzdy stejny, muzes jeho odstraneni zautomatizovat, tj. odstrani se i ze vsech volani dane metody.Ok, ale stále nerozumím, co má vlastně být na tom příkladu vidět, dikuze na mě dělá dojem, že je potřeba hledat relativně obskurní příklady, aby se dokázala vysoká efektivita IDE...
To nutne neznamena, ze to delaji nejlepsim moznym zpusobem. Schopni byt muzou, produktivni taky, ale nelze vyloucit, ze s IDE by se jejich vykonnost jeste zvysila (za predpokladu, ze by je IDE psychicky nedeprimovalo).Ano, to je pravda.
Takova data k dispozici nikdy nebudou.Mohly by. Alespoň vědět, co programátor typick dělá, by bylo velmi zajímavé, a to nejen pro porovnání IDE vs editory.
Programator uzivajici IDE k reseni problemu bude pristupovat jinak nez programator bez nej. Jeden hned zapne debugger, druhy bude trochu dele koukat do kodu. Jeden zmrsenou metodu s redundantnimi argumenty zrefactoruje, druhy ji pretizi a stavajici mista ponecha bez zmeny.Přijde mi, že se snažíš dokázat, že ještě kromě neefektivity bude programátor bez IDE psát horší kód. Ty s tím fakt musíš mít hodně velký ideový problém...
Ok, ale stále nerozumím, co má vlastně být na tom příkladu vidět, dikuze na mě dělá dojem, že je potřeba hledat relativně obskurní příklady, aby se dokázala vysoká efektivita IDE...Vse jsou priklady veci, se kterymi jsem se realne setkal.
Přijde mi, že se snažíš dokázat, že ještě kromě neefektivity bude programátor bez IDE psát horší kód. Ty s tím fakt musíš mít hodně velký ideový problém...Cetl jsi tu odkazovanou diskuzi na Redditu? Nejsem sam, kdo si to mysli, a ty argument maji svuj smysl.
Píšu si... „Nikdy se nehádej se zatvrzelým Javistou. Nemá to cenu.“ :)Přijde mi, že se snažíš dokázat, že ještě kromě neefektivity bude programátor bez IDE psát horší kód. Ty s tím fakt musíš mít hodně velký ideový problém...Cetl jsi tu odkazovanou diskuzi na Redditu? Nejsem sam, kdo si to mysli, a ty argument maji svuj smysl.
Cetl jsi tu odkazovanou diskuzi na Redditu? Nejsem sam, kdo si to mysli, a ty argument maji svuj smysl.Četl, myslím, že tam jsou i lidi s vimem, celkem bez nějaké větší diskuse. V praxi jsem se opravdu nikdy nesetkal s tím, že bych já nebo kolega nechal metodu nezrefaktorovanou jen pro to, že bych neměl IDE, které to udělá za mě. Ale OK, budu tedy pod vlivem diskuse méně nepříátelský vůči IDE
Mohl bych někdy třeba nějaké zase vyzkoušet, takže děkuji různými lidem v diskusi za tipy. Akorát to asi nebude NB nebo IntelliJ, protože mi leze na nervy ta latence GUI. Ze stejného důvodu nepoužívám ViM/Emacs přes SSH, ačkoli to má jinak dost výhod.
Až bude existovat IDE, které bude 1) jazykově agnostické, 2) lehkotonážní a 3) dobře integrované s příkazovou řádkou a existujícími non-IDE-specifickými nástroji, dejte mi vědět.Lehkotonážní z pohledu let 70., 80., 90., nebo dnešního? Pokud dnešního, tak klidně Netbeans Platform – je to podvozek a modulární systém, nad kterým si můžeš postavit prakticky libovolnou aplikaci – smysl to dává u GUI aplikací, kde využiješ různá editační okna, pohledy na projekty, služby, (virtuální) souborové systémy… Jazykově agnostické to je – platforma nemá s Javou společného nic, kromě toho, že je v ní napsána – v Netbeans jsou podporované různé jazyky (tzn. existují pro ně moduly, které si můžeš zapnout) a píší se nad touto platformou i aplikace, které nemají s IDE nebo vývojem softwaru nic společného. Okno s příkazovou řádkou tam máš (zvládá i zobrazení TUI aplikací jako mc, htop a klávesové zkratky jako F10 pro ukončení mc, takže je to lepší než některé nativní terminály), ale v tom až tak velký smysl nevidím (nemusím mít všechno v jednom okně, od toho mám správce oken resp. desktopové prostředí). Netbeans podporují Ant, Maven, Makefile… ve všech si můžeš navázat nějaké akce nebo vlastní skripty a pak se ti spouští v rámci sestavení aplikace (a úplně stejně to funguje i bez IDE při sestavení jen z příkazové řádky). Pro C/C++ v Netbeans udělali velice pěknou integraci s GDB, stejně tak je tam integrovaný Mercurial, Git a SVN. V rámci Antu/Mavenu/Makefilu si pouštěj třeba Markdown procesor, nějaké externí testy, linty, nasazovací skripty, cokoli… to už je na tobě, IDE to podporuje.
Hlavně mi to ale není jasné principielně: V C, C++ a dalších jazycích se nad prací v editoru + příkazové řádce nidko nepozastavuje, je to celkem běžné. V Javě to najednou nejde efektivně.K tomuhle bych něco měl: pořiďte si do týmů pár lidí co používají Windows. A uvidíš.
(pro rozumne jazyky)
Pokud se tu chceme bavit konstruktivne, tak prosim. Pokud si chces postezovat, ze musis pracovat s technologii, ktera se ti nelibi a mozna ji ani nerozumis, tak to me uz nezajima.
kde v jave ani nevypises jake jsou tridy v "package"!Prosim?
... a smiril se s tim ze nejlepsi bude zustat u parsovani tech java zdrojaku regexama z pythonu)
PS: ano, uvedomuji si rozdil mezi statickou analyzou a reflectionds, yada yada yada ....
nemluve o dynamicke analyze, kde v jave ani nevypises jake jsou tridy v "package"!Coz je nicmene k predmetu diskuze zcela irelevantni:
... v sublime muzes pouzivat klidne stejnou statickou analyzu kodu jako pouzivaji IDE (pro rozumne jazyky)
Ano, to jsem zkousel, kdyz jsem hledal nahradu za Eclipse (kde jsem mel problemy se stabilitou).
(pro rozumne jazyky)
Napsat parser a naseptavani pro Javu je vyrazne jednodussi nez na Python, PHP, o C++ radeji ani nemluve
Teoreticky ano, v praxi je to ale o necem jinym (nemluve o dynamicke analyze, kde v jave ani nevypises jake jsou tridy v "package"!). A proto pro python mame jedi a pro javu to bez IDEcka nejde.
Význam napíšu do komentáře (panř. @param a bla bla bla). Taky bych do komentáře mohl psát, zda je to číslo, text, datum… ale proč bych to dělal, když to můžu vyjádřit strojově čitelnou formou, které rozumí IDE, kompilátor a další nástroje a kterou každý programátor snadno přečte?
To mi připomíná můj oblíbený příklad:
/************************************************************
Function: wait_for_reply
*************************************************************
Inputs: void (none)
Returns: int
Description:
************************************************************/
int wait_for_reply(long wait_time)
{
...
} /* wait_for_reply() */
Tělo funkce má 225 řádků a rozhodně z něj není na první pohled jasné, jaký je význam návratové hodnoty.
A v čem je výhoda to mít odděleně? Já vidím spíš samé nevýhody:Mně přijde, že v tom není vůbec žádný rozdíl. To, že ti dokumentaci zobrazí IDE, je úplně to samé, akorát ji zobrazuješ jiným programem. Osobně mam dokumentaci otevřenou kdykoli něco dělám a je celkem jedno, jestli to je html vygenerované ze zdrojáku nebo třeba man pages. Jestli je dokumentace integrovaná ve zdrojáku nebo ne mi opět přijde irelevantní, vývojáři musí stejně tak jako tak vynaložit úsilí, aby byla dokumentace použitelná. Co se týče statického nebo dynamického typování, je to o tom, že každé je vhodné na něco jiného. Třeba v pythonu dává IMO smysl typovat dynamicky, protože to umožňuje rychlé prototypování a boilerplate-free kód. Ono to funguje docela dobře. Samozřejmě v systémovějších jazycích na statické typování nedám dopustit.
Mně přijde, že v tom není vůbec žádný rozdíl. To, že ti dokumentaci zobrazí IDE, je úplně to samé, akorát ji zobrazuješ jiným programem.Javadoc lze psat k jakymkoliv tridam, metodam i fieldum bez ohledu na to, zda jsou soucasti nejakeho verejneho rozhrani. Kdyz chces k metode doplnit kratkou doplnujici poznamku, je lepsi pouzit ten Javadoc nez obycejny komentar. Kdyz potom debugujes svuj kod a dostanes se i do cizich knihoven (coz se mi stava dost casto), IDE ti okamzite zobrazi relevantni informace, ktere bys jinak musel vyhledavat nekde stranou. V principu je to samozrejme totez, jen je to o neco pohodlnejsi a rychlejsi.
Jestli je dokumentace integrovaná ve zdrojáku nebo ne mi opět přijde irelevantní, vývojáři musí stejně tak jako tak vynaložit úsilí, aby byla dokumentace použitelná.Dokumentace jsou ruzneho druhu a je IMHO potreba rozlisovat, o cem se bavime. Javadoc je standardizovany zpusob, jak zapsat komentar ke tride, metode nebo fieldu. Takze v praxi to muze byt treba:
/**
* @returns a number that represents ...
*/
int foo() {
// ...
}
vs.
/*
* Returns a number that represents ...
*/
int foo() {
// ...
}
Vyznamove je to stejne a jediny rozdil je tedy v tom, zda se ten komentar da alespon castecne strojove zpracovat.
