HollowByte je zranitelnost typu Denial of Service (DoS) v kryptografické knihovně OpenSSL. Útočník může odesíláním škodlivého payloadu o velikosti pouhých 11 bajtů zaplnit paměť serveru. OpenSSL před ověřením dat vyhradí nepřiměřený blok paměti (až 131 KB). Server pak čeká na data, která nepřišla. Zranitelnost je opravena ve verzích OpenSSL 4.0.1, 3.6.3, 3.5.7, 3.4.6 a 3.0.21.
Ve španělské A Coruñě probíhá GUADEC 2026, tj. letošní konference vývojářů a uživatelů desktopového prostředí GNOME. Videozáznamy přednášek jsou k dispozici na YouTube.
Společnost Collabora ve spolupráci s Valve vyvíjí Holo Core, tj. port Arch Linuxu pro ARM64 procesory (AArch64), který bude pohánět VR headset Steam Frame. Pro testování Arch Linuxu pro AArch64 jsou k dispozici binární balíčky, zdrojové kódy i kontejner pro Docker nebo Podman.
Mikroprocesor Zilog Z80 byl oficiálně uveden na trh před 50 lety, tj. v červenci 1976. Výroba mikroprocesoru skončila v roce 2024.
Výzkumníci ze společnosti ESET objevili 11 zapomenutých UEFI shim zavaděčů, které byly podepsány společností Microsoft, a které umožňují útočníkům obejít ochranu UEFI Secure Boot na většině zařízení. Microsoft je zneplatnil (přidal jejich hash do databáze dbx) v rámci aktualizace Patch Tuesday dne 9. června 2026. Uživatelé Linuxu mohou databází aktualizovat pomocí LVFS. Ověřit zneplatnění zavaděčů lze pomocí skriptu uefi-dbx-audit. Jedná se o CVE-2026-8863 a CVE-2026-10797.
pico-usb-wifi je open source firmware pro Raspberry Pi Pico W, který jej promění v USB Wi-Fi adaptér. Po připojení k počítači se objeví jako zařízení USB CDC-NCM.
Americká společnost Google ze skupiny Alphabet bude muset podle nových požadavků Evropské unie umožnit společnosti OpenAI i dalším konkurentům v oblasti umělé inteligence (AI) a internetových vyhledávačů přístup ke svým službám. Ve svém rozhodnutí o tom včera informovala Evropská komise (EK). Opatření má zajistit dodržování pravidel, jejichž cílem je omezit v EU tržní sílu velkých technologických firem. Google s tím nesouhlasí.
… více »Nové verze webových prohlížečů Chrome a Firefox jsou vydávány každé 4 týdny. Aktuální verze Chrome je 150. Aktuální verze Firefoxu je 152. V březnu bylo oznámeno, že od září přejde Chrome na dvoutýdenní cyklus vydávání verzí. To by znamenalo, že Chrome v číslování verzí Firefox brzy přeskočí. Vývojáři Firefoxu proto také od září přecházejí na dvoutýdenní cyklus vydávání verzí. :-)
Microsoft Comic Chat (Wikipedie), tj. grafický IRC klient z devadesátek, který převáděl konverzace na IRC do podoby komiksových panelů, a který zpopularizoval font Comic Sans, je dnešním dnem open source. Zdrojové kódy jsou k dispozici na GitHubu pod licencí MIT.
Byla vydána (𝕏) nová verze 26.7 open source firewallové a routovací platformy OPNsense (Wikipedie). Jedná se o fork pfSense postavený na FreeBSD. Kódový název OPNsense 26.7 je Xenial Xenops. Přehled novinek v příspěvku na fóru.
Tenhle zápisek se původně měl jmenovat „Konečné řešení diakritické otázky“, ale nakonec jsem si řekl, že tak bulvární titulek nemám zapotřebí a že si zápisek snad přečtete i bez toho. Jedná se o možné řešení sporu mezi zastánci psaní s diakritikou a bez ní na tomto serveru.
Jedním z hlavních argumentů cestinaru (lidé kteří zásadně píší bez diakritiky) je, že čtenář může mít nějaké obskurní zařízení, na kterém si nepřečte české znaky – a oni jsou tedy takoví dobráci, že kvůli němu píší bez diakritiky, aby mu čtení umožnili.
Sice mám také jedno takové obskurní zařízení (PSP), které nemá česká písma, ale přesto si myslím, že bychom měli dát přednost té většině, která si české znaky zobrazit umí (jde to i v terminálu, takže málokdo přijde zkrátka). Co kdybychom tedy měli dvě verze Ábíčka – jednu s diakritikou a druhou bez?
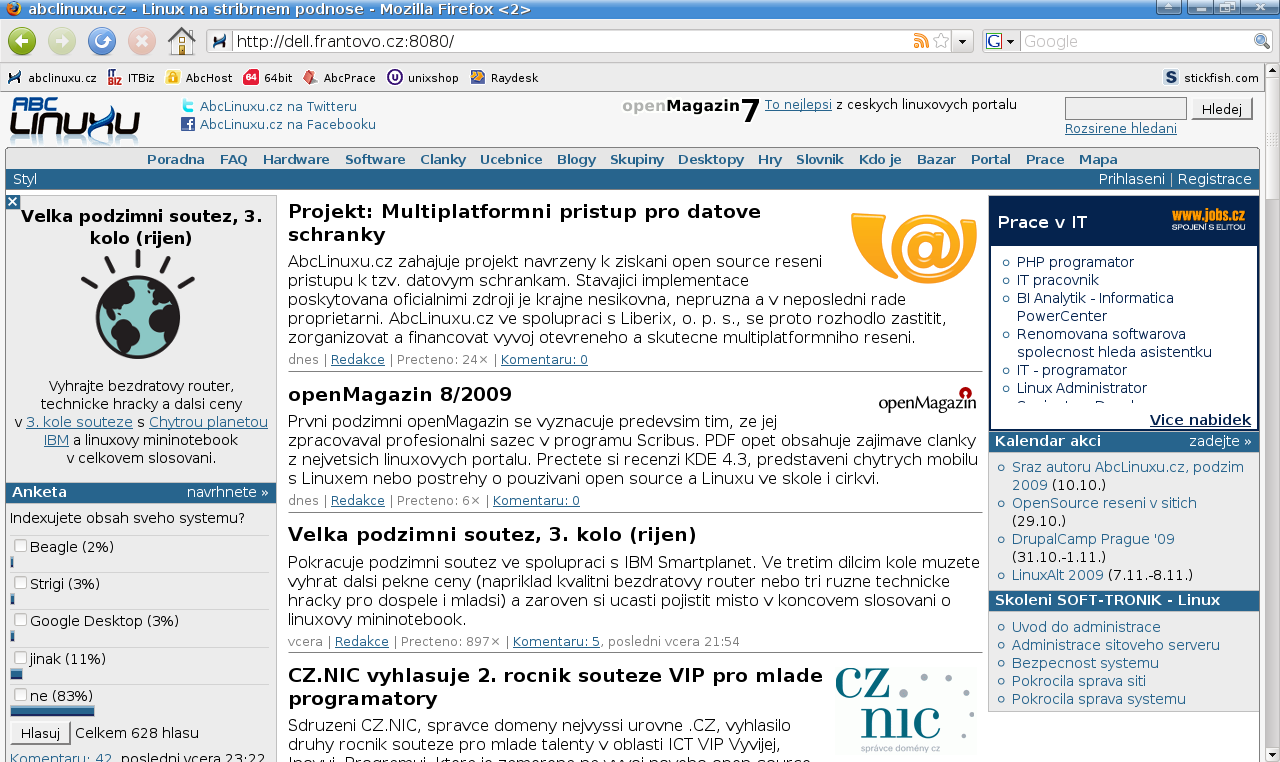
Napsal jsem v javě Filtr (javax.servlet.Filter), který diakritiku odstraňuje. Pokud neznáte Javu a servlety, filtr si prostě představte jako unixovou rouru, kterou se proženou na serveru všechny stránky před tím, než se odešlou klientovi.
