Ve spolupráci společností OpenAI a Work Louder byla představena (𝕏) hardwarová klávesnice Codex Micro pro práci s AI agenty. Cena klávesnice je 230 dolarů.
Byl vydán Mozilla Firefox 153.0. Přehled novinek v poznámkách k vydání a poznámkách k vydání pro vývojáře. Řešeny jsou rovněž bezpečnostní chyby. Nový Firefox 153 bude brzy k dispozici také na Flathubu a Snapcraftu.
V linux-cve-announce bylo oznámeno 433 zranitelností za jediný den (19. července).
Byla vydána nová verze 5.44 programovacího jazyka Perl (Wikipedie). Do vývoje se zapojilo 71 vývojářů. Změněno bylo přibližně 270 tisíc řádků v 1 300 souborech. Přehled novinek a změn v podrobném seznamu.
Na 23. září 2026 je do bratislavské Nové Cvernovky naplánovaná jednodenní konference #nobullshit.camp pro tech leadery, DevOps a platform inženýry. Mají tu zaznít upřímné příběhy z praxe o tom, co v produkčních systémech reálně fungovalo, co se pokazilo a co si z toho lidé odnesli. Témata pokrývají tři oblasti – DevOps a platformy (Kubernetes, cloud, provoz systémů), firemní kulturu a leadership. Program běží ve dvou formátech: hlavní
… více »Byla vydána nová verze 1.58 sady nástrojů pro správu síťových připojení NetworkManager. Novinkám se v příspěvku na blogu NetworkManageru věnuje Josephine Pfeiffer. Vypíchnout lze možnost nmtui zobrazit nastavení Wi-Fi jako QR kód nebo podporu CLAT (464XLAT) a tunelů GENEVE (Generic Network Virtualization Encapsulation).
Zákaz používání mobilních telefonů a dalších elektronických komunikačních zařízení ve školách, jehož uzákonění navrhli jako poslanci premiér Andrej Babiš (ANO) a ministr školství Robert Plaga (za ANO), dnes podle očekávání vláda podpořila. Novinářům to oznámil Babiš, podle Plagy byla podpora kabinetu jednomyslná. Účinnost předkladatelé navrhují od 1. září 2027. Podle opoziční ODS je plošný zákaz líbivé populistické opatření namířené proti digitální gramotnosti dětí.
Vládní CERT upozorňuje (𝕏) na zranitelnost ve WordPress Core: CVE-2026-63030 s přezdívkou wp2shell. Zranitelnost typu vzdálené spuštění kódu (RCE) bez nutnosti autentizace umožňuje útočníkovi spouštět libovolný kód prostřednictvím endpointu WordPress REST API Batch. Ke zneužití není vyžadován platný uživatelský účet ani interakce uživatele. Úspěšné zneužití může vést ke kompletnímu kompromitování webové stránky a souvisejících dat. Zranitelnost postihuje verze WordPress 6.9.0 až 6.9.4 a 7.0.0 až 7.0.1.
Evropská komise (EK) vyměřila čínskému internetovému prodejci AliExpress pokutu 550 milionů eur (13,3 miliardy korun) za porušení povinností vyplývajících z nařízení o digitálních službách (DSA). Platforma podle EK řádně neposuzovala a neomezovala rizika související s prodejem nelegálních, nebezpečných nebo padělaných výrobků na svém internetovém tržišti. Komise zároveň firmě nařídila přijmout nápravná opatření. Podle AliExpressu je pokuta nepřiměřená.
Ruffle, tj. open source emulátor Flash Playeru napsaný v Rustu, byl vydán ve verzi 0.4.0. Ke stažení je také na Flathubu. Přímo ve webovém prohlížeči lze vyzkoušet online dema nebo vlastní swf soubory.
Je tomu dvacet let, co jsem "objevil" možnosti internetu. Tehdy to byla bezedná studnice informací o všem možném. A protože k ní ještě neměl přístup každý mamlas, šlo většinou o informace relevantní a cenné.
Google byl tenkrát ještě v plenkách. A o hysterii spojené s GDPR ještě nikdo ani nesnil. K vyhledávání bylo možné využít přehršle metacrawlerů, které si navzájem vysávaly svoje databáze a cílem webových stránek bylo svobodné šíření obsahu.