Dobre IDE umi ten Javadoc aktualizovat pri refactoringu, takze kdyz napr. prejmenujes argument, prejmenuje se i souvisejici tag '@param jmenoArgumentu'. Samozrejme je nadale zodpovednost vyvojare udrzovat komentare smysluplne a aktualni - to je ale problem, ktery se vztahuje na komentare (a potazmo cely kod) obecne. Nesouvisi to tedy ciste s Javadocem.
Dalsi vec je, ze je potreba se naucit psat Javadoc rozumne. Viz:
/**
* Calculates sum of two numbers.
*
* @param a first number
* @param b second number
* @returns sum of numbers {@code a} and {@code b}
*/
int sum(int a, int b) {
return a + b;
}
To je zjevne uplne blbe. Naprosto by stacilo napsat samotne @returns - ostatni informace jsou redundantni. V tomto pripade ale ve skutecnosti neni Javadoc potreba vubec, protoze signatura metody mluvi sama za sebe. Neni potreba zaplacavat si kod takovym bordelem (parkrat jsem to tak zkusil udelat a uz nikdy vic).
Co se týče statického nebo dynamického typování, je to o tom, že každé je vhodné na něco jiného. Třeba v pythonu dává IMO smysl typovat dynamicky, protože to umožňuje rychlé prototypování a boilerplate-free kód. Ono to funguje docela dobře.Souhlasim.
/* Substracts b from a. */
function sub(a, b) {
return a - b;
}
Kdyz neuvidis telo implementace, ale pouze hlavicku funkce a komentar, dozvis se, ze provede odecteni druheho argumentu od prvniho. Vraci to ale vubec neco? Snad ano, ale jiste to nemas - zrovna tak by se vysledek mohl nekam ulozit. A uz vubec nevis, nad cim se to odecteni provadi. Asi to budou cisla. Ale jsou to doubly, nebo objekty reprezentujici komplexni cisla, nebo neco, co ti umoznuje pracovat s velkymi cisly?
/* Substracts b from a. */
int sub(int a, int b) {
return a - b;
}
Zamerne jsem ve druhem prikladu nepouzil Javadoc, aby priklady byly lepe srovnatelne. Oba kody nesou stejnou poznamku, ale ze druheho okamzite vidis, ze od integeru a se odecita integer b a funkce vraci opet integer. Ackoliv neni nikde receno, co ten integer na vystupu znamena, lze snadno odhadnout, ze to asi bude vysledek toho odcitani.
Kdyby ta funkce nevracela nic, ale ty ses jeji vystup presto pokusil ulozit do promenne, Java ti to ani nedovoli zkompilovat. Pokud to same napises v JS v nejake vetvi, ktera se spousti jen v minorite pripadu, vubec se o te chybe nemusis dozvedet.
Dalsi priklad:
function foo() {
return 5;
}
// ... jedno z pouziti
var bar = foo;
// ...
var a = bar();
console.log(a + 2);
Pak chces funkci foo zrefactorovat:
function foo() {
return "5";
}
Samozrejme vis, ze musis upravit vsechna pouziti. Kdyz grepnes 'foo()', zminovany priklad nenajdes. Kdyz grepnes 'foo', najdes ono prirazeni do promenne. Takze si musis do nejakeho TODO napsat: "nezapomenout grepnout bar". A takhle postupne do hloubky, uroven po urovni, prochazet cely kod a rucne opravit veskera pouziti.
Pokud to zapomenes opravit, co bude vysledkem?
$ js > 5 + 2 7 > "5" + 2 '52'Tohle nekomu vazne prijde jako ten spravny, moderni zpusob, jak vyvijet spolehlivy software v 21. stoleti? V Pythonu je situace o trochu lepsi, protoze sice ne staticky, ale porad je silne typovany. Misto naprosto neocekavatelneho vystupu "52" to tedy skonci vyjimkou TypeError. Presto se vse projevi az pri spusteni a je tedy potreba mit otestovane naprosto vsechny kombinace vetvi, kterymi muze exekuce protect, vc. domnele naprosto trivialnich pripadu. A nebo proste doufat, ze je to tak nejak dobre.
To chování v JavaScriptu (příp. PHP, apod.) je spíš způsobeno quirkama v těchto jazycích (hlavně quirky operátory) spíš než dynamickým typováním (i když to samozřejmě souvisí).
Snazit se zobecnovat aritmeticke funkce pomoci generik mi prijde jako velmi nestastny krok, ktery nedava nejmensi smysl - ani z hlediska prehlednosti/citelnosti kodu, ani z hlediska vykonu (protoze se bude zbytecne delat autoboxing).Autoboxing? Huh? Tady aby člověk v každém komentáři připomínal, že existují i jiné staticky typované jazyky než Java.
Jednoduse bych ty funkce pretizil. Staticke typovani pak zustava.Pointa generik je právě v tom, že nemusíš ručně psát 200 funkcí, které se liší pouze typem argumentu.
Tady aby člověk v každém komentáři připomínal, že existují i jiné staticky typované jazyky než Java.Ona se ta diskuze smerem k Jave docela dost strhla a nezvladam uz sledovat, ktere subthready vic a min.
Pointa generik je právě v tom, že nemusíš ručně psát 200 funkcí, které se liší pouze typem argumentu.Ano, samozrejme. Jako priklad jsi ale uvadel ty aritmeticke funkce, kde me nenapada moc prikladu, kde by pouziti generik bylo vyhodne. U nejakych trivialit jako je scitani poli snad ano, ale treba pro prumer uz vetsinou ani nedava smysl mit to obecne nadeklarovane pro int a long, protoze vysledek bys chtel jako realne cislo. Takze neco jako nasledujici je IMHO nesmysl:
template <T> T avg(std::vector<T> &nums) {
Spis by to melo byt:
template <T> double avg(std::vector<T> &nums) {
Jenze jakmile se vsim stejne pracujes jako s doublem a konvertujes to na nej, tak je otazka, jestli je lepsi tam rovnou neposilat doubly - nema smysl se tvarit, ze ta funkce je zcela obecna, kdyz s tou hodnotou stejne pracujes zcela specifickym zpusobem.
Jako takovy Javovsky pristup mi prijde implementace, ktera bere doubly (jako stream) a vraci double. Pro ostatni typy se udela jednoducha implementace, ktera te prvni funkce predhazuje stream prekonvertovanych hodnot.
Jako priklad jsi ale uvadel ty aritmeticke funkce, kde me nenapada moc prikladu, kde by pouziti generik bylo vyhodne.Co třeba různé min/max funkce, potom clamp nebo sgn a podobně...
Jenze jakmile se vsim stejne pracujes jako s doublem a konvertujes to na nej, tak je otazka, jestli je lepsi tam rovnou neposilat doublyTo mi nepřijde jako dobrý nápad, musel bych celý vector nejdříve konvertovat na vector doublů...
Co třeba různé min/max funkce, potom clamp nebo sgn a podobně...Beru. Ve zminovanem C++ by reseni pomoci templates bylo velmi ciste. Pokud bych si chtel usetrit psani v Jave a extremne nezalezelo vykonu, asi bych to zapsal takhle:
static <T extends Number> T min(T[] nums) {
T min = nums[0];
for (T num : nums) {
if (num.doubleValue() < min.doubleValue()) {
min = num;
}
}
return min;
}
Bohuzel to nejde pouzit pro pole primitivnich typu (int[] ti to nevezme), coz je jedna z bolesti Javy. Vyplati se preferovat Listy a boxing-classes - u vykonostne citliveho kodu by bylo potreba rozdil premerit, ale mam za to, ze jsem to uz parkrat zkousel a nijak hrozne to neni.
Jako takovy Javovsky pristup mi prijde implementace, ktera bere doubly (jako stream) a vraci double. Pro ostatni typy se udela jednoducha implementace, ktera te prvni funkce predhazuje stream prekonvertovanych hodnot.To je skutečně bohužel celkem typický Javovský přístup, kdy se vymýšlí relativně složitý objektový systém (jsou na to potřeba Streamy), a to jen pro to, že Java má retardovanou podporu pritivních datových typů. Ono totiž další výhoda té generické varianty je, že může generalizovat i ten výsledkový typ toho průměru - můžu například říct, že mi stačí float a nepotřebuju double. Nebo můžu mít vlastní datový typ.
Ale to je trochu divny argument, ne? Typy resi druh hodnoty, ale nikoliv jeji presny vyznam. Znalost typu ti muze pomoct ten vyznam pochopit, ale to je vsechno.Tohle byla celá pointa toho příkladu. Tvrdil jsi, že hlavní jsou typy. Tady máš ukázku, že typy nestačí a že dokumentace je důležitjší.
Javadoc lze psat k jakymkoliv tridam, metodam i fieldum bez ohledu na to, zda jsou soucasti nejakeho verejneho rozhrani. Kdyz chces k metode doplnit kratkou doplnujici poznamku, je lepsi pouzit ten Javadoc nez obycejny komentar. Kdyz potom debugujes svuj kod a dostanes se i do cizich knihoven (coz se mi stava dost casto), IDE ti okamzite zobrazi relevantni informace, ktere bys jinak musel vyhledavat nekde stranou.Tohle mi přijde relevantní jen pro někoho, kdo dělá jen Javu a jen v Javovském IDE (což je IMHO trochu jak smrková monokultura, ale tak zas chápu, že lidi se chtějí specializovat). Osobně IDE už nějakou dobu nepoužívám (ani na Javu), IDE a jeho vymoženosti mi přijdou těžce nadhodnocené. V práci pracuju na projektu, který je napsaný v C, Pytonu a Javě + obsahuje dost generování kódu, jde od low-level základu až po nějaké vyšší úrovně jako pluginy v Pythonu, rest api a jánevimcovšechno. Dokumentace se řeší jednotně, "bokem", pro všechny jazyky. I hobby projekty mám typicky celkem heterogenní. Mít otevřený browser s X taby různorodé dokumentace od Y různých knihoven v různých jazycích, případně man pages, to mi přijde úplně normální / úplně v pohodě. Není na tom nic špatného, naopak, člověk se naučí pracovat s různorodými technologiemu. Snažit se tohle všechno narvat do nějakého IDE by bylo akorát přítěží navíc, člověk by musel používat X různých IDE pro každý jazyk... To mi přijde lepší mít nějak příjemně nakonfigurovaný editor a nazdar.