Filtr odstraňuje diakritiku na výstupu, což znamená, že v databázi klidně může být → takže můžeme psát komentáře a blogy česky nikoli cesky a kdo má hloupý počítač nebo prohlížeč, ten si zobrazí verzi bez háčků a čárek a všichni budou spokojení. Výsledek můžete vidět na přiloženém obrázku.
Pro odstranění háčků a čárek jsem použil tento jednoduchý trik:
String text = "čeština";
text = Normalizer.normalize(text, Form.NFD).replaceAll("[^\\p{ASCII}]", "");
// text je teď: "cestina"
Daly by se vymyslet i jiné kousky, jako třeba převod na czestinu nebo na haaczky a czaarky (nebo by se ten text dal rovnou L0wísKOvAt  ).
).
Vypadá to sice funkčně, ale je na tom ještě dost práce – hlavně:
Zatím je to spíše takový hack a do produkční kvality to má ještě daleko. Zásadní otázka tedy je: bude to někdo používat? Má cenu do toho investovat práci (ať už mojí nebo někoho jiného)? Vyjádřete se prosím v anketě.
Tiskni
Sdílej:
![]()
![]()
![]()
![]()
![]()
![]()
 6.10.2009 00:58
Salamek | skóre: 22
| blog: salamovo
6.10.2009 00:58
Salamek | skóre: 22
| blog: salamovo
 6.10.2009 06:41
Petr Tomášek | skóre: 39
| blog: Vejšplechty
6.10.2009 06:41
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Číslovky neuměj používat ani v televizi. Je k neuvěření, co všechno schválilo sto jedna poslanců, místo sto jeden poslanec.
A co jako? Jazyk se vyvíjí, na tom není nic špatného. Jen dement si myslí, že jazyk je to, co „definovala“ banda tupců někde na ÚJČ AV...
Nejvíc směju všem co se snaží psát supeokorektní češtinou a klidně napíšou "by jste", místo byste ...
Jistě, to je jen důsledek toho, jak jsou lidé zblblí z tzv. „pravidel pravopisu“. (P.S. v češtině bývá sloveso „smát se“ zvratným. By mě fuckt zajímalo, co si představujete pod spojením „smát někomu“...)
Píšu vždy a všude s diakritikou (SMS zásadně neposílám)
Když je někdo debil, tak proč ne...
6.10.2009 09:49
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Ono ani těch sto jedna poslanců už pokud vím špatně není. I když ve "vyšším stylu" (či jak tomu nadávají) se pořád upřednostňuje forma sto jeden poslanec. Ovšem ve srovnání s tím, jaké hovadiny naši poslanci schvalují, je toto problém navýsost triviální.
To je právě ten nesmysl. V jazyce není špatně, či dobře (vyjma skutečných chyb, např. když se někdo přepíše, samozřejmě), je jen srozumitelně × nesrozumitelně, resp. běžně × zvláštně (nebo i divně). Bohužel mám pocit, že většina lidí tady ještě žije v době osvícenského absolutismu, kdy si panovník osoboval právo předepisovat lidem i to, jak mají mluvit a psát...
6.10.2009 10:36
Petr Tomášek | skóre: 39
| blog: Vejšplechty
„Pravidla“ jsou naprostý nesmysl, právě proto, že to vytváří iluzi, že je něco „špatně“ a něco „dobře“. (Kua, to tomu nemůžou říkat aspoň „doporučení“...)
 6.10.2009 11:03
Petr Tomášek | skóre: 39
| blog: Vejšplechty
6.10.2009 11:03
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Ale to je naprostá volovina. K tomu, abychom se dorozumněli, žádná „pravidla“ (ve smysmu oficiálního dokumentu) nepotřebuje. Jazyk sám má mechanizmy, jak se sám udrží srozumitelný dané skupině lidí. Tohle je jen další příklad státní buzerace...
Jen dement si myslí, že jazyk je to, co „definovala“ banda tupců někde na ÚJČ AV...
Nechci se vyjadrovat o tom, kdo si mysli, ze na AV jsou tupci. Jeste neni po 22 hodine ...
A co jako? Jazyk se vyvíjí, na tom není nic špatného. Jen dement si myslí, že jazyk je to, co „definovala“ banda tupců někde na ÚJČ AV...A, koukám, že pán jest odborník a navíc mimořádně bystrý. Ti "tupci z ÚJČ AV", jazyk spíše popisují, než definují. Také proto se pravidla jednou za čas aktualizují. A když už jsme u toho, mě nijak tupí nepřijdou. To mě spíše dráždí třeba místopisná komise pražského magistrátu, jejíž členové trvají na tom, že oni (na rozdíl od "tupců z ÚJČ AV) z moci úřední budou psát tak, jak se to naučili v padesátých letech ve škole (psaní velkých písmen v názvech veřejných prostranství). Nedodržováním pravidel ztěžují život lidem i firmám, protože ti obvykle mají sklon psát spisovně, ale taková adresa úředně podle magistrátu neexistuje.
Když je někdo debil, tak proč ne...Koukám, že jste nejenom bystrý a inteligentní, ale zejména slušně vychovaný. Na takové kultivované a věcné příspěvky je radost pohledět.
 6.10.2009 18:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 18:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Když je někdo debil, tak proč ne...A je debil proto, že píše zásadně s diakritikou, nebo proto, že neposílá SMS?
6.10.2009 19:09
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Je debil, protože na prkotinách, na kterých houby záleží, klade takový důraz, že je „zásadně“ nedělá :)
Je k neuvěření, co všechno schválilo sto jedna poslanců, místo sto jeden poslanec.Ale to je snad povolené dubleto?
6.10.2009 07:04
Petr Tomášek | skóre: 39
| blog: Vejšplechty
...nebo chybné psaní číslovek, "píše všemi 10ti prsty [čti desetiti]" (rozlišujeme řadové číslovky psané s číslicí tečkou a všechno ostatní psané číslicí. Opravdu netuším, co je na tom tak složitého).
Číst to jako „desetiti“ může opravdu jen debil. Tento způsob psaní koncovek je naprosto v souladu s evropskou a českou typografickou tradicí. Již ve středověké latině bylo běžné psát takto pádové koncovky (např. „dni isū chrī“ = „dominī iēsū christī“), v češtině byl takovýto způsob způsob zápisu běžný např. v 16. století (možná i jindy, nikdy jsem to víc nezkoumal). To, že se to nelíbí nějaké jazykové kryse a podobným vopruzencům, ještě nic neznamená.
Třeba, že někdo "ztratí data díky chybě" (to je asi ztratit chtěl nebo co) ...
Ano, to mi taky vadí. Ani ne tak proto, že bych měl nějaký problém s tím, že ve významu slov dochází k posunu, to je naprosto přirozené; ale štve mě, že lidi nepřemýšlejí o tom, co mluví a nevšímají si konotací, která slova mají. (A v tomto případě je skutečně „díky“ a „děkovat“ tak strašlivě okaté, že to až bolí...)
Číst to jako „desetiti“ může opravdu jen debil.Jen debil to tak může napsat. To nesmyslné čtení tam bylo uvedeno jen proto, aby autor komentáře poukázal na to, jak to nedává smysl.
Tento způsob psaní koncovek je naprosto v souladu s evropskou a českou typografickou tradicí.Ale houby. Nejenže je to špatně, ale především to prostě nedává smysl. Podobným doplňováním koncovek jednak vytváříš patvary (*), ale také automaticky předpokládáš, že je čtenář blb, který nedokáže danou číslovku sám skloňovat, a proto mu musíš pomáhat tou koncovkovou nápovědou. * 10ti = 'dese' + 'ti'? Takže obyčejných 'deset' bys podle takové logiky měl psát jako '10t', ne?