Pak začalo být internetové připojení stále dostupnější. Kdejaký jouda začal dělat webové stránky a pochopitelně chtěl aby pokud možno zrovna ten jeho web při vyhledávání vyskakoval pokud možno na první příčce. Na tomhle boomu se pochopitelně přiživilo plno chytráků. Výsledkem ovšem bylo pouze to, že bylo stále obtížnější nalézt stránku s relevantním obsahem, protože takoví autoři obvykle věnovali mnohem větší úsilí tomu, aby nepsali blbosti, než tomu jak dosáhnout lepšího ratingu stránky z hlediska vyhledávače. To ovšem bylo stále ještě fajn. Vhodnou kombinací slov bylo i tak možné něco najít.
Bylo to však stále těžší. Kdejaký grafoman totiž začal dělat vlastní webovou stránku a tak se záhy začaly stránky se skutečně cenným obsahem mezi těmi hromadami hnoje ztrácet. Vyhledávací portály, začaly nasazovat nejrůznější sofistikované techniky, aby oddělily zrno od plev, ovšem aby mohly zaplatit jejich vývoj, musely začít rýžovat prachy na doplňkových službách a reklamě.
Majitelé Google, však věděli, že tohle nemá smysl, dokud nezískají mezi portály dominantní postavení. Proto tímto způsobem své uživatele neotravovali a zaměřili se spíš na ty, co toužili po lepším umístění své stránky mezi nalezenými výsledky. Těm nabídli sofistikované nástroje ke šmírování návštěvnosti a také nástroje k tomu jak vylepšit obsah stránky aby získala lepší rating.
Podporovali open source, a díky nevtíravému přístupu, velké databázi a sofistikovanému vyhledávání byl tento portál u většiny vyhledávačů výchozí volbou. Jeho hvězda díky tomu stoupala výš a výš.
Klíčovým okamžikem byla investice do mobilní platformy Android. Tím, že byl provoz mobilního telefonu vázaný na Google účet, si uvázali za nohu miliony uživatelů. Čas, dojení se začal blížit. Přes Google začaly proudit miliardy dat, jejichž analýzou bylo možné zválcovat ostatní portály, které začaly postupně umírat na nedostatek financí.
Z informací poskytovaných prostřednictvím webu stal byznys. Zdroje, které byly dřív volně dostupné začaly být poskytované pouze za úplatu. Což se vcelku dá pochopit. Jenže problém je v tom, že se o nich vůbec nemusíte dozvědět, protože zůstávají skryty. A komu by se chtělo platit za zajíce v pytli, že?
Google, přes který proudily uživatelská data, mohl svého postavení využít k tomu aby je analyzoval a místo stovek stran odkazů, začal nabízek pouze nejžádanější vzorky. Většině pologramotných uživatelů internetu toto řešení typu "myslíme za vás" vyhovovalo. A to byl ten okamžik, kdy nastal konec starých časů.
Posledním hřebíkem, za který by si autor myšlenky zasluhoval nakopat do citlivých míst, byl nápad začít predikovat co uživatel vlastně hledá. Evidentně inspirovaný tím, že většina uživatelů mobilních zařízení ani neví co chce vlastně najít.