$ tree -a FooProject/ FooProject/ |-- main.py |-- .project `-- .pydevproject 0 directories, 3 files
Create default 'src' folder and add it to the pythonpath: If you don't leave that option checked, you'll have to create the source folder(s) yourself after the project is created (which is covered in the next tutorial page)."takze bud lzes nebo ma PyDev jeste navic zasadni chyby v dokumentaci
Tak dlhá diskusia a pritom taká blbosť ...
To či použiť IDE alebo nie je obyčajná osobná preferencia (tí ktorí preferujú Javu bez IDE sú masochisti, ale je to ich vec). Nevidím dôvod presviedčať niekoho nástroj, ktorý mu nevyhovuje.
Ja som kedysi preferoval IDE, ale neskôr som prešiel na VIM s jedi (dosť dobré autocomplete pre python vrátane blbostí ako zobrazenie dokumentácie), ultisnips (snippety), fugitive (integrácia GIT), syntastic (kontrola kódu, pylint atď), python-mode (refaktoring) a mnoho ďalších pluginov. Nepovažujem to za IDE, ale mnoho funkcií sa dá používať podobne jednoducho ako z IDE (ukážka programovania).
Okrem toho podobné skrakty na manipuláciu s oknami ako vo vime mám nastavené v Awesome WM, vo Firefoxe mám vimperator, v zsh mám aktivovaný režim editácie riadku emulujúci vim, v pythone používam prompt toolkit s editáciou nastavenou na emuláciu vimu ...
Teraz keď náhodou sadnem k niektorému IDE chýba mi tam poriadny editor. Nemyslím teraz len klávesové skratky, ale napríklad možnosť vrátiť sa (undo) ku ktorémukoľvek kroku, perzistentné undo atď.
Nevidím dôvod presviedčať niekoho nástroj, ktorý mu nevyhovuje.O to neslo. Kazdy si muze pouzivat co uzna za vhodne.
mnoho funkcií sa dá používať podobne jednoducho ako z IDE (ukážka programovania)Pekne, diky. Ja momentalne zkousim pouzivat Geany, protoze na ovladani vimu si dlouhodobe nemuzu zvyknout, ale jeste jsem si nenasel cas ho poradne nastavit.
Takže mne čo vadilo, na uloženie súboru klasicky stlačím Ctrl+S a vo VIM som musel vybehnúť z editačného módu a uložiť ho, čo ma štvalo, chápem že to nebudem robiť a bude sa to dať naskriptovať, len mi unikla tá výhoda ho použiť.Tak nejak. Ta idea vice rezimu se mi svym zpusobem libi, ale na druhou stranu mi to dela potize. Ve vimu by asi clovek mel byt prevazne v prikazovem modu a pouze dle potreby jej opoustet, ale to pro me bylo nepohodlne a nechtel jsem se pred kazdym zahajenim psani prepinat do editacniho modu a pote jej zase opoustet.
Tak typicky se do editačního módu dostaneš nějakým příkazem typu "o" (open line), "c..." (change cosi) a tak dále. Ie. přestaneš nad tím uvažovat jako "chci se přepnout do editačního módu a potom udělat to a to...", ale rovnou jako "udělám to a to...".+1. Já vim taky nijak extra neumím, ale těch příkazů jsem se docela rychle naučil desítky a vůbec nad tím nepřemýšlím.
Jinak ale třeba mně osobně to taky úplně nevyhovuje, to už bych spíš šel do Emacsu, přijde mi, že má méně strmou učící křivku. Ale je to hlavně o osobní preferenci...Já mám třeba emacs v TODO. Několikrát jsem se do něj už zkoušel dostat a poměrně jsem přitom narazil, protože některé ty klávesové zkratky jsou fakt šílené, oproti tomu mi vim přišel mnemotechnický a v pohodě. Na druhou stranu když vidím u pár lidí kolem sebe co dělají v emacsu, tak chci prostě taky (teď používám Sublime).
Tak typicky se do editačního módu dostaneš nějakým příkazem typu "o" (open line), "c..." (change cosi)Tak tyhle dvě zrovna vůbec neznám.
na uloženie súboru klasicky stlačím Ctrl+S
map <C-S> :w<CR> imap <C-S> <ESC><C-S>a
Aby to fungovalo v termináli musí sa pred vimom nastaviť riadenie terminálu stty -ixon (prípadne to hodiť do bashrc). Inak za pár € sa dá kúpiť taký hardvérový pedál a nastaviť vim tak, aby bol vo vkladacom režime keď je pedál stlačený.
ESC : w q (ukončení s uložením) a ESC : w (uložení) tak nacvičené, že je mi úplně jedno, že je tam nějaký režim. Popravdě mě to zdržuje daleko méně než dialog Yes-No-Cancel, zda chci uložit změny při ukončení editoru.
Navíc díky tomu, že se vim pouští z příkazové řádky, tak ho používám prakticky stejně jako se používal editor v nortonu (akorát používám příkazy místo tabulky s adresářovou strukturou.
Ale taky u mě platí, že se v používání editoru neliší práce a domov.
Rozdiely tam sú ;) Než sa tú doženú javisti skúsim pár drobností vysvetliť:
V prvom rade presnosť autocomplete v jave je blízka 100%. V pythone záleží od konkrétneho projektu, u seba odhadujem tak 70%, vo zvyšných prípadoch sa mi zobrazia len slová použité v otvorených zdrojových kódoch.
Python má síce silnú typovú kontrolu, ale typy sú v niektorých prípadoch známe až počas behu. Existujú dialekty pythonu ako RPython, ktoré vyžadujú aby v každom bode bol dopredu známy typ premenných a to bez akéhokoľvek zápisu typov (podobne ako type inference v haskelli). V takom prípade by mal byť autocompleter pre python rovnako presný ako pre Javu. Čím viacej potom človek používa python nad rámec toho, čo je bežné v Jave tým horšie sa bude dať kód analyzovať staticky a tým menej presne bude fungovať auto complete.
To isté, čo pre auto complete platí aj pre refaktoring. Ja refaktorujem pomocou rope, ten mám vo vime nabindovaný na klávesovu skratku, takže stačí dať kurzor na symbol, ktorý chcem zmeniť, stlačiť klávesovú skratku, upraviť a rope sa postará automaticky o zmenu v zdrojových kódoch (alebo poloautomaticky keď dám review). Problém nastáva v situácii kde by som namiesto import modul.Trieda napísal vlastnú funkciu, ktorá by importovala zo stringu (Trieda = moj_import('modul.Trieda')).
Samozrejme mám tam také blbosti ako zobrazenie dokumentácie počas auto complete, zobrazenie argumentov, zobrazenie dokumentácie v novom okne klávesovou skratkou, skoky na definíciu symbolu ...
Ďalej používam ptpython/ipython, v ktorom sa môžem hrať s python konzolou, zvyčajne aj s možnosťou automatického reloadu zmenených modulov, takže môžem písať zdrojový kód a vo vedľajšom okne rovno skúšať, či to funguje správne.
Väčšinou píšem webové aplikácie, ktoré debugujem vo werkzeug, čo je debugger, ktorý sa zobrazí vo webovom prehliadači. Kedysi som sa hrel aj s wdb, ktorý funguje nie len pre webové aplikácie, ale tých píšem minimu, takže werkzeug sa mi zdá praktickejší.
Vďaka tomu, že väšina nástrojov pre Python veľmi dobre použiteľná samostatne môžem pracovať efektívne aj bez IDE. S Javou sa akosi tak predpokladá, že programátor používa IDE.
Ešte nakoniec by som spomenul, že pred vimom som používal chronologicky kwrite, quanta+ (v tom období som veľa pracoval s PHP), Eclipse, Netbeans (Java), KDevelop, a nakoniec vim. Medzitým som chvíľu skúšal PyCharm, ale to bolo v časoch keď som mal pomalý počítač a PyCharm bol schopný zobraziť progressbar po každom stlačení klávesy Inak také managovanie balíkov z virtualenv bolo v PyCharm utrpenie, automatický reload djanga viacej nefungoval než fungoval ...
Python má síce silnú typovú kontrolu, ale typy sú v niektorých prípadoch známe až počas behu.Od kdy se tomu říká silná typová kontrola, když je to výhradně za běhu a prostřednictvím duck-typingu, tedy v případě obecného Pythonu prohledáním několika hashtables na název hledaného atributu (metody)?
Anglicky sa tomu hovorí "strong typing". Python pri operáciách kontroluje typy, takže výraz "3" + 4 mi neprejde na rozdiel od takého Javascriptu, alebo PHP. Tak isto pri volaní metódy kontroluje, či volám callable objekt, alebo nie. Tu je vysvetlenie z python wiki.
python -i Python 2.7.9 (default, Mar 1 2015, 12:57:24) [GCC 4.9.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> a = 3 >>> b = 3.14 >>> print a + b 6.14Ja som chcel aby "a" bolo "int" a vyvolalo to chybu.
python -i Python 2.7.9 (default, Mar 1 2015, 12:57:24) [GCC 4.9.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> a = 3 >>> type (a) <type 'int'> >>> b = 3.14 >>> a = a + b >>> type (a) <type 'float'>Ani neriešim v akom jazyku to spôsobí ERROR, alebo WARNING, ale proste pod striktným dodržiavaním typov si predstavujem niečo iné. Premenná sa pretypovala bez jediného upozornenia.
Znova: ve kterém jazyce to takhle nefunguje a proč by to mělo dávat upozornění?Kolikrát se budeš ptát, než ti dojde, že to nikoho nezajímá?
AFAK to není přetypování, neboť float (reálné číslo, ℝ) z matematické definice můžeš zvýšit o int (celé číslo, ℤ) a výsledkem bude opět float.Programovací jazyky ovšem podle matematických definic nefungují. Navíc se tu bavíme o míchání typů a nikoliv o čístelných oborech.