6.10.2009 18:53
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Stát s deseti milióny, čtyřmi sty devadesáti čtyřmi tisíci a dvěma sty třiceti osmi občany.Zpětné dekódování číslovky z toho mi přijde dost nepraktické.
6.10.2009 22:38
Jendа | skóre: 78
| blog: Jenda
| JO70FB
.
10 494 238 mi přijde v textu vhodnější než to rozepisovat. Už jenom třeba proto, že porovnání a jinou hodnotou je IMHO jednodušší.
6.10.2009 09:04
Petr Tomášek | skóre: 39
| blog: Vejšplechty
...ale také automaticky předpokládáš, že je čtenář blb, který nedokáže danou číslovku sám skloňovat, a proto mu musíš pomáhat tou koncovkovou nápovědou. * 10ti = 'dese' + 'ti'? Takže obyčejných 'deset' bys podle takové logiky měl psát jako '10t', ne?
Takže angličani jsou pitomci, když píšou řadové číslovky jako 1st, 2nd, 3rd...? A lidé ve středověku a začátku novověku byli hlupáci, když takto (s „nápovědou“) psali zkratky?
Tento způsob psaní koncovek je naprosto v souladu s evropskou a českou typografickou tradicí.Ale houby. Nejenže je to špatně, ale především to prostě nedává smysl. Podobným doplňováním koncovek jednak vytváříš patvary (*)...
To jen ukazuje, že jsi naprosto nepochopil, jak tento způsob zápisu funguje. Nejenže se nejedná o to, že by se ke slovu prostě přidala koncovka (např. v latině „dnum“ tj. [dominum] je odvozeno od „dominus“ a přesto by naprosto nikoho nenapadlo to číst jako „dominusum“), dokonce se ani nemusí jednat o to, že by k základu/kořeni slova byla přidána koncovka (viz anglické „3rd“, kde přeci „r“ patří ještě ke koření[„three“]). Smyslem tohoto systému zápisu zkratek je napovědět, v jakém přesně tvaru (pádu) slovo je, přičemž se napíše tolik písmen, aby čtenáři bylo zřetelné, o jaký tvar se jedná.
6.10.2009 09:52
Petr Tomášek | skóre: 39
| blog: Vejšplechty
kde přeci „r“ patří ještě ke koření
He, překlep, samozřejmě to patří ke kořeni...
 6.10.2009 11:05
xkucf03 | skóre: 50
| blog: xkucf03
6.10.2009 11:05
xkucf03 | skóre: 50
| blog: xkucf03
A psát to bez háčků a čárek, tak i kdybys tam překlep neudělal, museli bychom se domýšlet, jestli se jedná o kořen nebo koření.
6.10.2009 11:14
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Ano, proto má zápis bez diakritiky u mě velké sympatie; protože bystří mozek a umožňuje daleko víc jazykových hříček  .
.
(Ale je pravda, že to může být důsledek mého studia semitských jazyků, které se jak známo píšou většinou bez samohlásek, čili nabízejí daleko více zábavy .
6.10.2009 18:56
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Ano, proto má zápis bez diakritiky u mě velké sympatie; protože bystří mozek a umožňuje daleko víc jazykových hříčekJenže občas je s tím fakt docela problém a nejde to odvodit z kontextu (např.).
6.10.2009 19:12
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Průměrně bystrý člověk pak třeba napíše do závorky vysvětlení (např. „hackujici server (tj. server, ktery prida diakritiku)“), nebo věc opise jinak. Ovsem v citovanem priklade je stejne vec jednoznacne zrejma z kontextu (jen to chce precist cele)...
6.10.2009 19:20
xkucf03 | skóre: 50
| blog: xkucf03
napíše do závorky vysvětlení (např. „hackujici server (tj. server, ktery prida diakritiku)“), nebo věc opise jinak.
Tím padá další argument, proč nepoužívat diskritiku – když musím psát více textu, nějaké závorky a vysvětlení, nemůže to být rychlejší než psát s diakritikou.
6.10.2009 19:38
Jendа | skóre: 78
| blog: Jenda
| JO70FB
diskritikuOMG (tady už překlep mění význam). Nainstaluj si spellchecker, fakt to pomáhá
. Tedy mimo extrémních případů (být, bít, sýru, síru).
6.10.2009 20:04
xkucf03 | skóre: 50
| blog: xkucf03
já ho tu mám, ale v tom WYSIWYGu nefunguje.
6.10.2009 11:11
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Pitomec zřejmě jsi, nebo neumíš číst. Já jsem dokládal, že zápis typu „10ti“ odpovídá způsobu zápisu zkratek s koncovkou ve středověku a raném novověku a tedy naprosto odpovídá evropské typografické/pravopisné tradici. Jako příklad, kde se tento zápis ještě dochoval uvádím řadové číslovky v angličtině a na jejich příkladě ukazuji, jak tento způsob fungoval.
To, že je tento zápis v současných „pravidlech“ zakázán, považuju za důsledek působení puristických dementů v řadách kodifikátorů českého jazyka...
Petr Tomášek = nový Petr Tomeš?
BTW, ohánět se pravopisem anglických číslovek v zájmu obhajoby českého pravopisu odporujícímu normě, když jsou čeština i angličtina typologicky dost odlišné jazyky, je trochu mimo. V angličtině se to tak píše zejména proto, že nejsou na podobné gramatické jevy zvyklí (např. skloňování). Pro rodilého Čecha podobná věc naopak nepředstavuje většinou problém, zápis "bylo tam kolem deseti / 10 tisíc lidí" přečte bez obtíží stejně.
Takže angličani jsou pitomci, když píšou řadové číslovky jako 1st, 2nd, 3rd...?Nikoliv. Na rozdíl od Vás nemusí všichni někoho s jinou praxí nebo názorem hned považovat za pitomce, blba a tupce. (Mimochodem podezřívám, že angličtina a její vliv je za touto chybou českou notací.) Jednak je to notace pro řadové číslovky tradiční (jako naše tečka). Ani omylem to není ve všech případech koncovka (žádné tvoření slov: fir-st, seco-nd, thi-rd). A už vůbec ne skloňování, která angličtina dnes již prakticky nemá (s výjimkou osobních zájmen a předpokládám zbytky genitivu). Krom toho, struktura angličtiny vyžaduje pro srozumitelnost explicitnější vyjadřování, zatímco čeština se svým skloňováním a způsobem ohýbáním sloves si vesele vystačí bez vyjádřeného podmětu věty a potřebuje mnohem méně předložek. Jinými slovy. Srovnávání podobných jevů mezi velmi vzdáleně příbuznými jazyky prostě nefunguje. Skoro Vás podezřívám, že to víte, jenom jste to zkusil.
A lidé ve středověku a začátku novověku byli hlupáci, když takto (s „nápovědou“) psali zkratky?a) Tady nejde o zkratky, ale o číslovky. Mj. předpokládám, že zkratka ztrácí část své srozumitelnosti. Ve Vašem příkladě dokonce všechna zkrácená slova jsou v jistém tvaru a když tuto informaci ztratíte úplně, můžete ztratit/změnit i význam. Např. pokud by jako ve Vašem případě pro má slova existovaly standardizované zkratky samy o sobě nevyjadřující tvar: "Fr. pěst." by čtenáři vůbec neřeklo, jestli: "Frantova pěst," "Frantovi pěstí" nebo "Frantovou pěstí." b) Středověk? Tohle říká člověk, co tu horuje pro vývoj jazyka?