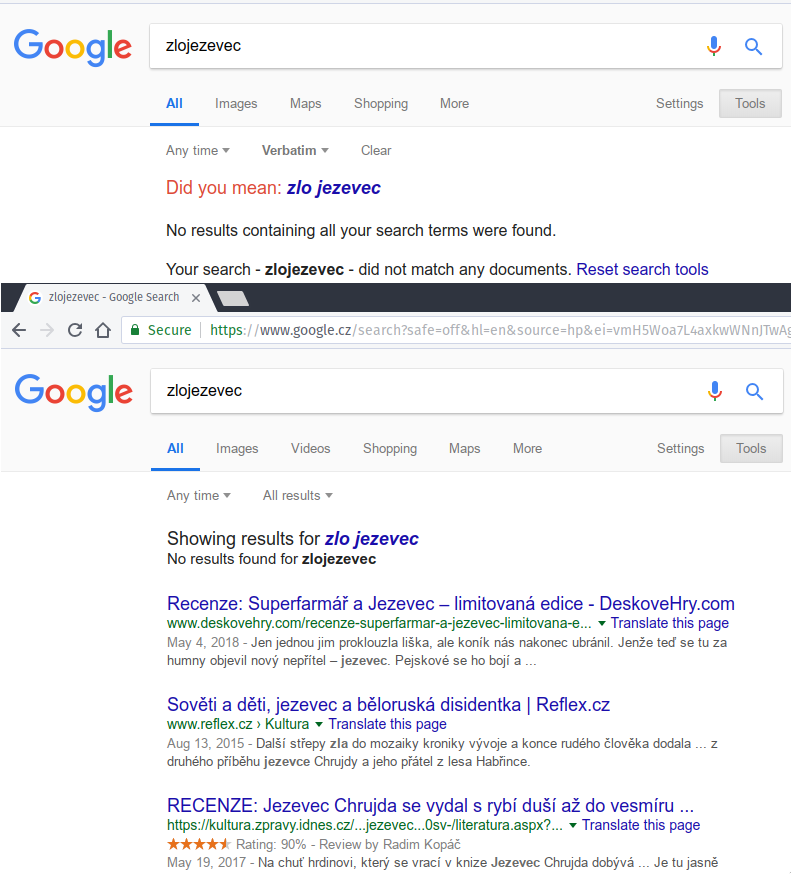
Takže místo toho, aby mi Google jednoduše napsal: "Polib si prdel, protože žádná stránka se slovem 'Niwauna' neexistuje", se mi vrací zhruba čtvrt milionu výsledků nejrůznějších zkomolenin. Počínaje webem 'iFauna'. Čímž se tedy, alespoň pro mne spolehlivě zařadil mezi nepoužitelné vyhledávače.
Samozřejmě stále ještě existují i jiné možnosti, a tak by mne a možná i jiné potěšilo, kdybyste se v diskuzi podělili s tím jak, kde a s jakým úspěchem na internetu šukáte vy.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
Polib si prdel, protože žádná stránka se slovem 'Niwauna' neexistujeDá se zapnout Verbatim režim, pak to hledá celkem rozumně. Obrázek v příloze (s jiným slovem, stránky se slovem 'Niwauna' existují).
 15.5.2018 10:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
15.5.2018 10:24
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha

A už před těmi dvaceti lety jsme si říkali přesně to, co píšeš "tehdy to byla bezedná studnice informací o všem možném. A protože k ní ještě neměl přístup každý mamlas, šlo většinou o informace relevantní a cenné."neco takoveho jsem si urcite nerikal. Rozumnych zdroju bylo pomalu a dostat se k nim bylo hodne narocne. X lidi rucne udrzovalo Y seznamu o zajimavych webovych stranach. A nevim, kdo by se chtel vratit do doby, kdy o Internetu byly papirove casopisy, kde se psalo, co se da na ktere strance najit.
K vyhledávání bylo možné využít přehršle metacrawlerůProtoze vetsina vyhledavacich enginu te doby stala uplne zaprd. Kdyz clovek neco hledal, nejdriv musel zkusit Altavistu, pak Yahoo!, pak Lycos pak treba alltheweb a mozna neco nasel. Pro cestinu tu pak byly bezne problemy se sklonovanim a casovanim a tim, ze pro kazdou stranku existovalo pet verzi, kazda v jinem kodovani cestiny. To nemluvim o tom, ze tu nebyla Wikipedia (pro ty, co chcou povrchni informace) nebo tuny vedeckych clanku, pro ty, co se zajimaji o podrobnosti. Opravdu bych se nechtel vracet tech dvacet let zpatky, protoze tehdy trava opravdu nebyla zelenejsi.
Čímž se tedy, alespoň pro mne spolehlivě zařadil mezi nepoužitelné vyhledávače.Mas dve moznosti: (1) Pokud jsi pokrocily uzivatel, muzes kliknout na odkaz: "Místo toho hledat niwauna" hned pod informaci: "Zobrazeny výsledky pro dotaz ifauna" (2) Pokud jsi IT expert a odbornik pres ty internety, muzes zadat do vyhledavani "niwuana" a Google bude hledat presne to, co chces.
A nevim, kdo by se chtel vratit do doby, kdy o Internetu byly papirove casopisy, kde se psalo, co se da na ktere strance najit.