Když si na tohle stěžuješ, tak si nestěžuješ na python, ale na matematiku.On si na to ovšem nestěžuje, tudíž se tato implikace neuplatní. Můžeš se zkusit místo argumentačních kliček a podivných výzev vrátit zpět k tématu? :)
Kolikrát se budeš ptát, než ti dojde, že to nikoho nezajímá?Počkat, co? Mě to přece zajímá. Vážně. To se jako nepočítám? Uměl bych najít jazyk, kde to tak být nemusí a můžeš si to změnit (to by mělo jít v py), ale žádný takový, který to dělá by default neznám. Tak se ptám.
Programovací jazyky ovšem podle matematických definic nefungují. Navíc se tu bavíme o míchání typů a nikoliv o čístelných oborech.To teda fungují, protože matematické definice jsou do nich zcela cíleně zabudované jejich autory. Zrovna tady je zabudované, že výsledkem operace x.__add__(y) je číselná hodnota zachovávající nejvíc informace. Kde v tom vidíte nějaké přetypování je mi skryto. Nedojde přitom ke změně jedné hodnoty na jinou, ale k vytvoření zcela nového objektu, který je v souladu s matematickými principy, které do pythonu byly cíleně zabudovány. Mnohem lepší otázka by třeba byla, kdy python 2.7 přetypovává int a long, což na matematice založené není a člověk to nemusí čekat.
To teda fungujíProtipříklady jsou již v diskuzi. Obávám se, že diskuze pomalu ale jistě ztrácí smysl, takže vás tu asi brzo zanechám.
Nikoho nezajímá odpovídat.Protože to je víceméně řečnická otázka. Ale je na místě, Bedňa si stěžoval, že int + float negeneruje chybu, ale žádný jazyk tohle AFAIK nedělá, dokonce ani C#, který je jinak v tomhle dost vehementní.
Bedňa si stěžoval, že int + float negeneruje chybuNestěžoval. Proto ta reakce nedává žádný smysl. On se pouze snažil revidovat definici, podle které míchání typů představuje weak typing, zatímco jeho absence strong typing.
ako keď si Python pretypuje premennú ako mu pasujePython si hodnotu nepřetypuje jak mu pasuje, float je výsledkem volání .__add__() nad intem a floatem. Co řešíš fakt nechápu - že funkce může vracet různé typy podle typů parametrů? Jinak imho pleteš dohromady dvě věci - python má silné typy/typování, nikoliv silnou typovou kontrolu. Typová kontrola je v pythonu 2.7 nulová (v 3.5 je částečně volitelná) a nechá tě udělat co se ti zachce - je na objektech, jestli umí na zadané zprávy (resp. volání metody s danými parametry) nějak reagovat. Zjistit (ale také modifikovat) se to dá až při runtime.
CTRL+A, CTRL+C, CTRL+END
a = {} if True else []
To by byl argument pro staticke typovani. Psat takhle je v naproste vetsine pripadu prasarna. Na jednu stranu to usnadnuje to prototypovani, jak bylo zminovano nekde v pocatcich teto diskuze, ale na druhou stranu je to nezadouci v produkcnim kodu. V casti pripadu by s tim mohl pomoci nejaky linter, ale jsou pripady, kdy nikoliv:
with (open("input.json")) as fin:
data = json.load(fin)
foo = data["key"] if "key" in data else 0
Pak by bylo na miste to doplnit o nejakou rucni kontrolu:
# ... foo = ensureInt(data["key"]) if "key" in data else FalseTo je ale prace navic a vetsina lidi to IMHO nedela. Dusledkem v pripade neosetreni by bylo, ze se program zacne chovat divne:
if foo > 5:
print("something")
V pripade, ze vstupni soubor bude obsahovat pod klicem "key" nikoliv int, ale string, vysledkem bude (pozdeji behem behu) tohle:
Traceback (most recent call last):
File "./foo.py", line 9, in <module>
if foo > 5:
TypeError: unorderable types: str() > int()
Staticky typovany jazyk te vede k tomu s typem pracovat co nejdriv, takze to bude v souladu s fail-fast principem. Podstatna otazka potom je, kolik lidi ty validace skutecne dela vsude, kde je to potreba, a jak moc tomu pomuzou vynucene staticke validace.
To by byl argument pro staticke typovani. Psat takhle je v naproste vetsine pripadu prasarna.On je tu ještě duck typing, který spousta lidí zřejmě nechápe a má s ním silný problém. Což by mi vůbec nevadilo, kdyby ale netahali svoje návyky do pythonu. Zrovna tenhle konkrétní příklad, kde proměnná může být buďto pole nebo dict je docela pěkný, neboť ti to může být fakt ukradené v závislosti co s tím dále děláš. Pokud například jen vypíšeš počet prvků, tak je ti to jedno. Právě lidi z javy mají příšerné tendence se strachovat ohledně toho, co by se mohlo stát, kdyby ..
foo = ensureInt(data["key"]) if "key" in data else FalseTohle je imho špatně. Pokud něco takového chceš, tak bys to rozhodně neměl psát takhle, ale formou nějakého schématu.
Zrovna tenhle konkrétní příklad, kde proměnná může být buďto pole nebo dict je docela pěkný, neboť ti to může být fakt ukradené v závislosti co s tím dále děláš. Pokud například jen vypíšeš počet prvků, tak je ti to jedno. Právě lidi z javy mají příšerné tendence se strachovat ohledně toho, co by se mohlo stát, kdyby ..S vyjimkou nejakych utility funkci moc nevim, jak casto potrebujes nad zcela libovolnym objektem zjistovat jeho velikost.
Tohle je imho špatně. Pokud něco takového chceš, tak bys to rozhodně neměl psát takhle, ale formou nějakého schématu.Bingo. Pokud soucasti nacteni toho JSONu je jeho validace proti nejakemu schematu, ktere obsahuje typove informace, tak uz to lze povazovat za mnou uvadenou rucni kontrolu.
S vyjimkou nejakych utility funkci moc nevim, jak casto potrebujes nad zcela libovolnym objektem zjistovat jeho velikost.Nejde jen o zjišťování velikosti. Můžeš přes něj třeba obecně iterovat a tak podobně.
Jen ještě obecně a zcela mimo téma: dotazy tohohle typu chceš psát jakofoo = data["key"] if "key" in data else 0
foo = data.get("key", 0)
Tohle má složitost O(1)*, zatímco ten tvůj dělá stejnou operaci dvakrát.
*Ehm, dotaz do dictu má mít O(1), ale prý ve worst case scenariu má až O(n).
Jen ještě obecně a zcela mimo téma: dotazy tohohle typu chceš psát jakoDiky, to jsem neznal.
Tohle má složitost O(1)*, zatímco ten tvůj dělá stejnou operaci dvakrát.Vidis, a ten muj kod ma taky slozitost O(1). :)
Premenná sa pretypovala bez jediného upozornenia.To neni pravda. Kdyz opomenu, ze pretypovani znamena neco uplne jineho a to co myslis ty, je zmena typu hodnoty v promenne, tak to neni nijak v rozporu se silnym typovanim. Python neni staticky silne typovany jazyk, tzn. ze promenna muze obsahovat hodnotu libovolneho typu a samotna typova kontrola se aplikuje az pri provadeni operaci:
>>> "1" + 2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: Can't convert 'int' object to str implicitlyCoz je rozdil oproti dynamicky typovanemu JavaScriptu:
> "1" + 2 '12'JavaScript jednoduse implicitne provede konverzi na jinou hodnotu tak, aby mohl operator '+' aplikovat. V tomto pripade preferoval prevedeni na string (navzdory intuitivnimu ocekavani, ze bude preferovat prevod na cislo), coz je cesta do pekel. Python tuto implicitni konverzi nepovoli. Pouze ma nadefinovany operator '+' tak, ze umi vyhodnotit nejen
[int] + [int] a [float] + [float], ale i [float] + [int] (a protoze je scitani komutativni, tak i [int] + [float]). Zda vysledku dosahne konverzi int na float uz je jeho interni zalezitost, ktera navenek nema vliv.
Dulezite je, ze tato vlastnost plati vyhradne pro aritmeticke operace, nikoliv pro vsechny operace. Dluzno podotknout, ze toto je chovani spolecne pro vetsinu C-like jazyku, vc. staticky silne typovane Javy. Napr.:
int a = 5; float b = 1.23f + a; int c = 1.0f + a; // neplatne - vysledkem je float, tj. nelze jej ulozit jako int
či sa mi vracia správna hodnotaTo je dukaz toho, ze Python neni staticky typovany, nikoliv toho, ze neni silne typovany.
či mi to niekde nepretečieTo nesouvisi s typovanim, ale s tim, jak na pocitacich funguje aritmetika. Statickou kontrolu nelze z principu provadet ve vsech pripadech a jedinou moznosti by bylo na overflow vyhazovat vyjimku (nebo jiny chybovy stav). Jedna se pak ale o beznou runtime chybu, nikoliv typovou chybu.
sa to niekde urežePriklad?
To bolo mierené na Céčko, čo som spomínal vyššie. Ale tému pokladám viac menej za viriešenú, po tom čo sme sa zhodli, že silne typová kontrola vlasne neexistuje, ale len jej odnože :)sa to niekde urežePriklad?
Dulezite je, ze tato vlastnost plati vyhradne pro aritmeticke operace, nikoliv pro vsechny operace. Dluzno podotknout, ze toto je chovani spolecne pro vetsinu C-like jazyku, vc. staticky silne typovane Javy.Tak zrovna Java v tomto případě udělá stejnou prasárnu co JavaScript, ie
"1" + 2 → "12" :-/
String (a kompilator ti neumozni s tim pracovat jinak), coz riziko chyby vyrazne snizuje. Navic se to chova vcelku konzistentne (scitani cehokoliv a Stringu bude vzdy String). S JavaScriptem, kde jsou operatory definovany pro vsechny hodnoty, a nemas zaruceno, jakeho typu bude vysledek, bych to uplne nesrovnaval.