To jen ukazuje, že jsi naprosto nepochopil, jak tento způsob zápisu funguje.Ale pochopili. To jsou/byly pro dané jazyky zcela standardizované zápis. Ale Vám nějak uniká, že to není čeština. Nebo mám já začít vždy používat zájmeno pro vyjádření podmětu. Já jsi nejsem jistý, že to, co platí v jednom jazyce, tak my musíme to také tak dělat.
6.10.2009 11:36
xkucf03 | skóre: 50
| blog: xkucf03
Krom toho, psaní bez nabodeníček obvykle není na úkor srozumitelnosti
Člověk si to nakonec nějak domyslí, musí. Ale je to otravné a zdržující. Stejně tak bychom mohli říct, že nebudeme psát y/i, že nám stačí jedno „i“. Nebo zrušit v/u – ta písmenka vypadají skoro stejně, tak by se mohlo jedno zrušit a čtenář si to nějak domyslí – ostatně kdysi se psalo jen „v“. Nebo bychom mohli místo b/f/v psát jen jedno písmenko – vždyť stejně znějí stejně a čtenář si to nějak přebere, ne?
6.10.2009 12:21
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Aha, takže protože jsi líný si trochu namáhat mozeček, tak se snažíš najít způsoby, jak donutit ostatní, aby skákali podle tebe? Hm. 
6.10.2009 12:44
xkucf03 | skóre: 50
| blog: xkucf03
A když na tebe bude někdo mluvit strašně potichu, že mu sotva budeš rozumět, tak si budeš trochu namáhat ouška, nebo ho požádáš, aby mluvil trochu nahlas?
6.10.2009 12:45
xkucf03 | skóre: 50
| blog: xkucf03
A když na tebe bude někdo mluvit strašně potichu, že mu sotva budeš rozumět, tak si budeš trochu namáhat ouška, nebo ho požádáš, aby mluvil trochu víc nahlas?
6.10.2009 18:41
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Osobně se ale obávám, že moc ne. Já to taky občas střídám, podle toho, před čím sedím, protože ne na každém stroji (zejména v práci) jsem češtinu řešil nebo bych to byť jen považoval za smysluplné se tím zabývat.Jak se na počítači řeší čeština? Řekl bych, že zobrazovat české znaky umí všechny linuxové distribuce hned po instalaci už hodně dlouho, a česká klávesová mapa se nahrává jedním příkazem...
Ja bi som zrusil aj twrde i aj obycajne v a nahradil ho dwojitym w. o co lahsie bi sa zilo na svete.
6.10.2009 09:53
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Tvrde i by sy nahradil dvojtym w? Twjo, to bw bwl twjátr...
6.10.2009 18:38
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 18:41
xkucf03 | skóre: 50
| blog: xkucf03
Nejsi
Taky je pro mě QWERTZ normální.
 6.10.2009 20:17
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
6.10.2009 20:17
Marián Kyral | skóre: 29
| blog: Sem_Tam
| Frýdek-Místek
Taky se hlásím. Už mě nebavilo to neustálé přepínání...
 6.10.2009 06:17
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
6.10.2009 06:17
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
 6.10.2009 09:53
Shadow | skóre: 25
| blog: Brainstorm
6.10.2009 09:53
Shadow | skóre: 25
| blog: Brainstorm
 6.10.2009 11:38
unknown_ | skóre: 30
| blog: blog
. A co se tyka me, tak dokumenty nepisu, clanky bez hacku a carek, praci nemam, ve skole nepisu cesky.
6.10.2009 13:01
Shadow | skóre: 25
| blog: Brainstorm
6.10.2009 16:58
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
6.10.2009 19:04
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 19:13
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
6.10.2009 19:36
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 11:38
unknown_ | skóre: 30
| blog: blog
. A co se tyka me, tak dokumenty nepisu, clanky bez hacku a carek, praci nemam, ve skole nepisu cesky.
6.10.2009 13:01
Shadow | skóre: 25
| blog: Brainstorm
6.10.2009 16:58
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
6.10.2009 19:04
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 19:13
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
6.10.2009 19:36
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Jinak psanim opravdu nemyslim koukani na klavesnici a hledani pismenek, pripadne neustale prepinani.Já taky na klávesnici nehledám písmenka
.
Ohledne toho prizpevku, dokazes mi vysvetlit proc to tak je? Ja si to jinak nezapamatuju a budu to psat porad tak.Někdo to tak vymyslel... Prostě ne od zpívat
.
6.10.2009 19:38
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
Aaaha, takze zadny duvod k tomu neni, ale proste to tak je. Tenhle pristup je mi opravdu hrozne blizky.
6.10.2009 19:41
Jendа | skóre: 78
| blog: Jenda
| JO70FB
lidi, kteří píšou "cesky":
A) nechtějí psát "česky" ("cesky" je to rychlejší, pohodlnější...)
B) chtějí číst "cesky" (chtějí ceskou verzi webu)
imho je (A) správně
Presne tak. Napriklad ja pisu cesky protoze jsem na klavesnici tak zvykly a jde mi to rychleji. A protoze jsem v americke firme, v oficialni komunikaci to nijak nevadi.
6.10.2009 06:45
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Měl byste si zvyknout, že psaní bez diakritiky je prostě součást jazykového úzu v prostředí internetu. Jakákoliv snaha to omezit je směšná, hloupá a dementní. (A to jsem se omezil jen na tři přívlastky, pač je trojka hezké číslo ;-P)
6.10.2009 08:04
xkucf03 | skóre: 50
| blog: xkucf03
Měl byste si zvyknout, že psaní bez diakritiky je prostě součást jazykového úzu v prostředí internetu.
Právě že není – je to jen pocit některých ajťáků:
Jakákoliv snaha to omezit je směšná, hloupá a dementní.
Jaká snaha omezovat? Tohle měla být pomůcka pro lidi, kteří mají mizerný prohlížeč (který neumí české znaky), aby si mohli zobrazit verzi webu bez diakritiky. Co je na tom za omezování??
Vedlejším efektem by mohlo být, že by lidé psali více s diakritikou a všichni by si přišli na své – každý by četl s diakritikou nebo bez (použil by filtrovanou verzi webu), jak se to komu hodí. Jenže někteří lidé jsou bohužel tak bezohlední a líní, že by diakritiku nezačali používat ani potom, smutné no.
6.10.2009 09:19
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Měl byste si zvyknout, že psaní bez diakritiky je prostě součást jazykového úzu v prostředí internetu.Právě že není – je to jen pocit některých ajťáků:
- Psát bez diakritiky je pozůstatek z dob, kdy nám to technika nedovolovala – dnes nemá opodstatnění a je to jen zlozvyk.
- Úzus naštěstí je psát s diakritikou – většina webových stránek češtinu používá, všechny zpravodajské servery píší články a zprávy s diakritikou, i většina uživatelů si zvykla ji používat.
Ha! A kdo rozhoduje o tom, co je zlozvyk a co ne? (P.S. je zřejmé, že nemáte ani páru, co znamená slovo „úzus“; vřele doporučuji nahlédnout do slovníku cizích slov...)
6.10.2009 10:42
xkucf03 | skóre: 50
| blog: xkucf03
Např. podle Wikipedie je úzus „pravidlo či ustálený zvyk, který není povinný, psaný, ale všeobecně přijímaný a respektovaný.“
Všeobecně přijímané je, že součástí češtiny jsou háčky a čárky, a to bez ohledu na to, jestli se píše na papír nebo do počátače – všechny noviny, ať papírové nebo internetové diakritiku používají, neznám firmu, která by se na internetu prezentovala webem psaným cestinou (bez diakritiky) a také většina uživatelů také přirozeně píše česky nikoli cesky.
Vedle toho je tu pár sobců, kteří si zvyli psát bez diakritiky, ale to není úzus, není to všeobecné pravidlo – normální je psát s diakritikou.