To je třeba dneska. Místo Bravíčka vycházejí různé bizáry jako tohle. Viděl jsem i knihy v duchu „100 nejlepších videí na TyTrubko.“
Bajt je náhodou dost dobře počeštěné slovo, u kterého nehrozí záměna byte vs. bit, které se liší jen tvrdostí y/i.
"před dvaceti lety" není 1994 ale 1998Vim, tech dvacet let se vztahovalo ke Kapicove bajecnemu casu internetu. Pokud by nekdo chtel byt nostalgicky nebo se jen podivat, jak vypadal internet pred temi 20+ lety, doporucuji nahlednout do earchivu Jiriho Peterky.
Interval.cz : )
nebo obrázky na webu Pinterest, aj.
Pinterest je ta zločinná stránka, která vykrádá obsah jiných webů, a když tam vlezeš, tak tě nutí, aby ses u nich registroval? Fakt se divím, že to vyhledávače tolerují a už dávno je nevyškrtly z výsledků vyhledávání. Když hledám nějaký obrázek a odkaz z vyhledávače vede na Pinterest, považuji ho za bezcenný, protože je to k ničemu.
Facebook je taky zlo, ale tam ten obsah aspoň vkládají sami uživatelé a ve výsledcích vyhledávání mne to neotravuje.
 19.5.2018 14:03
xkucf03 | skóre: 50
| blog: xkucf03
19.5.2018 14:03
xkucf03 | skóre: 50
| blog: xkucf03
X lidi rucne udrzovalo Y seznamu o zajimavych webovych stranach.
Přijde mi, že se to zase vrací a cyklus se opakuje. Zrovna nedávno jsem narazil na jakousi iniciativu awesome, kde lidi používají GitHub k tomu, aby na něm udržovali ručně tvořené seznamy zajímavých odkazů z různých oblastí. Ještě jsem to nestihl moc prozkoumat, takže zatím to nemůžu hodnotit, ale co jsem náhodně proklikal pár odkazů, tak to celkem zajímavé bylo.
Je otázka, jak moc to může škálovat a jak se v tom dají řešit konflikty1 …asi moc ne. Ale zatím je to možná ještě ve fázi, kdy jsou tyhle seznamy užitečné.
Časem se snad objeví lepší nástroj, který bude decentralizovaný a rozložený mezi mnoho různých autorit2 z různých oborů, které budou odkazovat na zajímavý obsah. Protože zatím oba dosavadní přístupy mi přijdou jako špatné a dlouhodobě nefunkční:
a) velké korporace, které centralizují veškerou moc do svých rukou
b) anonymní masa průměrných a podprůměrných lidí namixovaných s boty a placenými agenty.
S informacemi od těch autorit bys pak pracoval přes nějaký metavyhledávač, ve kterém by sis nastavil, jak moc které autoritě věříš pro který obor. Seznamy a váhy důvěryhodnosti autorit bys mohl zase sdílet s ostatními uživateli nebo je spravovat nějakým vlastním algoritmem.
[1] např. když víc lidí bude chtít spravovat seznam pro stejnou oblast a budou mít různé názory na to, co je zajímavé
[2] autorit ve smyslu: osobností, týmů, menších firem, organizací, škol…
 14.5.2018 19:10
otasomil | skóre: 39
| blog: puppylinux
14.5.2018 19:10
otasomil | skóre: 39
| blog: puppylinux
- Netscape prohlížeč
- Yahoo Mail
- vyhledávač AltaVista na strojích Digital Equipment Corporation (Google co do možnosti parametrů vyhledávání na něj dosud nemá)
- vyhledávání v tisku (anglickém) byl BlueLight, ale už si nejsem jistý s názvem
# hledání na jen na konkrétním webu site:abclinuxu.cz Konec starých časů # hledání přesného termínu "pankáč napadl turistu" # exclude při vyhledávání porshe -skoda # buď / nebo porshe OR skoda # parsnout výsledek ještě hledaným textem hledaný text intext:užší výběr # podobně jako výše, jen parsneme title hledaný text intitle:užší výběr # hledání definice define:slunce # podpora wildcard šla * do zelí # hledat v konkrétním typu dokumentu filetype:doc ipv6 # hledat nějaké nové stránky, kde jsme ještě nebyli related:ipv6 # hledat v url allinurl:porshe skoda # hledat přímo v textu webu allintext:porshe skoda # hledání v nadpisech allintitle:porshe skoda # vyhledávání čísel v určitém rozsahu Televize Samsung model 5000..7000 # hledánív cache cache:hledaný výraz # a milion dalších věcí, včetně kombinací zmíněnýchDále google podporuje i další věci, např :
# kalkulačka 2*5/4 # stav konkrétního letu BA 181 # předpověď počasí weather prague # hledání podle obrázku image.google.com # převod jednotek 12 miles + 568 feet in m # převod měn 105EUR to czkSám i má help, jak hledat : Všechny tipy a triky.