. z PHP, tj. samostatny operator na spojovani Stringu.
+ nebo ., určitě ne na úrovni jazyka. Na jednoduché spojování stringů by IMO měla stačí funkce typu append() (v Javě AFAIK concat()), případně k tomu přetížený operátor v jazycích, které to umožňují.
Na cokoli složitějšího je IMHO lepší/čistší použít formátovací funkce.
"Vítej, " + jméno + "!".
Dovolíme tímto operátorem připojovat k řetězci další datové typy? Ano – a opět je to užitečné. Např. "Počet souborů v adresáři: " + počet nebo "Uživatel se přihlásil z adresy: " + ipAdresa (proměnná obsahuje objekt a zavolá se na něm toString()).
Je textový řetězec vyhovující výrazu [0-9]+ textovým řetězcem? Pokud ano, pak by pro něj mělo platit vše, co pro obecné textové řetězce.
Někdo by mohl namítat, že se mají používat formátovací řetězce. Ačkoli jsou užitečné, jsou často kanónem na vrabce, představují netriviální kód, který může být zdrojem chyb (ať už sám o sobě, tak jeho využití), jsou výpočetně náročnější a dále: spojování řetězců/objektů operátorem + je poměrně intuitivní a přímočaré.
P.S. ono to "1" + 2 → "12" je nebezpečné jen u jazyků s nedostatečnou typovou kontrolou, které výsledek za určitých okolností zase v tichosti převedou na číslo a umožní s ním dělat matematické operace. To pak může být slušný bordel… Ale v té Javě je výsledkem textový řetězec, který můžeš přiřadit jen do proměnné typu String (případně Object) a nestane se ti, že bys s ním pak omylem pracoval jako s číslem.
>>> print("0")
0
>>> print(0)
0
Jako asi chápu pointu, akorát mi to přijde takové nejednoznačné.
Slovo zkoumat zduraznuji, protoze informace, ktere mohou byt v Jave zcela zjevne, v jinych jazycich byt zjevne nemusi.Tady trochu čuchám klasický omyl výřečnost = čitelnost. Zkus si tuhle situaci přepsat do třeba C, Rustu a JavaScriptu (záměrně jmenuju pokudmožno různorodé jazyky), pak bude třeba lépe vidět, jaký "přínos" má znalost tohoto dizajn patternu...
Jo taky by me ten program zajimal
void foo(int[] a) {
// ...
}
void foo(int a) {
// ...
}
function foo(a) {
if (a instanceof Array) {
// ...
} else if (typeof(a) == 'number') { // "a instanceof Number" vraci false, aby byla vetsi prdel!
// ...
} else {
throw Error("Unexpected type '" + typeof(a) + "'.")
}
}
Facebook je napsany v PHP. Kdyz zacali resit, jak predchazet ruznym chybam plynoucim z toho, ze je jazyk jako takovy prilis benovelntni, vznikl jazyk Hack. Presneji receno - misto toho, aby pouzili nejaky poradny jazyk hned v ranem zacatku, pouzili dementni PHP a pote investovali mnozstvi prostredku do znovuvynalezani kola, programovani JIT pro ten jejich HHVM apod.
Jeste jsem nevidel programovaci jazyk, ktery by vubec nemel typy. Rozdil je jen v tom, jestli je pred programatorem skryvas, nebo ne. Ve vysledku je ale stejne znat musis, takze bud si je prectes primo z hlavicky funkce, nebo je musis uhodnout/najit v kodu a drzet v kratkodobe pameti. Co je asi rychlejsi a jednodussi?
Takze budes mit cast kodu napsanou se statickym typovanim a cast bez nej? Jak se rozhodnes, ktery pristup je spravny? Podle citu? A kdyz bude na projektu pracovat vic lidi, tak budou mit ten cit vsichni stejny? To je silne naivni predstava.To se dostaveme k jadru - jestli bychom meli pouzivat "a bondage and discipline language" a nebo si uvedomit ze "we are all consenting adults" a dokazeme se domluvit. V realu mam mnohem lepsi zkusenosti s tim druhym pristupem.
Proc by mel jit vubec spustit kod, ktery ti tam jako navstevu posle skrin?Related: https://www.youtube.com/watch?v=28JerOPNPII
U dynamických jazyků tam něco pošleš a ono to něco udělá, nebo spadne… to se uvidí až v době běhu a dokonce při každém volání funkce to může dopadnout jinak.NullPointerException?
Je to vidět hlavně na těch šílených class diagramech v popisech vzorů, když stačí přirozeně použít λ.Když někam napíšeš λ nebo „sem předejte funkci“, tak musíš ještě nějak napsat, co má ta funkce vracet a jaké má parametry. Diagram tříd nebo signatura metody je standardizovaná cesta, jak si tyto informace lidé předávají. Ano, tuto informaci můžeš zamlčet, ušetřit nějaké znaky/řádky a nechat ostatní ať se v tom patlají a metodou pokus-omyl zjišťují, co tam mají poslat a co z toho vypadne. Ale já dávám přednost trochu jinému stylu spolupráce.
O:-)
Uživatel svým problémům rozumí obvykle lépe než programatorJo, ale skoro nikdy se neumí vyjádřit a jen naprosté a zanedbatelné procento fakt ví, co chce (to poznáš tak, že po podepsání specifikace a naprogramování podle obrázků najednou chtěj něco jiného, než co si objednali). Jediná věc, která se mi na tohle osvědčila jsou rychlé iterace a nebrat vývoj jako tvorbu produktu, ale jako proces. Ale je pravda, že tohle jsem zas tak moc často nedělal a možná to má jiné řešení.
Uživatel svým problémům rozumí obvykle lépe než programatorTo platí pouze pokud je uživatel také (dostatečně zkušeným) programátorem. V ostatních případech sice uživatel rozumí svému problému, ale už obvykle nerozumí tomu, jak mu s tím počítač může pomoct.
tahle debata byla o významovém rozdílu v těch slovech, jestli ti to unikloTo jsem asi odignoroval, protože mi přijde, že to je jen zas další tvůj pokus o shazování programátorů/ajťáků. Měl jsem pochopitelně na mysli, že schopný výojář je schopen pochopit, co ten daný zákazník opravdu chce. Gnome nebo LibreOffice jsou v tomhle ohledu mizerné příklady, protože to není SW na zakázku, ale FOSS nabízený široké veřejnosti "as is" a když se někomu bude hodit, tak fajn, když ne, tak ne.
Nevím zda expert ale programuju 25 let. kdyz nekdo neco chce, musi umet pozadavek vyjadrittieto dve vety mi moc nejdu dohromady - to programovanie ta asi nezivi
Knihy nikoho nenaučili programovať. Naučiť sa syntax a pár poučiek je jedná vec, ale skutočné programovanie je o tom dať programu štruktúru, napísať ho tak, aby sa dal ďalej rozširovať a aby sa pri tom ostatní spolupracovníci nezbláznili.
Po naštudovaní syntaxe (napr. C) je zbytočné venovať čas knihám venovaným čistému C. Rozumnejšie bude študovať paradigmy a "správne" postupy pri programovaní. Z toho, čo som čítal mi najviac zostala v pamäti kniha Dokonalý kód (Code complete), ktorá obsahuje množstvo (často protichodných) tipov a je na čitateľovi aby si sám v praxi vyskúšal vhodné postupy.
Holt někdo má talent na programování, jiný zase na umění. Můžu přečíst milión knih na téma "Jak kreslit", ale malíř ze mně nikdy nebude. Stejně tak programátor musí hlavně umět analyzovat problém, rozdělit jej na menší úkoly, ty pak naprogramovat a spojit do funkčního celku.Oba dva imho musí hlavně dělat to, co je podstatou práce a ne o tom číst knihy. Jak se říká, když něčemu věnuješ 10 000 hodin, tak se to většinou naučíš na „dost dobré úrovni“, i když z tebe mistr možná nebude. Málokdo tomu ale těch 10 000 hodin dá, speciálně, když bude prvních 5 000 malovat sračky. U malování má spousta lidí výhody, že s tím začnou už jako děti a věnují tomu v průběhu 20 let neskutečné množství času, kde mě doslova děsí ta představa, že bych to musel udělat taky. Samozřejmě, někdo má občas obrovský talent, ale většina lidí co znám jak z malířských kruhů, tak z kruhů programátorských tomu prostě jen dá fakt hodně moc práce a času.
Nemusis se zminovat o kodovani a zvidavemu studentovi vysvetlovat, proc jeho program neumi osetrit zadane jmeno s diakritikou a vypisuje chybne pocet znaku.Na problémy s kódováním narazíš i v té Javě – resp. ne uvnitř ní, ale na rozhraní s okolním světem (soubory, síťová komunikace). Mít představu o tom, že znaky jsou něco jiného než bajty a že jsou navzájem převoditelné pomocí kódování a že těch kódování existuje víc – to je nutnost i ve vysokoúrovňových jazycích. Ale aspoň tam nenarážíš na takové hlouposti jako je neschopnost zjistit délku řetězce nebo nefungující regulární výrazy.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[]) {
char buff[256];
printf("Zadejte sve jmeno: ");
fgets(buff, sizeof(buff) / sizeof(char), stdin);
printf("Zadal jste %i znaku.\n", strlen(buff));
return EXIT_SUCCESS;
}
A vysledek:
tom@eMig:~/Desktop$ gcc hello.c -o hello tom@eMig:~/Desktop$ ./hello Zadejte sve jmeno: Tomáš Zadal jste 8 znaku.Pane uciteli, mne to nefunguje!
sizeof(char)? To [256] je počet znaků nebo bajtů?
sizeof(buff) vrátí počet bajtů.
Opět ukázka, jak „skvělý“ jazyk to je, když pro zjištění velikosti pole musíš dělat takovéhle opičárny a převádět to sem tam, místo abys zjistil počet prvků jednou metodou/funkcí.