P.S. od jazykoveho puristy bych cekal min preklepu
6.10.2009 10:58
xkucf03 | skóre: 50
| blog: xkucf03
Všeobecně != všichni.
Taky je všeobecně přijímané, že se nemá krást a přesto se najde pár lidí kteří kradou.
6.10.2009 11:33
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Nikdo. O tom se maximálně tak můžeme hádat, to je vše
6.10.2009 13:10
xkucf03 | skóre: 50
| blog: xkucf03
Jestliže se s diakritikou píší internetové noviny, webové prezentace firem, stránky organizací a státních institucí, odborné články, diplomky, bakalářky, populární články, většina blogů a velká část komentářů… tak si troufám tvrdit, že normální je psát s diakritikou a to i v prostředí internetu. (aby bylo normální psát bez ní, muselo by to být naopak)
Obecně k téhle diskusi: docela mě udivuje, jak daleko jsou někteří lidé schopní zajít při obhajování vlastních zlozvyků a lenosti.
Nikdo netvrdi, ze neni normalni psat s diakritikou. Ale jaksi neni normalni tvrdit, ze se MUSI psat JEN s diakritikou.
A vubec, mysli, ze jsem cizinec (coz je z pulky pravda) a mas to...
6.10.2009 13:51
xkucf03 | skóre: 50
| blog: xkucf03
Tak aspoň že se shodneme na tom, že normální (a úzus) je psát s diakritikou
Stejne jako psani bez diakritiky (na netu)
6.10.2009 19:17
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Ne, většina českých textů na webu je česky.
To jaksi nevyvraci, co jsem rekl.
A co motivuje lidi k tomu, aby psali bez diakritiky?
Fakt je to nutne opakovat? Pro me je to vyssi efektivita psani.
Jo a ano, text bez diakritiky čtu pomaleji. Delší si dokonce nechám ohákovat, i když to není 100%.
To je IMHO tak proto, ze pises s diakritikou. Kdybys psal bez ni, cetlo by se ti to ze zvyku snadnejc :D
6.10.2009 19:43
Jendа | skóre: 78
| blog: Jenda
| JO70FB
To jaksi nevyvraci, co jsem rekl.Franta: normální (a úzus) je psát s diakritikou Ty: Stejne jako psani bez diakritiky (na netu) [je normální a úzus] Já vyvracím, že psaní bez diakritiky "na netu" je normální a úzus.
Jak to ale vyvracis? Samotny fakt, ze text s diakritikou prevazuje, nic nedokazuje.
7.10.2009 15:26
Jendа | skóre: 78
| blog: Jenda
| JO70FB
Prestoze definic "normalnosti" je vic, ta tvoje mezi ne urcite nepatri.
Vezmeme si nedavne irske referendum. Chces rict, ze lidi hlasujici za "NE" udelali neco nenormalniho jen proto, ze se nakonec ukazali byt v mensine?
Jen upresnim, ze definici normalnosti urcite neni to, co dela prosta vetsina.
Vezmeme si nedavne irske referendum. Chces rict, ze lidi hlasujici za "NE" udelali neco nenormalniho jen proto, ze se nakonec ukazali byt v mensine?Ano, ještě nějaké otázky? (Koukám, že se nám ta LS vetře všude.)
6.10.2009 11:31
Petr Tomášek | skóre: 39
| blog: Vejšplechty
P.S. od jazykoveho puristy bych cekal min preklepu
Já ne. Většina lidí, co ostatním vnucují svůj názor ohledně „pravopisu“ a podobných píčovin, toho o jazyce mnoho neví. Naopak u lidí v jazykových záležitostech vzdělaných se spíš setkávám s určitou „pokorou“: bohemistu většinou poznám tak, že mě neopravuje, ale naopak řekne něco jako: „to je zajímavé, že říkáte XYZ... vy jste z ABC, že ano...“
6.10.2009 11:05
Petr Tomášek | skóre: 39
| blog: Vejšplechty
To, že se to zrovna tobě nelíbí, ještě neznamená, že to úzus není.
6.10.2009 11:08
xkucf03 | skóre: 50
| blog: xkucf03
Takže úzus je psát bez diakritiky? Proč, když většina textů v češtině je psána s ní?
6.10.2009 11:15
Petr Tomášek | skóre: 39
| blog: Vejšplechty
6.10.2009 10:48
xkucf03 | skóre: 50
| blog: xkucf03
V takovém případě máš ty nebo odesílatel rozbitého e-mailového klienta nebo dochází k chybě poštovního serveru – každopádně někdo něco dělá blbě, ale posílat maily s diakritikou v principu není problém ty technologie a kódování jsou běžně dostupné a používají se. Znamená to, že bys měl chybu opravit – ne přestat používat diakritiku.
6.10.2009 19:11
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 19:16
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
6.10.2009 19:16
unknown_ | skóre: 30
| blog: blog
Napsal jsem v javě Filtr (javax.servlet.Filter), který diakritiku odstraňuje. Pokud neznáte Javu a servlety, filtr si prostě představte jako unixovou rouru, kterou se proženou na serveru všechny stránky před tím, než se odešlou klientovi.To jsem úplně nepochopil, kam si takový filtr mám nainstalovat... IMO neschopnost zobrazit víc než ascii (latin1) lze celkem pohodlně řešit modulem do apache a/nebo na straně klienta (lynx, links, recode...). A navíc to nesouvisí s tím, proč lidi píšou bez diakritiky.
6.10.2009 07:44
xkucf03 | skóre: 50
| blog: xkucf03
kam si takový filtr mám nainstalovat
Ty nikam – takový filtr patří na server nebo na proxy server:
…jako unixovou rouru, kterou se proženou na serveru všechny stránky…
Jelikož je Ábíčko psané v javě, má smysl i ten filtr psát v javě a ne jako modul do Apache (BTW: ten se jmenuje jak?). Na straně klienta je to nesmysl, protože to vyžaduje nějakou zvláštní aktivitu od uživatele – a dost často je nemožná, např. do PSP bych si takový filtr nemohl nainstalovat, nebo by bylo jednodušší tam dostat české fonty.
Na straně klienta je to nesmysl, protože to vyžaduje nějakou zvláštní aktivitu od uživatele – a dost často je nemožná, např. do PSP bych si takový filtr nemohl nainstalovat, nebo by bylo jednodušší tam dostat české fonty.Na straně klienta to právě je smysl, protože nemůžu nutit celý internet, aby si instaloval
%s, jen proto, že mám prohlížeč, který neumí %s.
Na straně klienta je to většinou nemožné. Navíc klientů je mnohem víc než serverů. Rozumným kompromisem může být nasazení takového filtru na proxy – ostatně tak vzniknul i ten obrázek odháčkovaného Ábíčka – nemám vlastní instanci Ábíčka, udělal jsem webovou aplikaci, která dělá reverzní proxy Ábíčku a k této aplikaci přiřadil ten filtr, který odstraní háčky a čárky – takže to může fungovat pro libovolný web.
Web se dá prohlížet na lecšems a zdaleka ne všude si můžeš nainstalovat lynx. Souhlasím, že dnešní klienti by měli být schopní interpretovat weby s unicodem a pokud nemají fonty, tak je aspoň převést na to, co umí. Ale svět není ideální, takže se někdy hledají náhradní řešení – jedním z nich je třeba proxy, která by odstraňovala diakritiku – ono je totiž o dost jednodušší, zadat jiné URL než někam instalovat lynx nebo jiná písma – zvlášť když je člověk u toho zařízení jen na chvilku nebo mu ani nepatří.
Jedním z hlavních argumentů cestinaru (lidé kteří zásadně píší bez diakritiky) je, že čtenář může mít nějaké obskurní zařízení, na kterém si nepřečte české znakyJa mám skôr dojem, že používanie diakritiky zhoršuje šance pri vyhľadávaní (a vlastne skloňovanie a časovanie tiež
). Z toho hľadiska je vhodné vybrať si jednu variantu a držať sa jej. Čo sa ale nedá, ak web tvoria stovky ľudí.