 15.5.2018 14:35
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
15.5.2018 14:35
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
A myslím, že za tímto účelem vznikly i nějaké knihy, které měly za cíl naučit lidi hledat na google, ale už nevím. Možná mám špatnou paměť.Vznikly. Když jsem přišel na internet já, někdy v roce 2003/4, tak bylo vcelku běžnou součástí naučit se pracovat s vyhledávačem. Pokud si pamatuji, tak nás to učili i ve škole. Uvozovky pro přesný termín,
+ pro vynucené hledání konkrétního slova z fráze, OR, AND, inurl:, filetype:, site:. Časem toho jen přibylo.
Jinak zajímavější je WolframAlpha, který tyhle strukturované dotazy dotáhl o kus dál. Vůbec celý ten wolfram toolkit ti umožňuje dělat věci, jako položit dotaz na různé statistické záležitosti, jako třeba počet lidí v ČR a různé ekonomické ukazatele. Mám v plánu se s tím naučit dělat víc.
Co mi na těhle věcech vadí je, že většinou je problém do toho nacpat vlastní data, nad kterými by to umělo operovat.
holt už nejsi nejmladší no...Moc si to nemaluj, ty taky ne. Pokud má změna za cíl zpřístupnit funkcionalitu idiotům, pak jde o změnu idiotskou. Mimochodem, možnosti Google, které jsou na screenshotu hned u prvního přípěvku u mne kupř. Google vůbec nenabízí. A to prosím v ani jednom ze čtyř webových prohlížečů co používám (Chrome, Opera 12.x, Midori, Firefox). Resp. zobrazení volby Verbatim se mi jednou nějakým blíže těžko identifikovatelným postupem se mi u Midori podařilo dosáhnout. Pokud je tedy nastavení, kterým lze tohle chování vypnout zakopané tak, že se k němu nedá logickou cestou dostat, jde z mého pohledu rovněž o změnu idiotskou. O pokud ty nejsi schopen pochopit to co pochopili jiní a máš tady potřebu leštit svoje ego, je zcela v pořádku, že sis to vztáhnul i vůči sobě.
 14.5.2018 20:18
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
14.5.2018 20:18
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E

 Ja bych to nevidel tak tragicky. Kdyz se clovek nauci google opravdu pouzivat a zadavat mu spravne vyrazy, da se s nim dobrat relevantnich vysledku pomerne snadno. To, ze google chce uzivatelska data a vydelava na reklame mu ja osobne nezazlivam. Lide mu davaji data dobrovolne a kdo nechce, nemusi google pouzivat.
15.5.2018 16:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
Ja bych to nevidel tak tragicky. Kdyz se clovek nauci google opravdu pouzivat a zadavat mu spravne vyrazy, da se s nim dobrat relevantnich vysledku pomerne snadno. To, ze google chce uzivatelska data a vydelava na reklame mu ja osobne nezazlivam. Lide mu davaji data dobrovolne a kdo nechce, nemusi google pouzivat.
15.5.2018 16:50
Bystroushaak | skóre: 36
| blog: Bystroushaakův blog
| Praha
 15.5.2018 20:15
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Ta byla určená k tomu zapíjení žízně. Jinak pokud jde o volume máš nejspíš pravdu, protože si nepamatuji, že bych byl někdy z piva opilý.
To že pivo mělo tenkrát jinou, specifickou chuť, je pouze konstatování. Záleželo na mnoha faktorech byla to taková jedna velká loterie. Ale v tom bylo i to kouzlo.