#define BUFSZ(x) (sizeof(x) / sizeof(*x))
Člověk aby v C definoval furt to samý dokola...
Souhlas, nicméně bohatší standardní knihovna by vůbec nebyla na škodu.Tím si nejsem vůbec jistý. Už teď to funguje tak, že někteří používají ANSI IO, zatímco jiní ho zcela odmítají a používají POSIX IO, které přímo zpřístupňuje systémová volání. Přijde mi, že samotná standardizace ANSI přinesla hromadu zbytečných „nadstaveb“ nad POSIX API operačního systému a přitom neposkytuje dostatečné prostředky pro tvorbu běžných aplikací. Možná by bylo praktičtější takové věci vůbec nestandardizovat a nechat to na tvůrcích rozšiřujících knihoven. Stejně se nakonec ty rozšiřující knihovny používají už kvůli nekompatibilitě mezi OS.
Beztak si každej nadefinuje něco jako...V životě jsem nic takového nepoužil a ani netuším, k čemu by taková konstrukce byla.
Tím si nejsem vůbec jistý. Už teď to funguje tak, že někteří používají ANSI IO, zatímco jiní ho zcela odmítají a používají POSIX IO, které přímo zpřístupňuje systémová volání.Měl jsem hlavně na mysli algoritmy a datové struktury, tj. věci, které nejsou moc platformě závislé. Ale i abstrakce platformy tam IMHO má své místo. Když někomu v nějakém případě z nějakého důvodu nevyhovuje, nic mu nebrání použít nativní API na dané platformě. Zbylých 80% bude rádo za DRY.
Měl jsem hlavně na mysli algoritmy a datové struktury, tj. věci, které nejsou moc platformně závislé.Za mě čím méně se míchá standardizace nízkoúrovňového jazyka jako je C s tvorbou knihoven, tím lépe. Ve spoustě ohledech mi daleko víc vyhovuje POSIX než ANSI, ve spoustě věcech mi ani POSIX nepřijde dobrý a je prakticky nemožné ho aktualizovat. Vzhledem k tomu, že to, co ty považuješ za céčkové API používá prakticky ze všech programovacích jazyků, mi osobně přijde daleko praktičtější to API nepovažovat za součást jazyka a ideálně ani za jeden celek, nehledě na to, že to API ve skutečnosti není ani jednotně implementované a využívané. Můžeš argumentovat datovými strukturami, ale na každou datovou strukturu najdeš tunu názorů, jak by měla vypadat a proto na ně taky existuje tuna lepších či horších knihoven. Podle mě je daleko lepší se smířit s tím, že je C nízkoúrovňový jazyk a neklade žádné konkrétní nároky na datové struktury nad rámec nějakého společného pohledu na podporované stroje. A i těch obecných abstrakcí platforem existuje pro céčko hromada, stejně jako specializovaných abstrakcí. Podle mě by byla jakákoli nadbytečná standardizace u céčka chyba. Pokud se ti céčko principiálně nelíbí, nevidím důvod se ho snažit měnit. :)
Podle mě je daleko lepší se smířit s tím, že je C nízkoúrovňový jazyk a neklade žádné konkrétní nároky na datové struktury nad rámec nějakého společného pohledu na podporované stroje.To ale není vůbec nijak v konfliktu s tím, co píšu. Žádné nároky na datové struktury z jazyka C z toho neplynou.
To, že ti vyhovuje jiná knihovna než standardní je zcela v pořádku, ale nepřijde mi, že by tě v takovém případě jakkoli omezovala existující implementace ve standardní knihovně.To je všechno naprosto krásné, až na to, že zcela ignoruješ fakt, že se nejedná o implementaci, nýbrž standard, který vynucuje redundantní kód v každé implementaci daného standardu navíc ke knihovně, kterou chci skutečně použít. Tedy ve chvíli, kdy se najde tisíc takových lidí jako jsi ty a každý bude úspěšně požadovat tu svoji věc od standardní knihovny, pak bude značně přebujelá.
Tedy ve chvíli, kdy se najde tisíc takových lidí jako jsi ty a každý bude úspěšně požadovat tu svoji věc od standardní knihovny, pak bude značně přebujelá.To je ten druhý extrém.
A to v tom všichni píší takhle?Já osobně to vidím poprvé v životě.
Pořád zjišťují délky datových typůJak se to vezme,
sizeof používám v kódu relativně často, ale pouze ve spojení s vybranými funkcemi standardní knihovny (malloc(), memset(), ...) a s výsledkem typicky nedělám žádné aritmetické operace.
dělí navzájem počty bajtůK tomu nevidím důvod.
aby zjistili tak primitivní věc jako je třeba velikost poleVelikost pole není z hlediska procesoru primitivní, ale je potřeba ji buď předem definovat nebo někam uložit. K práci s dynamicky alokovaným polem program potřebuje znát adresu dynamicky alokované paměti, velikost prvku, počet prvků a z důvodu efektivity typicky ještě velikost rezervované paměti.
Neexistuje nějaká sada funkcí, která by tohle zapouzdřovala a umožňovala pohodlnější a bezpečnější práci a přitom zůstat v C?Existuje jich hromada, říká se jim knihovny. :)
Koukal jsem, že existuje i GC pro C/C++?Musí existovat, vzhledem k tomu, že je v C napsaná spousta jazyků s GC. Popravdě řečeno, když chci high level přístup, použiju Python. :)
Moment - jak tedy zjistis velikost bufferu alokovaneho na zasobniku?Velikost bufferu na zásobníku v dané funkci znám, vzhledem k tomu, že ji tam sám volím, tedy
sizeof nepotřebuju. Dělení konstatní jedničkou neprovozuju. Dělení hodnotou jinou hodnotou mi zase nedá velikost bufferu v bytech. Prostě si vůbec nejsem vědom motivace se něčím takovým zabývat, připadá mi to jako nesmysl.
Velikost bufferu na zásobníku v dané funkci znám, vzhledem k tomu, že ji tam sám volím, tedy sizeof nepotřebuju.To jsem v predchozim prispevku oznacil jako to pouziti konstanty. Jasne, chapu.
Dělení konstatní jedničkou neprovozuju.Nejsme ve sporu. Jak jsem psal, jak je to se
sizeof(char) mi uz vysvetlil kralyk. Slo by jeste argumentovat, ze uvadet vzdy sizeof, bez ohledu na konkretni typ, je vic konzistentni nez to uvadet jen pro ty typy, jejichz velikost se muze lisit (napr. u malloc to pouzit proste musis). Ze je vysledkem sizeof 1 je proste jen specialni pripad. To je ale uz subjektivni a spravny postoj k tomu neexistuje.
sizeof, zjistíš bajtovou velikost pole, zjistíš bajtovou velikost prvku, a vydělíš tyto dvě za účelem zjištění počtu prvků pole.
Franta se ptal nejspíš naprosto vážně, protože je javista a v céčku nedělá a tudíž netuší, jak moc velká pitomost to je.
Moje odpověď je tedy negativní. Taková věc se v C běžně nedělá a nepatří to mezi základní myšlenkovou výbavu céčkovského programáťora. Zdůvodnění je takové, že program má počet prvků pole za všech okolností už znát, stejně jako je tomu u javovských programů, a tedy ho není důvod počítat poměrem mezi bajtovou velikostí pole a bajtovou velikostí prvku.
To, že se k tomu navíc nepoužívá sizeof (char) je dané tím, že char (případně unsigned char či uint8_t) je bajtový číselný typ, tedy nedává smysl počítat jeho bajty.
Odpovídal jsem na otázku, zda se takto skutečně v C programuje, tedy zda se počet prvků skutečně běžně zjištuje tak, že uložíš pole do zásobníku místo do haldy, abys na něj vůbec mohl použít sizeof, zjistíš bajtovou velikost pole, zjistíš bajtovou velikost prvku, a vydělíš tyto dvě za účelem zjištění počtu prvků pole.Pak možná nejsi ta správná osoba pro zodpovězení téhle otázky. Já sice osobně ten konstrukt se
sizeof/sizeof taky moc nepoužívám, ale v 3rd party kódu jsem ho viděl už mooockrát. Napřijde mi realistické, aby se s tím céčkový programátor opravdu nikdy nesetkal.
Mimo zásobníku se to používá také na globální paměť, v nějakých low-level/embedded aplikacích celkem bežné.
Dělení hodnotou jinou hodnotou mi zase nedá velikost bufferu v bytechTam šlo o to, že jiná funkce chtěla znát počet znaků (ne bajtů), aby věděla, kolik jich do bufferu může vložit. U znaků to zrovna sedí 1:1. Ale i tak je to podivná nekonzistence – jednou funkcí si zjistím velikost v bajtech a toto číslo předám do jiné funkce jako argument, který má být podle dokumentace velikost ve znacích. A člověk si na nějakém třetím místě musí přečíst, že je to vlastně totéž a může být v klidu. Pokud by ale šlo o jiná data, musel bys to řešit (dělit).
#define BUFF_SIZE 256 // na stacku int buff[BUFF_SIZE]; // na heapu int *buff = (int *) malloc(BUFF_SIZE * sizeof(int));Velikost pameti alokovane na heapu stejne nijak (standardne) zjistit nejde, takze podobny pristup je nutne aplikovat i jinde.
#define s konstantou. Uvazoval jsem ale spis jako v Jave, takze jsem naalokoval buffer a az pri vyvstale potrebe znovu uvest jeho velikost jsem zacal premyslet, jak to udelat - tohle se jevilo jako neco, co muzu udelat instantne, bez nutnosti se vracet k predchozimu kodu a konstantu nejak pojmenovavat.