Nájde vyhľadávanie na abíčku text napísaný bez diakritiky ak kľúčové slovo napíšem s diakritikou alebo naopak?
Text s doplněnou diakritikou: pica velkohubá
6.10.2009 09:59
Shadow | skóre: 25
| blog: Brainstorm
jj, to by bylo fajn. Ale: jsou od toho zdrojáky, nebo by se to muselo napsat znova?
 6.10.2009 09:14
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
6.10.2009 09:14
=^..^= AmigaPower® | skóre: 30
| blog: BLB
| Praha
A nobolo bi lepsie napisat nieco co bi tu diakritiku a zbitocne tvrde i odoberalo?
6.10.2009 10:39
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Jdes na to spatnym smerem. Neni problem s fonty, to by si neprecetli ani clanky. Problem je bud v tom, ze zarizeni nema dostupnou ceskou klavesnici (zkuste v egyptske internetove kavarne psat česky) nebo je tak zvyknuty. V obou pripadech mas smulu a nejsi schopen to resit, automaticke ohackovani nebude 100% spolehlive bez AI.
6.10.2009 13:03
xkucf03 | skóre: 50
| blog: xkucf03
Pokud uživatel nemůže psát česky, tak se nedá nic dělat. Šlo mi spíš o to, že když jsme se tu v nějakém flamu hádali zda psát či nepsat s diakritikou, někteří tu argumentovali tím, že se text bez diakritiky lépe čte na zařízeních, které češtinu nepodporují (resp. vůbec se na nich dá číst narozdíl od textu plného otazníků nezbo zmršených znaků). A přestože jsem se jim snažil vysvětlit, že ten chudák s hloupým zařízením si nepřečte ani blogy a články, tudíž ho cesky psané komentáře nevytrhnou, mleli pořád dokola tu svou. Takže jsem chtěl vyvrátit tenhle „argument“ pro psaní bez diakritiky
I podle ankety se ale ukazuje, že o verzi bez diakritiky nemá zájem téměř nikdo. Tím tedy padá důvod nepsat háčky a čárky v komentářích.
Tím padá _tento_ důvod, ale nepadají důvody ostatní. Osobně kvituji vaši snahu, která může aspoň demaskovat krycí důvod pro používání cestiny, ale odhaduju, že díky vašemu nápadu víc lidí psát česky nezačne.
 6.10.2009 16:02
Cubic | skóre: 24
| blog: obcasne_vyplody
| Essex
6.10.2009 16:02
Cubic | skóre: 24
| blog: obcasne_vyplody
| Essex
Asi tak. Prestoze nevysedavam v egyptske internetove kavarne, stejne nemame v baraku jedinou klavesnici s ceskou znakovou sadou. I kdyz mame vsechny pocitace schopne zobrazovat/psat cesky je psani s diakritikou podstatne namahavejsi, protoze vetsinu textu tvorim v anglictine a clovek to rozmisteni na prvni rade klaves pozapomene. Na ceske rozlozeni prepinam jen kdyz opravdu potrebuji, aby si muj zapisek(treba tady v poradne) precetli lide, kterym vadi absence diakritiky tak, ze bez ni by se mohli me zadosti o radu proste vyhnout.
Jen tak mimochodem ted jsem zjistil ze firefox zahrnuje kontrolu pravopisu i u textu bez hacku a carek... parada.lepší by bylo filtrovat proud dat – jenže to není úplně triviální, pokud se používá vícebajtové kódování (UTF-8)
Cože? S UTF-8 je třeba držet stav jen po dobu jednoho znaku, kódování je to samosynchronizační. UTF-8 naopak umožňuje zpracování v proudech. Navíc pokud si jste jistý vstupem, tak nemusíte řešit synchronizaci po chybné sekvenci bajtů.
6.10.2009 11:17
xkucf03 | skóre: 50
| blog: xkucf03
jj, je to složitější. Odstranit háčky a čárky, když pracuji s textovou proměnnou je záležitost na jeden řádek kódu. A to bez ohledu na kódování (protože jakmile ty data dostanu do textové proměnné (String) už kódování nemusím řešit – řeším ho jen při převodu z bajtů a na bajty).
Chtěl bych zpracovávat data proudově a tak, abych nebyl vázaný na konkrétní kódování, aby to nebylo jen pro UTF-8 data, ale univerzální, parametrizovatelné, obecně funkční pro jakékoli kódování – a to už triviální není. Musel bych implementovat jak UTF-8 (zpracování vícebajtových znaků), ale i další kódování.
bez ohledu na kódování
Pokud jsem dobře pochopil váš kód, tak záměrně používáte UTF-8, protože využíváte jeho jednu normální formu, která diakritické znaky rozkládá do samostatných kódových pozic a pak jednoduše z takovéhoto proudu vyházíte vše, co je mimo množinu ASCII (třeba výpustku nebo české uvozovky). Takže asi ohled na kódování brát musíte.
abych nebyl vázaný na konkrétní kódování
Na to existují knihovny (iconv) a nástroje (echo "„Šílěně žluťoučký…“" | recode ..bs), které mají převodní tabulky, ale kdo chce javu, pomožme mu tam. Neumí to ICU?
6.10.2009 13:33
xkucf03 | skóre: 50
| blog: xkucf03
Vstup může přijít v jakémkoli kódování, přichází jako proud bajtů a výstupem je taky proud bajtů. Ten proud převedu na pole bajtů a na text (String) si ho převádím pomocí String text = new String(poleBajtů, kódování); Ten String je už prostě jen pole (vnitřně) unicodových znaků – jejich vnitřní kódování ale neřeším (UTF-8), pracuje se prostě už na vyšší úrovni, ne už s bajty.
Řešením by bylo asi leda převést ten proud bajtů v nějakém (libovolném) kódování na proud znaků (rozkódovat) a pak ho zase zakódovat do UTF-8 do jiného proudu bajtů a bajt po bajtu je brát a osekávat z nich diakritiku a pak to poslat do výstupního proudu. Jednoduše je to řádově složetější než to současné řešení na jeden řádek (resp. na tři i s převodem z bajtů a zpět na ně).
Houbelec prostě už na vyšší úrovni
, vy jednoduše využíváte toho, že surrogate pairs jsou vlastností UTF-16/UCS-2, který java interně používá. Kdyby třída String nebyla v UCS, tak žádný balík java.text.normalizer nebude existovat, respektive výstupem Normalizer.normalize() nebude objekt typu String, ale hypotetického typu TotoJeŘetězecVUnicodu.
Mimochodem, jak se váš jednořádkový převod vypořádává s nepísmennými znaky (uvozovky)?
Kdybyste skutečně pracoval se znaky bez ohledu na interní reprezentaci, tak by regulární výraz \p{ASCII} nepotřeboval předzpracování Normalizerem.
6.10.2009 13:21
xkucf03 | skóre: 50
| blog: xkucf03
Uz asi sedm let jsem zvykly na pouzivani anglicke klavesnice. Ceskou proste nepotrebuju.
Takže až budeš mluvit s někým, kdo při mluvení na druhé prská, tak mu taky nic neřekneš, prostě budeš respektovat jeho zvyk On přece nepotřebuje přestat prskat na lidi, jemu to nevadí
Je samozrejme urcita mez, od kdy uz je upozornit na zlozvyk politicky korektni. Ale asi by to, co rikate, nebylo tak uplne jednoznacne, kdyz by mel ten dotycny treba recovou vadu. Navic, ja ve formalnich dokumentech cesky psat budu, ale je to nesikovne. V diskusi na internetu to delat nemusim. Podobne jako vy do formalniho dokumentu smajlik nenapisete, ale v diskusi ano.