Dnes je to zase hodně o lidové tvořivosti. Koho by prosimvás napadlo za komančů si vařit pivo svépomocí? To už bylo jednodušší nacpat do sudu ovoce, vykvasit a napálit šnaps.
15.5.2018 20:15
Grunt | skóre: 23
| blog: Expresivní zabručení
| Lanžhot
Ta byla určená k tomu zapíjení žízně. Jinak pokud jde o volume máš nejspíš pravdu, protože si nepamatuji, že bych byl někdy z piva opilý.
To že pivo mělo tenkrát jinou, specifickou chuť, je pouze konstatování. Záleželo na mnoha faktorech byla to taková jedna velká loterie. Ale v tom bylo i to kouzlo.
Dnes je to zase hodně o lidové tvořivosti. Koho by prosimvás napadlo za komančů si vařit pivo svépomocí? To už bylo jednodušší nacpat do sudu ovoce, vykvasit a napálit šnaps.
 14.5.2018 21:27
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Keď Google začínal pred rokmi s umelou inteligenciou vo vyhľadávaní, tak som od neho na čas ušiel a výsledky boli hrozné, dnes to robí dobre, ale snažím sa mu vyhýbať.
Predvolenú mám "kakčičku" a tá asi fakt nesleduje, pretože dáva rovnaké výsledky na rôznych počítačoch, čo sa o Google povedať nedá.
Ževraj už ani Gmail nebude potrebovať užívateľov a umelá inteligencia za vás bude písať emaily.
Podľa mňa vedomosti Google mashine sú už väčšie ako najmúdrejšieho človeka na zemi a musia ho občas obtiahnuť v serverovni palicov aby neovládol svet. To je ale len do času až umelá inteligencia skutočne ovládne svet a ten deň sa blíži. Niečo ako Pree zo seriálu Red Dwarf ktorá prediktuje kto čo povie a rozhovor sa už nemusí viesť
14.5.2018 21:27
Bedňa | skóre: 34
| blog: Žumpa
| Horňany
Keď Google začínal pred rokmi s umelou inteligenciou vo vyhľadávaní, tak som od neho na čas ušiel a výsledky boli hrozné, dnes to robí dobre, ale snažím sa mu vyhýbať.
Predvolenú mám "kakčičku" a tá asi fakt nesleduje, pretože dáva rovnaké výsledky na rôznych počítačoch, čo sa o Google povedať nedá.
Ževraj už ani Gmail nebude potrebovať užívateľov a umelá inteligencia za vás bude písať emaily.
Podľa mňa vedomosti Google mashine sú už väčšie ako najmúdrejšieho človeka na zemi a musia ho občas obtiahnuť v serverovni palicov aby neovládol svet. To je ale len do času až umelá inteligencia skutočne ovládne svet a ten deň sa blíži. Niečo ako Pree zo seriálu Red Dwarf ktorá prediktuje kto čo povie a rozhovor sa už nemusí viesť
Tak třeba úplný počátek Google. Internetové vyhledávače původně vracely nesetříděné seznamy stránek, kde se dané slovo vyskytuje, následně se pokoušely stránky třídit podle faktorů zjištěných na stránce (pokud je nějaký text na jedné stránce v nadpisu a na jiné v textu, ta první stránka se k danému textu asi vztahuje víc a byla zařazena ve výsledcích vyhledávání výš).Vzhledem k tomu, že jsem v roce 2000 pracoval jako helpdesk na Atlas.cz, bych řekl že se přinejmenším mýlíte. Atlas tenkrát vrážel ohromné prachy do zkvalitnění vyhledávání v obsahu indexovaných stránek a rozšíření databáze odkazů. Navíc tehdy zaměstnával celou skupinu lidí co manuálně procházela odkazy, jestli jsou platné a odpovídají tomu co je uvedno v popisu. S mechanismem o kterém píšete přišel Google (podle wikipedie) až v r. 2001 a k jeho reálnému nasazení došlo až o pár let později. Ale nepopírám, že sehrál klíčovou roli v tom, proč nakonec ty ostatní vyhledávací portály Google převálcoval.