Tam šlo o to, že jiná funkce chtěla znát počet znaků (ne bajtů), aby věděla, kolik jich do bufferu může vložit.Možná v tom je ta chyba, do bufferu typicky vkládají bajty, ne unicode znaky, vzhledem k tomu, že ani UTF-8 ani UTF-16 nejsou kódování pevné šířky znaku a UTF-32 se ani v céčku běžně pro text nepoužívá.
jednou funkcí si zjistím velikost v bajtech a toto číslo předám do jiné funkce jako argument, který má být podle dokumentace velikost ve znacíchNo jo, chybná dokumentace je chybná dokumentace. Jak vůbec znaky ukládá Java? Umí správně pracovat se znaky mimo BMP a vrací skutečný počet znaků u textu, který je obsahuje? Když jsem se Javou zabýval naposled, používala UTF-16, tedy kódování s proměnnou šířkou znaku, jinými slovy kódování, kde se může lišit počet znaků od počtu jednotek stejně jako v UTF-8.
Pokud by ale šlo o jiná data, musel bys to řešit (dělit).Nemusel. Proč bys to dělal. Proč bys dělil dvě čísla, abys zjistil již známou hodnotu? Uvědomuješ si vůbec, že
sizeof funguje pouze na pole pevné deklarované velikosti?
Jak vůbec znaky ukládá Java? Umí správně pracovat se znaky mimo BMP a vrací skutečný počet znaků u textu, který je obsahuje? Když jsem se Javou zabýval naposled, používala UTF-16, tedy kódování s proměnnou šířkou znaku, jinými slovy kódování, kde se může lišit počet znaků od počtu jednotek stejně jako v UTF-8.Jak se to vezme. Metoda
length je nevraci. Spravne je to pres codePointCount (takto).
FYI: Je docela vtipne, ze shodou nahod Abicko neumi komentar obsahujici supplementary znaky ulozit. Divil jsem se, proc mi to hazi nejakou databazovou chybu a pak jsem si rikal, ze by to mohlo souviset. A ono jo - kod jsem presunul na Ideone (viz link) a postnout to razem jde.
K čemu je to dělení sizeof(char)?
K ničemu. sizeof(char) je vždy 1.
The minimum size for char is 8 bits, the minimum size for short and int is 16 bitsViz Wikipedia, StackOverflow (obsahuje i citace z relevantnich casti standardu). Ze
sizeof(char) je vetsinou 1 bajt neznamena, ze to tak je vzdy, a ze si muzes dovolit tak v C psat (a pak predpokladat, ze to proste bude vsude fungovat).
CHAR_BITS může být klidně více než 8, ale sizeof(char) je vždy 1, to je definováno standardem.
A plati to tak u vsech standardu C? ANSI C, C99, a tak dal?Ano. Standard C to bere tak, že
sizeof(char) = 1 = bajt, ie. pokud máš divný chary, máš divný bajty.
Například pokud budeš mít v implementaci char 32-bitový a int taky, potom sizeof(char) == sizeof(int) == 1.
Osobně jsem ale nikdy nepracoval s platformou, kde by CHAR_BIT nebylo 8.
sizeof(char) je zbytečné (standardem definováno jako 1), ber v úvahu, že C vzniklo (1969-1973) v době, kdy ASCII bylo žhavá novinka (1963). Situace s kódováními v C je velmi prostá: C to neřeší – všechny stringy jsou binární, ukončené nulou. Nováčkovi stačí osvětlit, že byte a znak není totéž (a že strlen na UTF-8 nefunguje). V jiných jazycích v tom bývá pěkný bordel, což je daleko horší.
Krom toho, že sizeof(char) je zbytečné (standardem definováno jako 1)To uz mi vysvetlil kralyk. Jsem rad, ze jsem chytrejsi, ale jinak je to zanedbatelny detail. Ja C nekritizoval, tj. ani ten kod jsem nepostnul jako demonstraci nejakych vnitrnich slozitosti jazyka. Na druhou stranu je potreba zminit, ze
sizeof(char) je jen jedna vyjimka a v jinych pripadech je skutecne potreba to takto delat (v opacnem pripade by sizeof nebyl vubec potreba, ze...).
ber v úvahu, že C vzniklo (1969-1973) v době, kdy ASCII bylo žhavá novinka (1963)Viz predchozi bod. Ja nekritizuji C jako jazyk a naopak si myslim, ze je navrzene (na svou dobu) velmi dobre a pro systemove programovani je to dodnes nejvhodnejsi jazyk (zvlast diky vymazlenosti kompilatoru). Moje kritika se vztahovala vyhradne na volbu C pro vyuku programovani.
Situace s kódováními v C je velmi prostá: C to neřeší – všechny stringy jsou binární, ukončené nulou.Ano, a presne tak by to melo byt. Misto
strlen by stacilo pouzit jinou implementaci, ktera zvazuje UTF-8 a program by ihned fungoval spravne.
Nováčkovi stačí osvětlit, že byte a znak není totéž (a že strlen na UTF-8 nefunguje).To je nesmysl.
char je prece zkratka od character a vsude se o tom nemluvi jako o "bajtu" (navic bys asi necekal, ze bajt bude signed), ale jako o znaku. Na bajt tu mas stdint.h a srozumitelnejsi typedef uint8_t.
Tvrzeni byte a znak neni totez je navic silne zavadejici, protoze si zvidavy student zacne klast otazku, jak je tedy ten znak reprezentovany, kdyz to neni bajt. Pokud je char bajt a znak neni bajt, tak proc mu jeho program v nekterych pripadech funguje?
Misto vymysleni obezlicek je potreba naservirovat realitu. Existuji ruzna kodovani, ktera ruznym znakum prirazuji ruzna cisla. U ASCII se kazde z tech cisel vejde do 1 bajtu, u UTF-8 do jednoho ci vice bajtu apod. Standardni C resi pouze ASCII, takze zatim pouzivejte pouze znaky bez diakritiky a nepouzivejte, prosim, emoji. Casem se naucime zpracovavat i vstupy v jinych kodovanich.
To je hrozne prece, ne?
V jiných jazycích v tom bývá pěkný bordel, což je daleko horší.Jak jsem psal vyse - rozdil je v tom, kdy se s tim setkas. Napr. v te Jave se s tim na takto jednoduchych prikladech proste nesetkas. Mohl by ti to zmrvit terminal, resp.
cmd.exe (nevim, jestli v te by to fungovalo), ale pri spusteni treba z Eclipse, ktere se na skolach s oblibou pouziva, to fungovat bude. A urcite mi prijde jednodussi rict spoustej to tak a tak, protoze kdyz to spustis takhle, tak se ten vstup spatne zakoduje nez u jednoho z prvnich programu, ktery dotycny napsal, zcela zbytecne zabihat do nesouvisejicich detailu - coz musis udelat, pokud nechces studentum od zacatku lhat.
Navic to byl jen jeden argument z mnoha.
strlen pro non-ASCII retezce, jinde to jsou problemy s pameti nebo vyssi riziko syntaktickych chyb pri kompilaci (viz muj prvni komentar na toto tema).
V podstate jsi sam priznal, ze aby bylo mozne C rozumne ucit jako prvni jazyk, je nutne v studenta v prvni fazi od tech "tvrdych" technickych detailu izolovat. Pak ale nevidim duvod, proc tedy pouzivat to C, kdyz muzes zacit treba s tim zde diskutovanym Pythonem, nebo drive take Pascalem.
V neposledni rade je ale potreba rict, ze ja na uceni nekoho neco vubec neverim a cely ten system naprosto odmitam. Verim jen na samostudium s moznosti konzultaci a v pripade oboru, ktere to vyzaduji, samozrejme i pristup do laboratori apod. Skolstvi nijak netezi z talentu a zajmu mladych lidi, ale namisto toho jim zkostnatele vnucuje to, co nekolik pomazanych hlav v prihlouplych talarech povazuje za to prave. Clovek, ktery chce tvorit hry, ma uplne jine predstavy nez nekdo, komu se libi "hackovani" a jeste jine nez nekdo, kdo chce delat weby. Jejich motivace je rozdilna, a stejne tak jsou i technologie, ktere si maji do zacatku zvolit.
Osobne bych tedy skolstvi zrusil.
Moje nazory se shoduji s temi prezentovanymi v knize Otroci bludu ve Chramu zkazy. Autor je dle meho nazoru genius a mistr slova navic.
(njn, je už trochu pozdě)
Zde to je tedy nefungujici strlen pro non-ASCII retezceOn není nefungující, jen vrací bajtovou délku, která je potřeba pro všechy paměťové operace, což je 99% kódu.
strlen sam o sobe samozrejme funguje spravne a dle specifikace, ale chybne je jeho pouziti - protoze pokud chces zjistit pocet znaku non-ASCII retezce, tak proste nemuzes pouzit strlen. Zacinajicimu programatorovi se to ale bude jevit tak, ze nefunguje ta funkce, takze jsem se vyjadril zjednodusene. Uz jsem rozebiral v jinem prispevku, ze char je prece zkratka od character, stejne jako strlen je zkratka od string length (tedy v tomto pripade "delka retezce tvoreneho chary, tj. znaky") apod.
Neni to chyba jazyka, ktery byl ve sve dobe prelomovy a dodnes je pro svuj ucel velmi dobry (ostatne uz jsem rikal, ze mym cilem neni kritizovat C jako takove). Poukazuji vyhradne na to, ze nektere veci jsou neintuivni (viz komentar, kde zminuji NULL) a pro vyuku programovani se dle meho nazoru nejedna o vhodny jazyk.
Tak jako céčko je takové jaké je... neintuitivní po mnoha stránkách, trošku i zatížené historií, standardní knihovna není úplně ideální, ale musím říct, že oproti dialektu Turbo Pascal mi céčko konečně dávalo aspoň trochu smysl, ale zase na druhou stranu jsem se musel hned naučit pracovat s debuggerem. :DPri tom prvotnim vstupu mi daval docela smysl i ten Pascal. Clovek musi pochopit spoustu veci - promenne, funkce, podminky, cykly. Tim pochopi zaklady programovani a muze jit vic do hloubky mnohem snaz.
Osobně nemám ambice stavět metodiku pro výuku programátorů ve školách a ani si neumím představit, že bych třeba metody, které fungují pro mě, zkoušel aplikovat na širokém spektru lidí. Až moc často zjišťuju, že můj workflow u čehokoliv přijde druhým divný.Ja takove ambice take nemam - zejmena proto, ze na takovy pristup vubec neverim. Viz #474 (pocinaje tretim odstavcem).