6.10.2009 16:35
xkucf03 | skóre: 50
| blog: xkucf03
Ale asi by to, co rikate, nebylo tak uplne jednoznacne, kdyz by mel ten dotycny treba recovou vadu.
řečové vadě by odpovídal počítač neschopný psát s diakritikou (rozložení klávesnice…), ale většinou to není nějaká nepřekonatelná vada – uživatel může psát česky, ale jen se mu nechce (lenost, pocit, že je to pomalé).
Podobne jako vy do formalniho dokumentu smajlik nenapisete, ale v diskusi ano.
Smaljlíky zvyšují informační hodnotu, chybějící diakritika ji naopak snižuje.
Chybejici diakritika snizuje informacni hodnotu jen v malem procentu pripadu. Temto se navic da vyhnout, popr. obejit.
Jinak, chybejici diakritika ve velke vetsine pripadu zvysuje informacni hustotu, naopak diakritika zvysuje informacni redundanci.
To je hezké, ale prohnat text GZipem taky zvyšuje informačnčí hustotu a snižuje informační redundanci a přesto texty určené ke čtení člověkem neGZipujeme.
informační redundance je v mezilidské komunikaci do značné míry žádoucí.Spíše v mluvené (aby to adresát při poslechu pobral), než v psané (kterou může louskat pořád dokola).
I text bez diakritiky se samozřejmě dá číst – já bych tvrdil, že bez velkých problémů –, ale ztrácí se tím trochu ta samoopravná schopnost, no.
Co je pro jednoho lenost je pro druheho racionalni rozhodnuti. Proc se vy nenaucite Common Lisp misto Javy, hm? :-)
7.10.2009 08:23
xkucf03 | skóre: 50
| blog: xkucf03
Protože zatím racionálně docházím k tomu, že se mi to nevyplatí – CL by mi taky něco přinesl, ale náklady na jeho učení by byly asi vyšší a líp se uživím v Javě, ale hlavně tím, že neumím CL nikoho neobtěžuji.
Jasně, že pro někoho může být pohodlnější psát bez diakritiky, nemusí si nic nastavovat (pokud má nějaký starý nebo divný OS, kteřý češtinu v základu neumí) nebo píše rychleji*. Jenže co je pro jednoho (autora) úspora, je pro mnohé (čtenáře) dodatečná práce (musejí si tam ty háčky a čárky domýšlet, čtou pomaleji). Jeden si ušetří čas, ale na úkor ostatních. Z čistě sobeckého hlediska možná racionální, ale podle mého ne správné, neslušné.
Vedle toho to, že neumím CL za neslušnost nepovažuji.
*) ne že by psaní bez diaritiky bylo rychlejší (sekretářka píše několikrát rychleji než on a s diakritikou), ale on se naučil bez ní a nechce se mu přeučovat.
7.10.2009 12:39
xkucf03 | skóre: 50
| blog: xkucf03
Tím jsem chtěl říct, že obecně diakritika nemá vliv na rychlost psaní -- pokud už někdo rychle psát umí (všema deseti), tak píše s diakritikou a ostatní jsou daleko za ním, bez ohledu na to zda diakritiku používají nebo ne.
IMHO to tak neni. S diakritikou pisu hodne (vlastne vsechno krome IM a diskusi) a rychlost psani je vskutku prakticky stejna. Co ale stejne neni je mira chyb. Znaky s diakritikou jsou na klavesnici dal, prsty se musi natahovat dal a to IMHO zvysuje chybovost.
Jinak, je otazka, zda fakt, ze se ti text bez diakritiky cte pomaleji neni tvuj osobni problem. Mne to (az na dvojznacne pripady) problemy vubec nedela a zadne zpomaleni nepocituju.
A kdyz nekdo pise na ceskem webu slovensky? To vam nevadi?
Taková slangová nebo zkomolená slovenština bez diakritiky je opravdu silnější káva, někdy je dost problém to vůbec přelouskat. Ale normální spisovná/hovorová slovenština s diakritikou mi nevadí. Aspoň si procvičím nějaká jejich slovíčka, což se může hodit (i když číst slovenštinu dá víc práce než češtinu -- Čechovi, většinou). Oproti tomu číst text bez diakritiky je tak akorát otravné.
A kdyz nekdo pise na ceskem webu slovensky? To vam nevadi?Ne.
Druhym hlavnim a mozna nejhlavnejsim argumentem cestinaru je, ze sedi u kompu, na kterem se s hacky a carkami psat neda. Jestli autor zna nejaky pouzitetelny zpusob, jak psat cesky napriklad z internetove kavarny v Londyne, sem s nim.
6.10.2009 12:23
Petr Tomášek | skóre: 39
| blog: Vejšplechty
kopírovat písmenko po písmenku z nějaké jiné české stránky?
V internetove kavarne v londyne asi ceske rozlozeni nebude a nainstalovat nepujde ...
Opravdu to lze říci takto kategoricky? UNIX – s XFree86/Xorg se dodávají všechny mapy, nastavení je otázka setxmbmap; Mac OS X – tam se prý lokalizace kupuje zvlášť, jestli to zahrnuje i klávesové mapy, nevím; DOS – nemá řízení přístupu; Windows – od Vist se instalují všechny mapy, nižší NT verze, pokud jsou zabezpečené, mohou být problém, 9x verze nemají řízení přístupu.
Takže jediným problémem jsou dvě verze Windows, které ale musí být dostatečně zabezpečeny. Navíc se vždy lze zeptat obsluhy.
No ja vychazim ze sve zkusenosti ... zatim jsem videl pouze WinXP a tam to fakt neslo.
6.10.2009 19:31
Jendа | skóre: 78
| blog: Jenda
| JO70FB
6.10.2009 12:51
xkucf03 | skóre: 50
| blog: xkucf03
Tenhle argument samozřemě beru -- pokud ti to technické prostředky neumožňují, tak piš normálně bez diakritiky, nikdo se nad tím pohoršovat nebude. Pokud jde tedy o komentáře nebo nějaké méně podstatné věci -- pokud bych psal např. článek, tak bych si tu čekou klávesnici sehnal.
Napadá mě leda něco na způsob editoru na způsob T9 -- akorát by základními znaky nebyla čísla 0-9, ale znaky a-Z a editor by ti napovádal různé znaky s háčky a čárkami na všech možných místech (např. podle slovníku). Ale nic takového jsem na počítači ještě neviděl.
Nezbavíme.
Řekl bych, že drtivá většina píše cesky nikoli proto, že by měli starost o ty chudáky čtenáře s "obskurním zařízením", ale typicky z těchto důvodů:
a) začali psát tehdy, kdy s diakritikou skutečně byl problém (a nemají zájem se tyto novoty naučit)
b) myslí si (nebo to aspoň říkají), že psaní s diakritikou je pomalejší než bez ní
c) jednoduše na to kašlou
d) nechápou, co to diakritika vůbec je
A zbytek uzivatelu zrovna píše "z Ulánbátaru z manželčina počítače, kde se právě porouchalo přepínání mezi klávesnicemi"...
 6.10.2009 14:27
microcz | skóre: 18
| blog: Michalův zápisník
| Praha
6.10.2009 14:27
microcz | skóre: 18
| blog: Michalův zápisník
| Praha
+1 ...souhlas, pro psani s kamaradem nebo do diskuze pisu zasadne bez diakritiky (duvodem je bod b) pro formalni korespodenci samozrejme s diaktritikou...posledni dobou se u me objevuje jev kdy bezmyslenkovite prechazim mezi psaním s diakritikou a bez :o)))
6.10.2009 15:09
Shadow | skóre: 25
| blog: Brainstorm
6.10.2009 17:00
vlastikroot | skóre: 24
| blog: vlastikovo
| Milevsko
 6.10.2009 17:06
Limoto | skóre: 32
| blog: Limotův blog
6.10.2009 17:06
Limoto | skóre: 32
| blog: Limotův blog
Zbavíme se na ábíčku už konečně anonymních kreténů?