Ma pravdu, predsedo. Vetsina vyhledavacu v devadesatych let (altavista a spol.) fungovala na principu, ze ze stranek vysosavala informace z meta hlavicek, title a v lepsim pripade i h1..h6 elementu. Navic casto si vyhledavace vybirali jen kratke useky textu (stranky se neindexovaly cele), protoze na to nebyla kapacita a dostatecny vykon, aby s temi daty slo pracovat.Tak třeba úplný počátek Google. Internetové vyhledávače původně vracely nesetříděné seznamy stránek, kde se dané slovo vyskytuje, následně se pokoušely stránky třídit podle faktorů zjištěných na stránce (pokud je nějaký text na jedné stránce v nadpisu a na jiné v textu, ta první stránka se k danému textu asi vztahuje víc a byla zařazena ve výsledcích vyhledávání výš).Vzhledem k tomu, že jsem v roce 2000 pracoval jako helpdesk na Atlas.cz, bych řekl že se přinejmenším mýlíte.
S mechanismem o kterém píšete přišel Google (podle wikipedie) až v r. 2001 a k jeho reálnému nasazení došlo až o pár let později.Tomu nejak nerozumim. Page a Brin publikuji clanky o novem algoritmu a vyhledavaci (cca rok 1998), naimplementuji prototyp, mezitim udelaji uspesny vyhledavac, aby ten algoritmus pouzili az par let po roce 2001...
Mi běží na localhostu searx + yacy a je to trochu záživnější než být odkázaný jenom na google. Velký bratr toho ví docela hodně, ale zdaleka ne o všecko se chce podělit. Když na webu narazím na něco extra zajímavýho tak si to můžu naindexovat sám. Plus jěště trochu upravený javascript v prohlížeči, kterým se to maličko automatizuje. K tomu všemu občas skenuju ftp, tam se dají taky najít docela poklady. Honba za informacema rozhodně nemusí být taková nuda jak se ti google snaží namluvit . Blokování reklamního bordelu a šmírovacích skriptů už dneska patří k základní hygieně.
My češi máme kutilství v krvi tak nás všelijaké ty urobsisám selfhosted nebo p2p řešení zas tak moc nevystraší. Člověk se u toho taky ledaco přiučí. Možná jsem ale jenom příliš náročný exot
15.5.2018 09:46
Dalibor Smolík | skóre: 54
| blog: Postrehy_ze_zivota
| 50°5'31.93"N,14°19'35.51"E
Není. Služby Google jsou nainstalovány, ale není je nutné využívat. Aplikace lze instalovat z jiných repositářů, než jen z Google Play.Jenže to je záležitost teprve několika posledních let, co se ty alternativní repozitáře objevily. Právě jako reakce na ten Googlí monopol. Stejně jako ty komunitní verze. Jenže ruku na srdce: kolik lidí má na svém telefonu komunitní verzi?
Jo. Také jsem chtěl. Jenže ji odpískli dřív, než šla oficiálně do prodeje.
To byla fakticky až N9.
N900 je díky komunitě použitelná v podstatě dodnes, sám pořád mám N800.
Přibližně stejně mohu prohlásit že je záležitostí teprve několika posledních pár let že nenosíte dětské pleny. Co na tom že to tak není po převážnou většinu vašeho života…
Co ty víš…
15.5.2018 18:44
otasomil | skóre: 39
| blog: puppylinux
 17.5.2018 11:00
mirefek | skóre: 6
| blog: proc_dalsi_nazev
17.5.2018 11:00
mirefek | skóre: 6
| blog: proc_dalsi_nazev
Nacházíme se v době konsolidace, v době postinternetu. Změnil se hardware a místo internetu dnes máme sociální média. V roce 1990 by nikoho nenapadlo dávat rovnítko mezi Google, Facebook nebo Amazon a internet. A to ani nemluvím o čínských korporacích, Alibabě, Tencentu nebo Baidu. Původně vznikly jako nástroje čínské vlády, dnes rostou každým dnem. Vždyť Tencent má vyšší hodnotu než Facebook! Mají tak velké množství uživatelů, že už to ani nejsou firmy, ale jakási digitální křídla čínské společnosti. Problém tak nebude v kapitalismu, ale spíš v průmyslové konsolidaci. Podobná věc se stala v bankovnictví. Dřív jste měli stovky a stovky regionálních bank, dnes jste odkázáni na pár velkých konglomerátů.