Ja takove ambice take nemam - zejmena proto, ze na takovy pristup vubec neverim.Tak já to úplně nezatracuju už jenom proto, že to je z dlouhodobého hlediska součást mojí obživy, ale sám jsem taky nenapravitelný samouk.
NAME
strlen - calculate the length of a string
...
RETURN VALUE
The strlen() function returns the number of characters in the
string pointed to by s.
Tedy pro UTF-8 nefunguje. Že to pro většinu operací vrátí hodnotu, která nic nerozbije, je díky šikovné zpětné kompatiblitě s ASCII. Ale rámeček kolem textu s tím neuděláš (a rozsypané pravé okraje dialogů v TUI programech byly před pár lety celkem běžně k vidění).
Tedy pro UTF-8 nefunguje. Že to pro většinu operací vrátí hodnotu, která nic nerozbije, je díky šikovné zpětné kompatiblitě s ASCII. Ale rámeček kolem textu s tím neuděláš (a rozsypané pravé okraje dialogů v TUI programech byly před pár lety celkem běžně k vidění).V tom co všechno je s unicode možné, to aby se prase vyznalo. Ještě jsem nepotkal nic, kde by to vracelo skutečnou šířku viditelného textu. Ala
>>> len("z̝a̳̭̱͇̹̞̬͡l̩̤̱̜̻͚͗ͣͥ̏̈́̀g͚͙̬̿͛ó̷͖͈̬̬!̴̾")
40
A to už je délka unicode stringu, nikoliv bajtů, která je v tomhle případě 74. V tomhle případě je taky trochu problém říct co je vlastně skutečná délka, protože to leze i do textu různě kolem. Pak taky různé combining znaky, ze kterých je možné sestavovat jiné znaky (japonština a čínština to afaik používá). To se má brát jako jeden, nebo víc znaků?
je jen jedna vyjimka a v jinych pripadech je skutecne potreba to takto delatNení. Pokud používáš
sizeof k něčemu jinému než počítání parametrů pro malloc(), memset() a podobných funkcí, tak nejspíš děláš něco, co nedává smysl.
Standardni C resi pouze ASCII, takze zatim pouzivejte pouze znaky bez diakritiky a nepouzivejte, prosim, emoji. Casem se naucime zpracovavat i vstupy v jinych kodovanich.Historický balast, no. Ale stačí říct, že
strlen() vrací délku v bajtech a ne ve znacích. A při použití nějaké UTF-8 knihovny není problém používat všechno, takže to není nic neřešitelného.
Není. Pokud používáš sizeof k něčemu jinému než počítání parametrů pro malloc(), memset() a podobných funkcí, tak nejspíš děláš něco, co nedává smysl.Ne, mel jsem na mysli hlavne ten
malloc apod. To zjisteni velikosti bufferu ve stylu sizeof(buff) / sizeof(int) jsem videl mnohokrat a neni to z me hlavy, ale netvrdim, ze je nutne to tak delat. Smysluplnejsi je pouzit const / #define.
A při použití nějaké UTF-8 knihovny není problém používat všechno, takže to není nic neřešitelného.To nerozporuji, naopak jsem to sam napsal. Znovu ale opakuji, ze to nepovazuji za intuitivni a vhodne pro zacatecniky.
Znovu ale opakuji, ze to nepovazuji za intuitivni a vhodne pro zacatecniky.To je otázka. Intuitivní to rozhodně není, ale zda to je nebo není vhodné pro začátečníky, to je na úhlu pohledu. Zrovna ty jako samouk zřejmě uznáváš něco jako hození do vody a takováhle překážka by tě neměla ani v nejmenším rozhodit. Organizovanou výuku to samozřejmě komplikuje, o tom žádná, ale to lze zase řešit idiomatickou výukou, kdy se studenti naučí pečlivě vybrané praktické postupy bez hluboké teorie.
To je nesmysl. char je prece zkratka od character a vsude se o tom nemluvi jako o "bajtu"To jméno je čistě historický artefakt.
char je prostě bajt, navíc je to v podstatě číselný typ, funguje na tom integerová aritmetika a má svoji unsigned verzi.
všechny stringy jsou binární, ukončené nulou.Jen je dobré vědět, že to není vlastnost jazyka, ale knihoven včetně té standardní. Jazyk samotný žádné stringy neimplementuje a knihovna umožňuje stejně dobře pracovat i se stringy nulou neukončenými (
memcpy(), memmove(), memset()).
Na problémy s kódováním narazíš i v té Javě – resp. ne uvnitř ní, ale na rozhraní s okolním světem (soubory, síťová komunikace).Uvnitř Javy s trochou "štěstí" taky - surrogate pairs.
Ale aspoň tam nenarážíš na takové hlouposti jako je neschopnost zjistit délku řetězce nebo nefungující regulární výrazy.V C se na tohle používají knihovny... příp. POSIX API má regexy pro C už dlouho...
Uvnitř Javy s trochou "štěstí" taky - surrogate pairs.+1 UTF-16 je po všech stránkách špatně při dnešních možnostech.
Ano, mnoho starsich programatoru na C zacinalo - ale v realnem modu pod MS-DOSem, kde vse bylo z technickeho hlediska mnohem jednodussi a srozumitelnejsi nez je tomu na dnesnich pocitacich a systemech.Nemyslím si, že by bylo pro programátora v userspace nutně dnešní programování v C složitější než tehdejší. Popravdě k tomu nevidím vůbec žádný důvod. Nic z toho, co zmiňuješ podle mě pro člověka, co v reálném módu neprogramoval, vůbec neplatí.
Pokud nechceš programovat embedded věci, tak C podle mě není vhodný jazyk, se kterým začínat programovat samostudiem.Jako céčkař musím říct, že je C daleko poučnější než kterýkoli jiný imperativní jazyk kromě assembleru, jehož znalost mi stále ještě citelně chybí. Python je super praktický nástroj a klidně se na něm dá začínat, ale člověk je úplně odtržený od hardware.
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz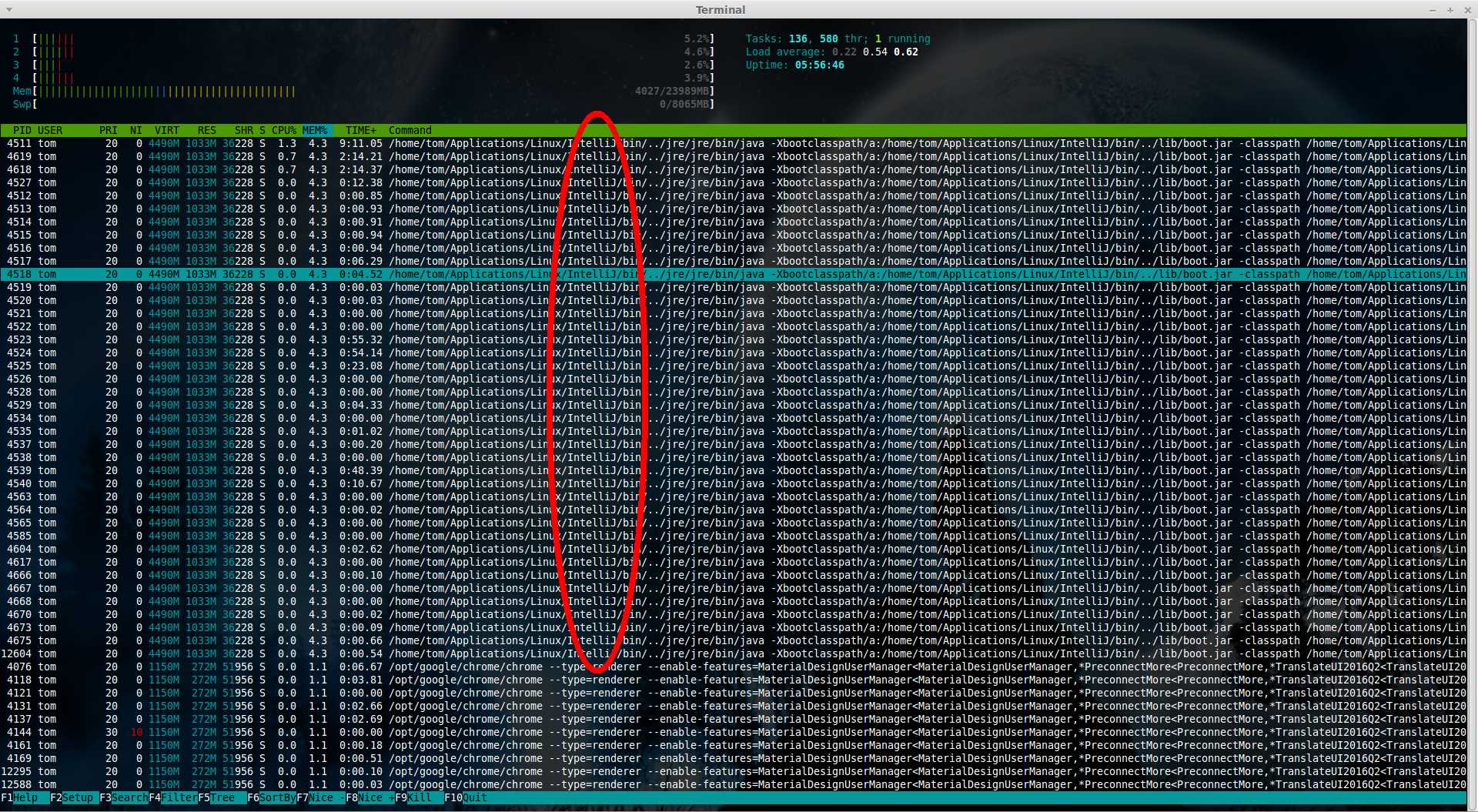{kind=link}
{kind=link}
{kind=link}
{kind=link}