6.10.2009 19:36
Petr Tomášek | skóre: 39
| blog: Vejšplechty
Anonymní kretén, nebo agent s teplou vodou (čti: diakritikou): jaký je v tom rozdíl?
 6.10.2009 18:19
Amarok | skóre: 33
| blog: blogoblog
6.10.2009 18:19
Amarok | skóre: 33
| blog: blogoblog
ohýbání standardů tam tou velkou firmou s tím malým měkkým v názvu bývá linuxáky obvykle dost tvrdě kritizováno. Ale pokud jde o češtinu tak někteří klidně dělají totéž. Co jiného je ignorování diakritiky než ohýbání standardu? Co je to za přístup k partnerům v diskusi? "Mě to takhle vyhovuje a že se to vám blbě čte mě vůbec nezajímá". Taky se občas uklepnu, udělám pravopisnou chybu, neomylný nejsem ale nepíšu blbě z lenosti a pohodlnosti. Pipomíná mi to debaty o kouření nebo o cyklistech. Kuřáci se domáhají práva škodit ostatním, militantní pumpičkáři dělají propagační (nátlakové) akce na kterých porušují všechna možná pravidla silničního provozu. To jste taky takoví? Blbne mi písmeno ř, mohl bych psat cesky bez hacku a carek ale hnusí se mi to. A podobně nemám rád to populární zkratkování, různé ty LOL, ROFL a další.
Aha, takze mluvit nebo psat narecim je vlastne take ohybani standardu a melo by byt vymyceno.
Je obrovsky rozdil mezi dodrzovanim standardu v klicovych, verejnych aplikacich u kterych je potreba velka interoperabilita a treba vnitrofiremnich systemech. Stejne tak je rozdil mezi tim, kdyz nekdo pise bez diakritiky/mluvi narecim doma, v diskusi nebo ve zpravodajstvi verejnopravni televize a oficialnich dokumentech.
mluvit nářečím není ohýbání standardu, nářečí je takovým standardem! Samozřejmě v daném regionu či kulturním prostředí, pro oficiální použití je standardem spisovný jazyk. Pokud tedy budu bezháčkovitost považovat za formu nářečí, bude přijatelné používat to v prostředí kde je to nutné a obvyklé. Pokud ale hodlám komunikovat s širokou veřejností tak použiju spisovný jazyk se vším co k němu patří. Samozejmě pokud mi v tom nebrání závažné důvody které se tady už probíraly. Když budu psát se svého starého Palma tak to prostě s diakritikou nebude. Nebo když je někdo služebně v Ulánbátáru nebo píše z pracovního počítače který nesmí nijak modifikovat. Ale zdůvodnit to pohodlností?
Nareci nemaji zadnou kodifikovanou podobu a tedy ani standard.
Pokud tedy budu bezháčkovitost považovat za formu nářečí, bude přijatelné používat to v prostředí kde je to nutné a obvyklé.
Nutne to samozrejme neni, stejne jako neni nutne pouzivat nareci. Prectete si ale diskusni prispevky tu na abclinuxu (popr. jinde) a zjistite, ze psani diskusnich prispevku je skutecne obvykle.
7.10.2009 20:53
Amarok | skóre: 33
| blog: blogoblog
Pokud ale hodlám komunikovat s širokou veřejností tak použiju spisovný jazyk se vším co k němu patří.To byste taky mohl rovnou zacit diskriminovat lidi, co nepisi spisovnou cestinou a nebo delaji gramaticke chyby - nebo pouzivaji zkratky typu IMHO (coz uz tady nekdo v diskuzi taky kritizoval). To proste do sveta www diskuzi vse patri a tuplem v diskuznim foru silne zamerenem na technickou stranku pocitacovych systemu. Fakt nechapu duvod, proc vubec o tomhle muze nekdo zacit debatu a stezovat si.
gramatické chyby tam asi mám, neomylný nejsem ale nedělám je úmyslně a z lenosti. Nespisovný jazyk nemusí být nutně špatný, někdy může posloužit třeba k výstižnému vyjádření pocitů a podobně. Já vím že je to boj s větrnými mlýny ale co zkusit ten internet dělat jinak? Proč upadat na úroveň debilů z Novinky.cz? Proč použít debilní zkratku když můžu napsat "hele kámo, rozesmál jsi mě tak že budu muset vylít čaj z klávesnice a utřít poprskanej monitor". Já vím, ostravaci říkají "bo neni čas pičo". Když není čas tak nevysedávám u diskusí a když chci diskutovat tak si čas najdu.
8.10.2009 07:59
Amarok | skóre: 33
| blog: blogoblog
A není pak jednodušší psát všude s diakritikou než se takhle pořád přepínat?
Při programování používám českou QWERTZ, zvláštní znaky mám pod Altem a rozložení klávesnice jsem si mírně přemapoval (ale to je spíš kvůli „typografii“ než programování).
Mozna je to jednodussi, ale prvni do toho musis investovat cas a naucit se to ... krom toho mi teda prislo, ze s ceskou klavesnici se nektere specialni znaky pisi dost krkolomne.
Krom toho ma psani bez diakritiky tu vyhodu, ze je to prakticky "nejmensi spolecna mnozina", kterou clovek najde na skoro vsech rozlozenich klavesnice (vcera jsem potreboval napsat par slov na pocitaci kamaradky, ktera je madarka. Fakt se mi nechtelo resit pro tech par slov rozlozeni klavesnice).
ale to je spíš kvůli „typografii“ než programováníJé, a je ta keymapa někde dostupná? Že bych se „inspiroval“
.
je, cat /usr/share/X11/xkb/symbols/cz
Jsou tam české uvozovky „dvojité“ a ‚jednoduché‘ a trojtečka …, pomlčka – abych nemusel psát --
Alt + Shift + f, g, h, j, .; Alt + -
Pak tu ještě někdo o nějaké blogoval, ale můžeš si udělat vlastní, nasázet si tam znaky, které používáš
Ještě dost používám → (Alt+i), ale to je myslím v základu. Alt+z = ←, Alt+u = ↓, Alt+Shift+u = ↑ '
sorry, zapomněl jsem to nejdůležitější, přiložit ten svůj soubor
clear lock keycode 0x42 = bar backslash keycode 0x30 = backslash exclam NoSymbol NoSymbol apostrophe ssharp keycode 46 = l L NoSymbol NoSymbol Lstroke section keycode 0xb = ecaron Ecaron NoSymbol NoSymbol at dead_caron keycode 0xc = scaron Scaron NoSymbol NoSymbol numbersign dead_circumflex keycode 0xd = ccaron Ccaron NoSymbol NoSymbol dollar dead_breve keycode 0xe = rcaron Rcaron NoSymbol NoSymbol percent dead_abovering keycode 0xf = zcaron Zcaron NoSymbol NoSymbol asciicircum dead_ogonek keycode 0x10 = yacute Yacute NoSymbol NoSymbol ampersand dead_grave keycode 0x11 = aacute Aacute NoSymbol NoSymbol asterisk dead_abovedot keycode 0x12 = iacute Iacute NoSymbol NoSymbol braceleft dead_acute keycode 0x13 = eacute Eacute NoSymbol NoSymbol braceright dead_doubleacute keycode 25 = w W NoSymbol NoSymbol Greek_mu keycode 77 = Num_Lock trademark keycode 51 = doublelowquotemark leftdoublequotemark NoSymbol NoSymbol endash
 AbcLinuxu.cz
AbcLinuxu.cz ITBiz.cz
ITBiz.cz HDmag.cz
HDmag.cz AbcPráce.cz
AbcPráce.cz