Mimochodem jsem hrozně rád, že Rozhlas tuhle rubriku má.
 19.5.2018 15:33
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
19.5.2018 15:33
JiK | skóre: 13
| blog: Jirkoviny
| Virginia
Srandičky, srandičky… V nejmenované IT firmě externí správce infrastruktury vymyslel, že z guest sítě nebudou ven pouštět UDP, protože… vlastně ani nevím proč, ale obávám se, že to bude nějaká hluboká myšlenka, jako že něco tak nestandardního stejně používají jen ti zlí hackeři a těm je potřeba zatnout tipec.
V jiné si zase nastavili firewall tak, aby důsledně zahazoval TCP pakety s RST flagem, a už několik týdnů trvají na tom, že to přece nemůže být problém, protože "si nikdy nikdo nestěžoval".
19.5.2018 21:37
xkucf03 | skóre: 50
| blog: xkucf03
Já z Guest sítě pouštím jen 80/TCP a 443/TCP
Takže IP adresy si uživatelé musí opisovat z notýsku nebo jak si přeloží doménové jméno?
Asi přes nějaký tvůj DNS server, takže pravidla nejsou jen „pouštím jen 80/TCP a 443/TCP“ ale je tam ještě nějaká sada dalších pravidel, např. to povolení DNS na servery v tvojí síti.
co se ti na tom nelíbí?
Běžnému koncovému uživateli to bude většinou asi jedno, ale jde spíš o to, že takové pravidlo nemá moc smysl pro zvýšení bezpečnosti. Ti, kdo chtějí škodit, totiž už dávno tunelují přes HTTP(S), případně i přes DNS protože mají zkušenost, že admini často jiné porty zakazují, tak se prostě přizpůsobili.
A jak je to v rámci té „Guest“ sítě? Vidí na sebe v rámci ní, nebo filtruješ i to? (tzn. všechno musí protéct přes tvůj router/firewall, nestačí tam mít obyčejný switch). Tohle mi přijde daleko důležitější, protože jinak se stroje hostů začnou napadat mezi sebou.
Smysl1 má leda tak zakázat SMTP kvůli spamu. Jinak to chce ale nějaký sofistikovanější způsob ochrany, protože samotné omezení na TCP 80 a 443 už je dneska celkem k ničemu. Bohužel je na tom vidět, jak to jde do háje – dřív býval internet pestřejší, používaly se různé protokoly, podle toho, co se kde hodí, pak začali admini blokovat porty „kvůli bezpečnosti“ a tomu se přizpůsobili autoři aplikací (i malwaru), protože chtěli, aby jejich aplikace fungovala všude a nechtěli riskovat, že někde bude zakázaný zrovna „ten jejich“ port a uživatelé si to budou vykládat tak, že „aplikace je blbá a nefunguje“ (když „ten internet přece funguje“ – na Seznam se totiž dostanou). Výsledkem je, že jsme zase na začátku, akorát si navzájem házíme klacky pod nohy, ale k ničemu to není. Když jsou všechny aplikace na HTTP(S), tak se totiž přes něj dají i z těch „Guest“ sítí napadat, takže nijak chráněné nejsou (a tobě to třeba dělá ostudu, že z tvojí sítě někdo vkládá komentářový spam na webové stránky).
[1] ovšem jen jako dočasné řešení, protože tohle je primárně chyba SMTP protokolu, resp. návrhu e-mailu jako takového, který vznikal v jiné době, kdy na sebe byli všichni hodní a měli radost z toho, že si můžou posílat zprávy na velké vzdálenosti, než aby řešili nějakou bezpečnost
Takže IP adresy si uživatelé musí opisovat z notýsku nebo jak si přeloží doménové jméno?Život musí být složitý, když člověk neumí číst, co? :)
Já z Guest sítě pouštím jen 80/TCP a 443/TCP
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz 15.5.2018 09:48
15.5.2018 09:48
 14.5.2018 19:25
14.5.2018 19:25
 14.5.2018 19:50
14.5.2018 19:50
 15.5.2018 16:03
15.5.2018 16:03
 17.5.2018 18:28
17.5.2018 18:28
{kind=link}
{kind=link}